在Windos上使用Eclipse进行Hadoop开发的环境搭建
使用eclipse的hadoop开发环境搭建
1.准备
1.1 完成linux上的hadoop集群安装,并且能够从WIN上远程到linux
如果你还未完成安装集群可以参考我的这篇博文(注意是基于Mesos的) 《基于集群资源管理器Mesos的Hadoop安装教程地址》
1.2 在你的本机上也安装好JDK和Eclipse
我本机使用的Java版本是1.7的 JDK1.7官方下载地址
我使用的Eclipse版本是3.62 Eclipse官方下载地址
注意:你使用的Hadoop版本和你使用的Eclipse版本有“十分大的关系”
如果你是按照我前面的教程基于Mesos的Hadoop0.20.205.0安装的集群则可以直接下载我重新编译好的插件。
适用于Hadoop0.20.205.0的插件(请使用Eclipse 3.62才能正常运行) 下载地址
说明:如果你使用的Hadoop版本是1.0以及以上的稳定版本则可以下载最新的Eclipse以及Eclipse插件
hadoop插件请根据自己对应的版本下载(一定要和自己的版本相同)。或者根据我的教程《编译自己的Hadoop Eclipse插件》,这样就不会由于插件和Hadoop版本不对应造成的各种奇怪的错误。
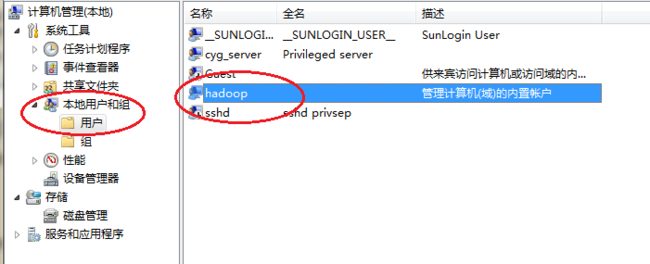
1.3 修改系统管理员名字
右键我的电脑 -----> 管理 右键击你的Administrator重命名(重启生效)
1.4 参考说明
本文参考了虾皮的博客,并且结合自己的实际情况重新对这更个过程进行了撰写。过程更加简洁清晰,针对易错点进行了分析。(特别是不匹配的问题)
参考博客地址: 虾皮的博客
2.安装配置
2.1 安装Eclipse 部署好插件
Eclipse直接解压就可以使用了(建议别安装在有中文字符的目录,我安装在E:\)
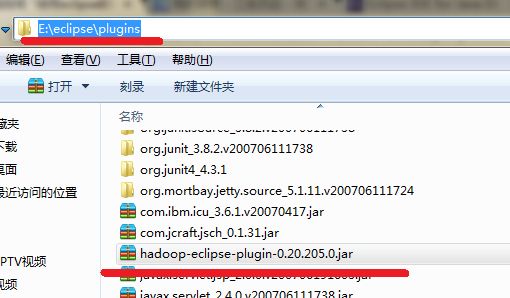
