SQL Server UPSERT equivalent
UPSERT functionality refers to either updating table rows based on some search condition, or inserting new rows if the search condition is not satisfied. This is intuitively seen from the word UPSERT - a combination of UPDATE (needed rows are present) or INSERT (needed rows are not present).
The most common way to implement UPSERT requires multiple statements. Let's say we have a simple table A_Table with just two columns - a key column (Id) and a data column (Data).
CREATE TABLE A_Table ( Id INT IDENTITY(1,1) NOT NULL, Data VARCHAR(50) CONSTRAINT PK_A_Table PRIMARY KEY(id) ) INSERT INTO A_Table (data) VALUES ('data1')
At this point we have one row in A_Table:
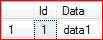
The traditional UPSERT will look like this:
-- UPDATE or INSERT based on SELECT search predicate -- DECLARE @key INT SELECT @key = Id FROM A_Table WHERE -- Search predicates -- Data = 'data_searched' IF (@key IS NOT NULL) -- Update part of the 'UPSERT' -- UPDATE A_Table SET Data = 'data_searched_updated' ELSE -- INSERT part of the 'UPSERT' -- INSERT A_Table (Data) VALUES ('data_searched')
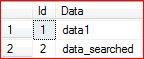
After
SELECT * FROM A_TABLE
We'll see two rows:
Fortunately, the UPSERT functionality can be implemented in one statement using MERGE statement. MERGE first appeared in SQL Server 2008.
Here is one-statement equivalent to the multi-statement UPSERT above.
MERGE INTO A_Table USING (SELECT 'data_searched' AS Search_Col) AS SRC -- Search predicates -- ON A_Table.Data = SRC.Search_Col WHEN MATCHED THEN -- Update part of the 'UPSERT' -- UPDATE SET Data = 'data_searched_updated' WHEN NOT MATCHED THEN -- INSERT part of the 'UPSERT' -- INSERT (Data) VALUES (SRC.Search_Col);
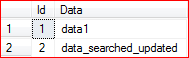
If we run this query on existing two-row A_Table, we'll get this table (second row was matched and updated):
Benefits of the MERGE statement over separate SELECT/INSERT/UPDATE include:
- Faster performance. The Engine needs to parse, compile, and execute only one query instead of three (and no temporary variable to hold the key).
- Neater and simpler T-SQL code (after you get proficient in MERGE).
- No need for explicit BEGIN TRANSACTION/COMMIT. MERGE is a single statement and is executed in one implicit transaction.
- Greater functionality. MERGE can delete rows that are not matched by source (SRC table above). For example, we can delete row 1 from A_Table because its Data column does not match Search_Col in the SRC table. There is also a way to return inserted/deleted values using the OUTPUT clause.