Reading papers_11(读Integrating local action elements for action analysis相关文章)
- 读Thi, T. H., L. Cheng, et al. (2010). Implicit motion-shape model: a generic approach for action matching, IEEE.
本文作者是通过对连续的视频帧来构造一个MHI图像,然后把MHI图像分成若干个运动——形状区域(即Motion-Shape regions),其实也就是对MHI图像进行特征点检测,这样一个动作视频就被一些稀疏的3维时空特征块表示了。接着作者将这些这些特征块整合到一个3维的ISM模型中,然后检测过程用广义的Hough变换对该模型进行投影,最后采用的是meanshift算法找到投影空间密度最大的区域,计算出其匹配得分。
2. 读Thi, T. H., L. Cheng, et al. (2010). Weakly supervised action recognition using implicit shape models.
本文中作者主要是采用了一种弱监督学习的方法将检测到视频的时空特征点的一些噪声点滤掉了。所以作者的方法不依赖复杂的背景减图来去掉背景噪声。首先采用STIP检测视频的时空特征点,以检测到的特征点为中心,用基于这些STIP的中间尺度和频率来决定其周围的像素点是否也包含进去(没实质理解其意思),然后用HOG+HOF串联描述。
检测到的特征块送入稀疏贝叶斯SBFC分类器中进行过滤噪声,该SBFC需要学习2个参数,对每个动作的2个参数学习好了后,当有新的视频来临时,且经过特征点检测后,就用对这些参数进行积分来决定该特征点是否属于对应人体行为上的特征点。
最后也是和上面的文章一样,扩展一个3D的ISM,构造一个投票空间,然后采用广义的hough变换进行投影,最后用3Dmeanshift算法进行搜索密度最大的区域。
3.读Thi, T. H., L. Cheng, et al. (2011). "Integrating local action elements for action analysis." Computer vision and image understanding.
本文实际上是提出2种方法来做行为识别的,2种方法只是在特征提取的时候不同,其分类器设计都是3D的ISM模型。2种方法提取的特征作者都称为动作元素,用一个抽象的7维向量(x,y,t,s,d,c,w)表示,一种称为判别式,一种称为产生式。