将你下载好的插件放到Eclipse解压目录下的plugins目录下
2.2 打开Eclipse进行一些配置
2.2.1 配置好Hadoop文件到Windows上
虽然是从本地远程去操作的,但是还是会用到本身Hadoop的安装文件(这个Hadoop安装文件要和你远程Linux的Hadoop版本要一致。)
注意:
如果你Linux上的Hadoop做过很多的修改,可以考虑将Linux上的Hadoop安装目录下的所有文件提取到Windows上,这样肯定不会出现缺类这种事情了。
可以采用SecureCRT来完成上传到WINDOWS。忘记如何使用请参考《基于集群资源管理器Mesos的Hadoop安装教程地址》
在Linux下可以使用tar -zcvf hadoop-.20.205.0 这样讲该目录下所有文件打包 然后传递出来,解压到一个目录。比如我的解压在F:/下
如果插件正常工作了,可以看到左侧有这样的窗体。

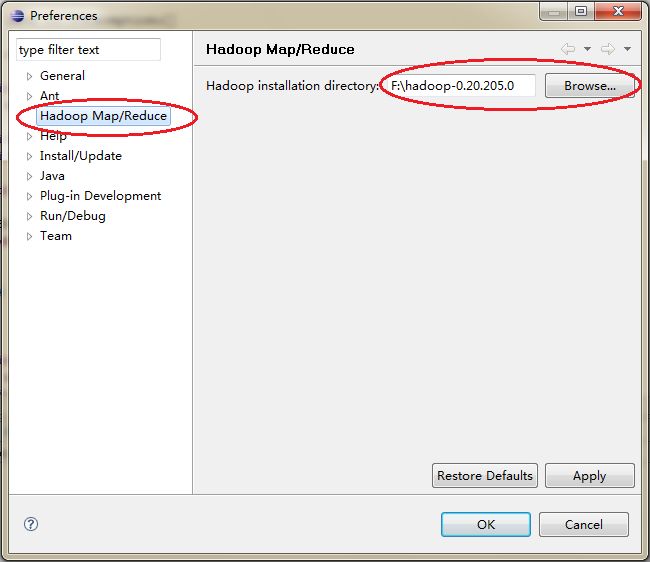
将Windows上的Hadoop安装目录进行指定(打开Window-----> Preference) 点击右侧的浏览加入文件
2.2.2 打开MapReduce配置界面进行配置
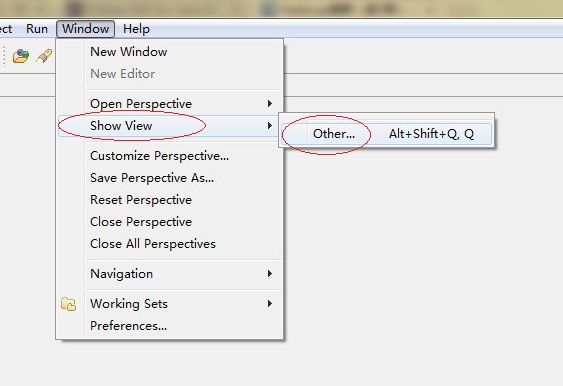
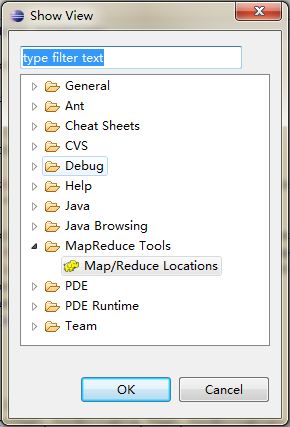
点击OK 这样在下面就会有Map/Reduce的管理窗体。在空白处右键点击Edit Hadoop Location
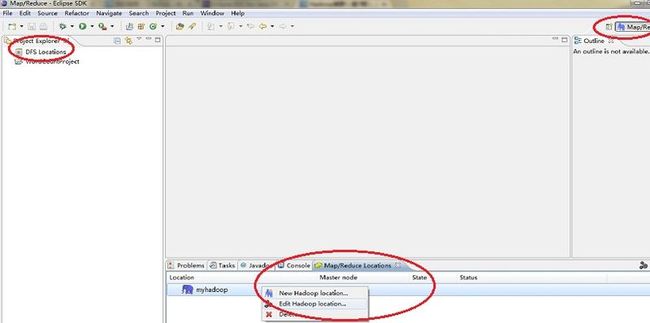
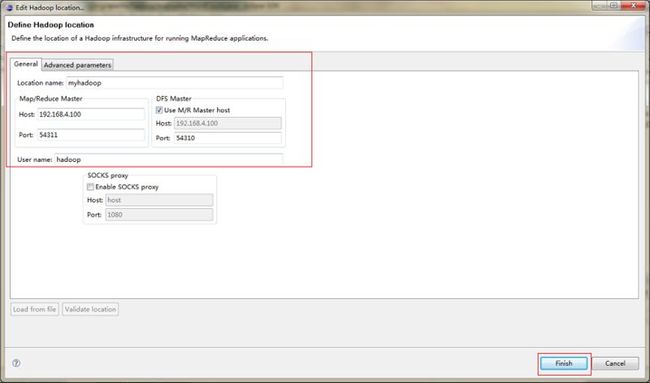
按照如下图配置 IP都是填写Master的IP,Mapreduce的端口号和HDFS端口号忘记的话可以直接去Linux下的$HADOOP_HOME/conf下自己查看
