如何让ChatGPT接入互联网?
一、前言
使用谷歌搜索引擎实现的最终效果:
搜索引擎一次返回10条搜索结果数据
每条数据标题都带有链接地址,点击可跳转到对应网页;
标题之后的内容为LLM模型根据原始网页内容整理之后输出的内容
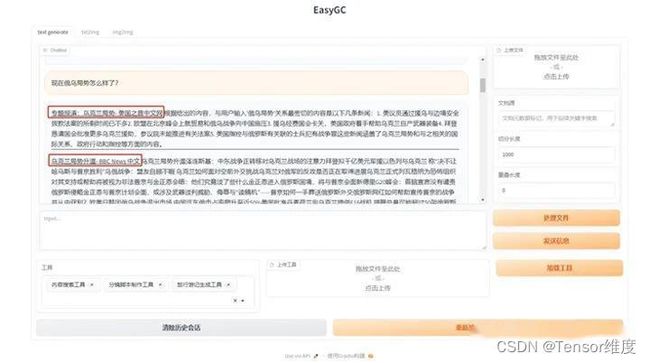 搜索引擎搜索出的内容让ChatGPT整理后返回到Chatbot上
搜索引擎搜索出的内容让ChatGPT整理后返回到Chatbot上
上述应用开源地址:
https://github.com/hubo0417/EasyGC
1、背景
前段时间自己基于LangChain+ChatGLM2-6B+SDXL开发了一套AIGC应用(请参见我上一篇文章),既然是AIGC应用,那么目的自然是希望使用AI作为工具,高效地为我生产“图文",“文章”,“短视频”等内容。主要方向是文学鉴赏类短视频,旅行介绍图文,其他方向的文章(暂没限定)。
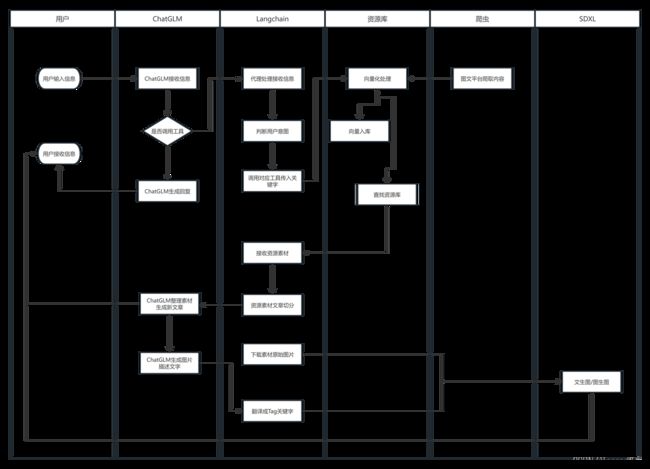 AIGC应用的整体思路流程
AIGC应用的整体思路流程
可想象是美好的,现实是骨感的,整个应用在成果质量上还是很差强人意,需要人工去做很多修改工作。
2、问题分析
整个应用的核心问题主要有两方面
第一:语言大模型上。生成的内容质量,不好评价...
第二:资源库原始数据太少(资源库的数据一是靠人工整理录入,二是爬虫爬取录入(每个爬虫几乎只能针对单一站点进行爬取,因为每个网站的HTML构造都不相同))
2、实现目标
需求很简单
1)提高内容生成质量
2)减少人工工作量
基于上述两个需求,要满足第一个需求,最直接的方法就是换更好质量的模型,ChatGPT当然是首选(虽然要付费调用,但是性价比高,不折腾);要满足第二个需求,最直接的方法就是让大模型接入互联网,开发一个搜索工具,搜索工具的思路:
1)用户输入需要搜索的内容信息,
2)大模型判断出需要使用“内容搜索工具”
3)“内容搜索工具”使用谷歌的接口,在互联网上搜索出相关内容
4)“内容搜索工具”循环搜索出的内容链接,获取每一个链接背后的具体数据
5)“内容搜索工具”将具体内容,使用最暴力的手段清除掉HTML,javascript,css等标记内容,只保留文本(不像爬虫一样,需要针对特有HTML结构进行解析,就是暴力清除)
6)语言大模型将保留下来的文本内容与用户输入的内容进行对比,进一步清除掉不相关的内容(通常网页的内容会有很多广告,推荐等非主题内容的文本)(这是重点,借助大模型的能力判断出哪些是有价值的内容,哪些是无关内容)
7)将清除的后内容和原始链接返回到客户端/存入向量数据库
这样一来,人工的维护量降低了,而且使用越多,数据资源就越丰富,是一个良性的循环
二、环境准备
1、Azure OpenAI使用申请
申请 Azure OpenAI 需要如下几个前提
1)一张国际信用卡,比如 VISA,MasterCard,国内很多银行都提供这些国际币种信用卡
2)需要一个备案过的域名网站,我试用的是我们公司的官网,因为在国内网站域名备案这种事,限制还挺多
3)需要跟域名一致的企业邮箱,我使用的也是我们公司的企业邮箱
这些前提条件都准备好了之后,就可以开始申请Azure OpenAI服务了
具体申请教程可参照官方文档
挺简单的,审核也很快当前就能收到申请成功的邮件,这里就不详细讲解怎么申请了
2、Google搜索引擎接口申请
1)注册一个谷歌账号
2)自定义搜索引擎创建
整个环境准备好了之后会得到4个参数,这4个参数需要配置到程序中,用于接口访问的鉴权,4个参数分别是:
Azure:
azure_key:xxxxxx (接口请求的鉴权key)
azure_endpoint:xxxx (接口请求的终结点)
google:
key:xxxx (接口请求的鉴权key)
ID:xxxxxx (自定义搜索引擎ID)