首先来看判别式模型特征点提取的过程。对一类动作的所有视频,使用STIP特征点检测算子对这些视频进行特征点检测,STIP即时候空特征兴趣点。由于这些特征点是针对视频内所有内容检测的,所有很有可能把很多与人体运动无关的噪声点也检测进去了。所以作者用了一个叫SBFC的分类器将不属于对应动作类的特征点过滤掉。SBFC的中文名叫稀疏贝叶斯分类器。该分类器需要学习2个参数即稀疏率和回归系数,学习的方法是半监督学习。对视频数据的标注不是很方便,因为视频中每一帧数据,其动作发生的范围都有可能在不断的变换。因此该SBFC的半监督方法对数据标注分为2部分,如果是负样本视频,即该视频中没有此类动作产生,则全部标注为负样本。对正样本视频的标注,在标注前,先给出一个该动作在视频中应该出现多少个特征点的经验值,然后人工看完视频,从视频中目标所在视频图像大小或者体积来看,如果比经验值的要大,则标注正样本视频中特征点的个数给多些,反之给少些。这样对一个动作的所有视频就可以学习出一个稀疏贝叶斯分类器了,由于该分类器是一个条件概率,所以作者将其称为判别式模型
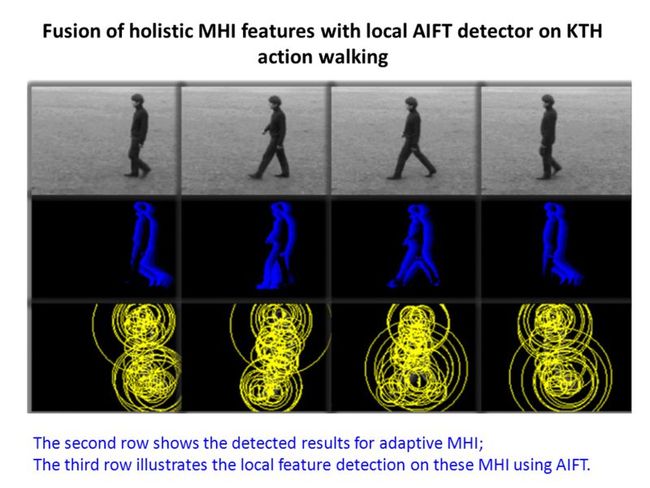
再来看看产生式模型特征点的提取过程。该过程与前面的判别式模型相互独立,是另一套方法。作者先对每个视频算出其MHI,即运动历史图。然后对每个MHI图像采用AIFT特征点检测算子,AIFT中文名为仿射无关特征变换,与SIFT类似。当然因为此时的AIFT算子不是在原视频帧中进行的,而是在MHI上生产的,而MHI与物体的运动直接相关,因此很大一部分与运动相关的特征点也同时被检测出来了。为了过滤掉这些噪声点,作者用了一个产生式核函数来过滤,该核函数中用到了与特征点匹配有关的参数,具体是怎么做到滤波效果的,个人暂时还没有理解。按照作者的意思是如果属于对应动作的特征点,则能通过所有不同参数的核函数,即计算出来属于对应动作的概率都比较大。由于该核函数是用联合概率表示的,所以称为产生式模型。
经过上面2种方法检测出来的特征点后,作者将其统一归一化为一个抽象的7维向量,叫动作元素,用(x,y,t,s,d,c,w)表示,其中x,y,t表示特征点在三维中的坐标,s是特征点的尺度大小,d是以特征点为中心的特征块的描述向量,c是特征点的类别标号,因为作者对检测出来的所有特征点的d进行了聚类。W为该特征块的主要梯度方向。其中d的描述2种方法略有不同,判别式模型是用的HOG+HOF描述串联起来的,而产生式模型是用SIFT描述的。