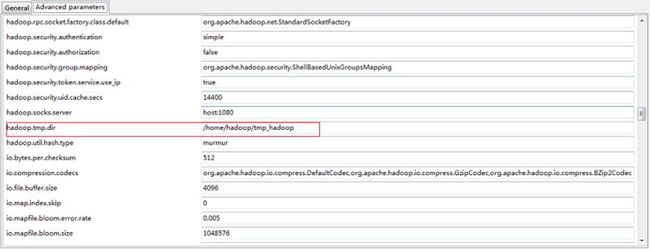
将参数配置成和Linux上的Hadoop相同 hadoop.tmp.dir参数
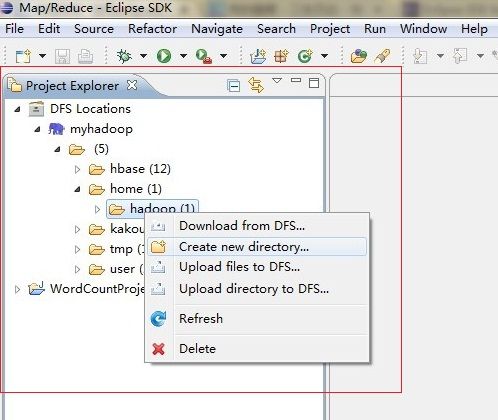
2.3 查看HDFS
如果之前的操作都正确,现在应该可以正常在HDFS上创建目录文件夹 上传等操作了。
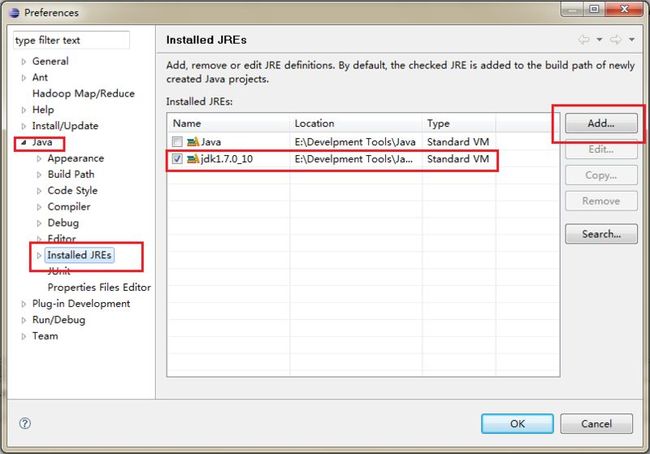
2.4 配置Eclipse JDK
配置实用JDK 没有就ADD
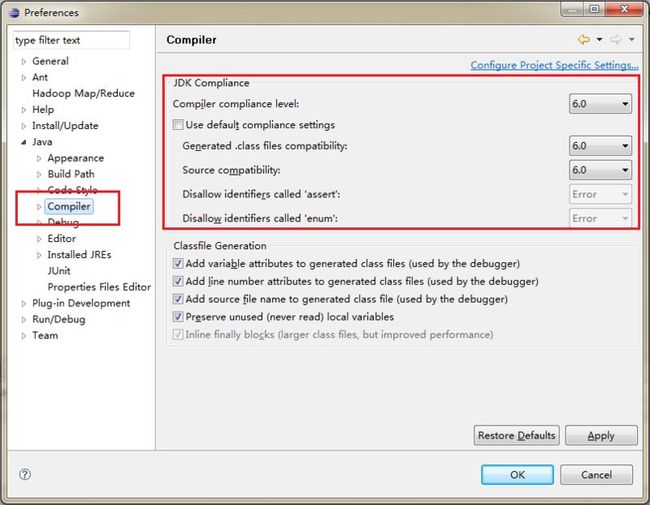
配置JAVA编译器选择6.0
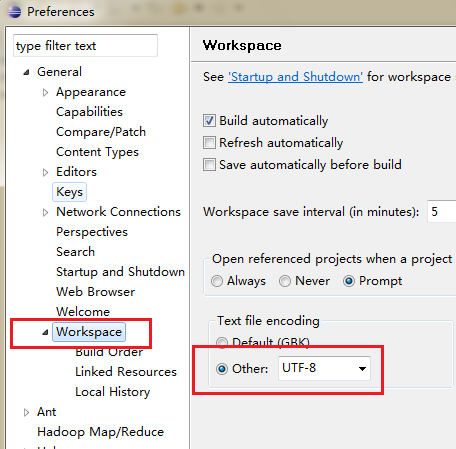
2.5 配置下编码防止乱码
3.创建工程运行WordCount例子
3.1 创建一个JAVA工程 名字随意
3.2 在工程下创建一个包叫做org.apache.hadoop.examples
3.3 创建一个JAVA类WordCount并且将以下代码复制进去
package org.apache.hadoop.examples; import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.GenericOptionsParser; public class WordCount { public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>{ private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(Object key, Text value, Context context ) throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(word, one); } } } public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable> { private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values, Context context ) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); conf.set("mapred.job.tracker", "192.168.4.100:54311"); String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs(); if (otherArgs.length != 2) { System.err.println("Usage: wordcount <in> <out>"); System.exit(2); } Job job = new Job(conf, "word count"); job.setJarByClass(WordCount.class); job.setMapperClass(TokenizerMapper.class); job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path(otherArgs[0])); FileOutputFormat.setOutputPath(job, new Path(otherArgs[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } }
注意:main方法里面的conf.set("mapred.job.tracker", "192.168.4.100:54311");这句话"千万不要忘记"哦,指定Master的IP 要不然电脑可不知道会出现
Failed to set permissions of path XXX 0700 这样的错误哦
3.4 准备好文件
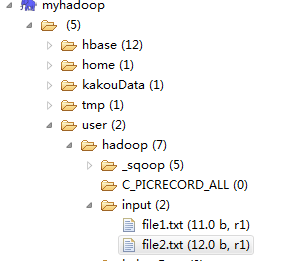
在HDFS上也有主目录 就是user/yourLinusUser 我的是 user/hadoop
我们在这个目录下创建一个目录input 然后在WINDOWS本机上写两个TXT文件内容分别是
hello world 和 hello hadoop 然后将他们上传到HDFS 然后就会如下图的样子
3.5 设置运行参数
右键WordCount.java
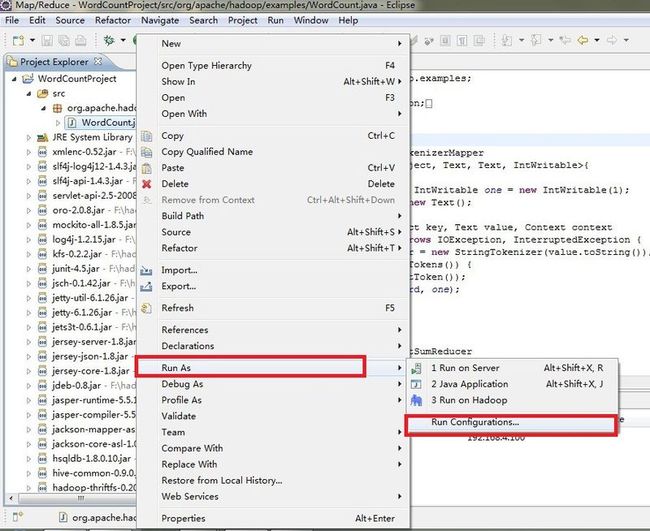
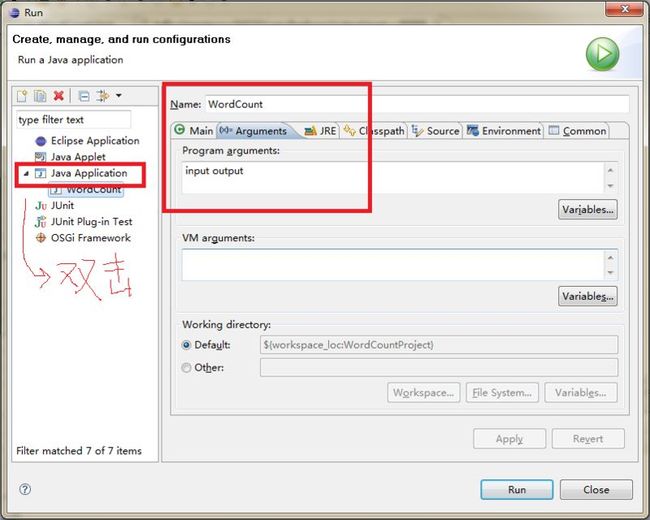
为什么这里输入的文件只要input就可以了呢?因为这是我们的主目录,如果要严格指定路径可以采用如下方式来指定文件
hdfs://192.168.4.100:54310/user/hadoop/input
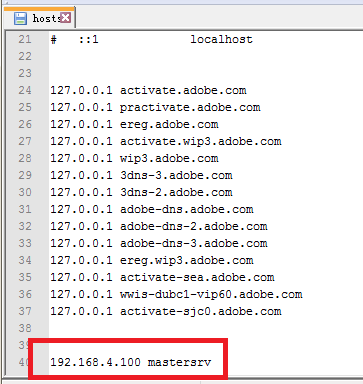
3.6 修改Windows下的hosts文件 要不人无法识别master的哦
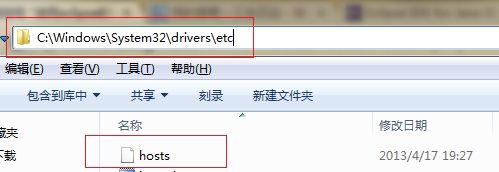
修改它 添加你的LINUX主机信息
3.7 开始运行吧少年。。。
细心的同学肯定发现我上面配置启动参数的那副截图的图表和其他的图不一样了。。。因为笔者一开始开错个eclipse最后才发现。请同学要确认你使用的版本是3.62才能正确运行0.20.205.0的hadoop哦。(1.0以上的稳定版就没关系啦)
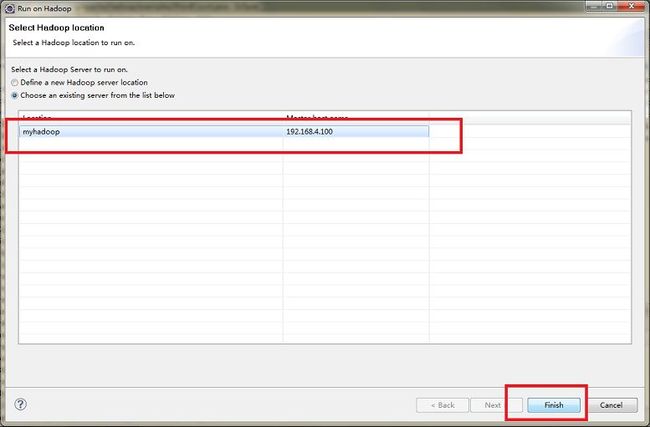
右键WordCount.java点击run on hadoop
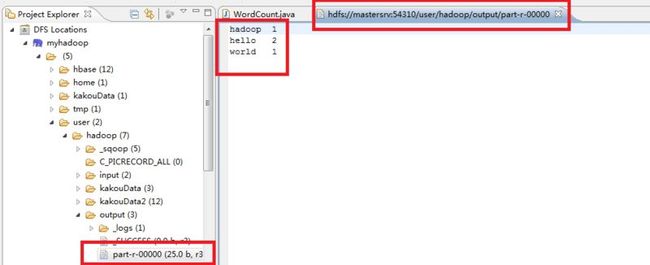
3.7 查看结果 在output中
至此,我们的教程结束了。有问题欢迎留言交流。