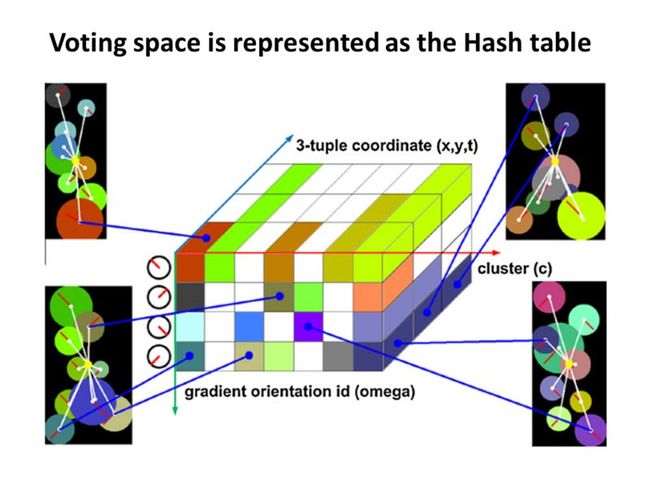
当提取到一类视频的所有动作元素后,用这些特征点的c和w值作为索引,构造一个3维的ISM Hash表。该3维表的2维是c和w,另外一维为其时空坐标(x,y,t),这个3维表有点类似2维直方图,但又有所不同,因为它不但是统计满足相同的w和c的特征点的个数,还保存了其特征点的空间坐标,给后面测试阶段投影用的。当把一个动作所有视频检测出来的动作元素在Hash表中投票投完后,这个动作对应的3维ISM模型也就建立完了。
测试时,对新来的一个视频,用STIP+SBFC或者MHI+AIFT算法对其进行特征点检测,然后对每一个动作元素归一化为一个抽象的7维向量。类似而二维的ISM算法,新来的每一个动作元素,算出其c和w,用这2个参数激活与每一个动作类建立好了的Hash表中具有相同的c和w动作元素,因为这些被激活的动作元素中保存了其相对于运动中心的相对时空位移,所以根据其相对位移和本动作元素的时空坐标就可以在匹配空间中对运动全局中心位置进行投影。
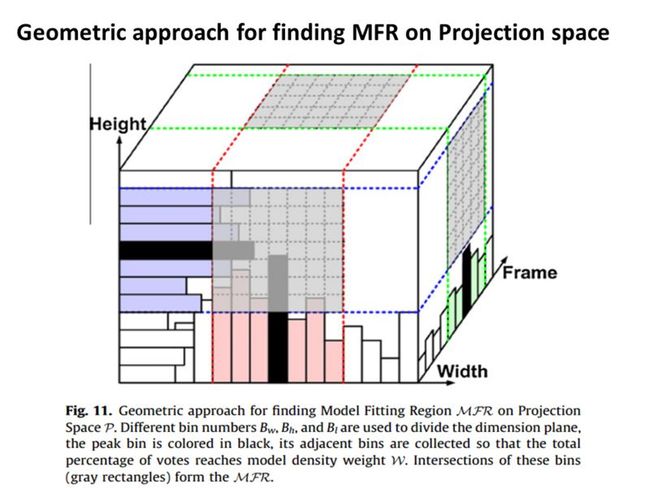
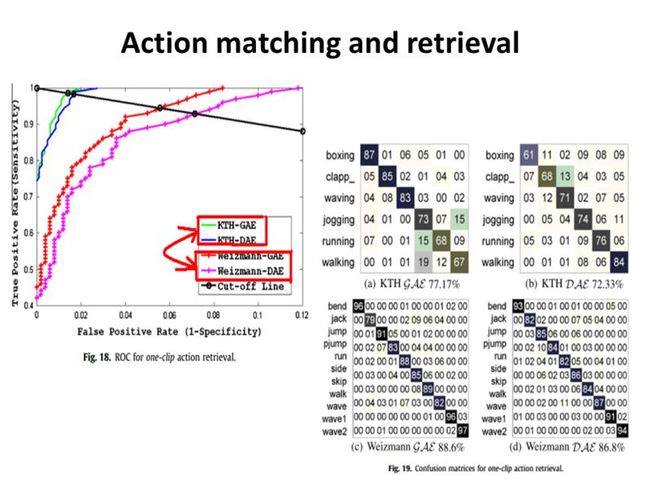
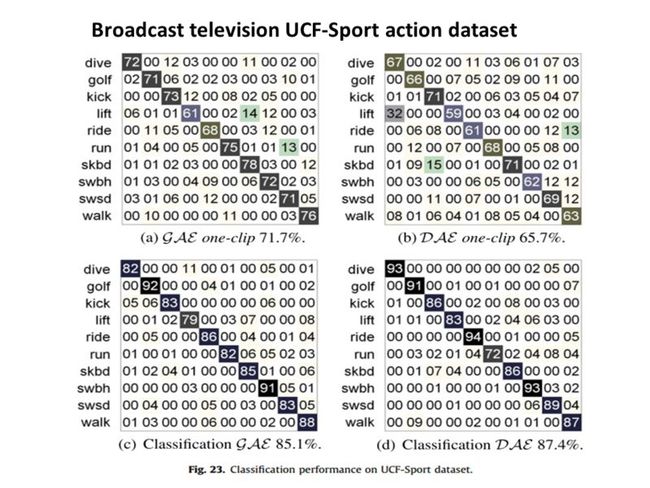
这样对新来的视频,其对每个动作类的ISM模型都得到了一个投影空间,最后只需通过这个投影空间计算其相似度即可。现在需要对这个3维的投影空间要找到一个密度最大的地方,由于是3维的,文章中说采用传统的meanshift算法其计算复杂度非常大且难以保证收敛,所以作者自己用了一个近似求解的方法。即对投影空间中的每一维建立一个直方图,直方图的值为落在这个直方图立体空间中投影点的个数。然后取该直方图值最大的bin以及其左右相邻的bin,构成一个长方体,在3个维度上就有3个长方体,这3个长方体相交是一个小长方体,也即所求密度最大的区域。称为MFR,即模型匹配区域。当求出了MFR内投影点的个数后,作者通过一定的技巧就可以算出其与某个动作模型匹配的分数,求出得分最高的那个动作即最后分类所对应的动作。
作者通过实验发现,如果训练视频比较少的话,产生式模型的效果较判别式模型的好,但是当训练视频达到一定数目后,判别式模型的效果反而更好。
下面是本人在实验室读完这篇文章做的一个报告的ppt: