栈与队列
简介
堆栈和队列都属于线性结构,是两种在运算上受到某些限制的特殊线性表,他们比一般线性表更简单,被广泛应用于类型的程序设计中,可以用来存放许多中间信息,在系统软件设计以及递归问题处理方面都离不开堆栈和队列。
栈
栈的操作原则是:先进后出,后进先出
二、栈的特点
根据栈的定义可知,最先放入栈中元素在栈底,最后放入的元素在栈顶,而删除元素刚好相反,最后放入的元素最先删除,最先放入的元素最后删除。 也就是说,栈是一种后进先出(Last In First Out)的线性表,简称为LIFO表。
三、栈的运算
1.初始化栈:INISTACK(&S)
将栈S置为一个空栈(不含任何元素)。
2.进栈:PUSH(&S,X)
将元素X插入到栈S中,也称为 “入栈”、 “插入”、 “压入”。
3.出栈: POP(&S)
删除栈S中的栈顶元素,也称为”退栈”、 “删除”、 “弹出”。
4.取栈顶元素: GETTOP(S)
取栈S中栈顶元素。
5.判栈空: EMPTY(S)
判断栈S是否为空,若为空,返回值为1,否则返回值为0。
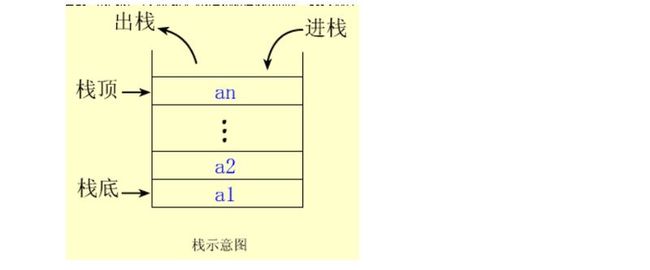
栈总是处于栈空、栈满或不空不满三种状态之一,它们是通过栈顶指针top的值体现出来的。 规定:top的值为下一个进栈元素在数组中的下标值。 栈空时(初始状态),top=0; 栈满时,top=MAXN.
三、栈的五种运算 (一) 进栈 1) 进栈算法 (1) 检查栈是否已满,若栈满,进行“溢出”处理。 (2) 将新元素赋给栈顶指针所指的单元。 (3) 将栈顶指针上移一个位置(即加1)。
(二) 出栈 1) 出栈算法 (1) 检查栈是否为空,若栈空,进行“下溢”处理。 (2)将栈顶指针下移一个位置(即减1) 。 (3)取栈顶元素的值,以便返回给调用者。
四.栈的共享存储单元 有时,一个程序设计中,需要使用多个同一类型的栈,这时候,可能会产生一个栈空间过小,容量发生溢出,而另一个栈空间过大,造成大量存储单元浪费的现象。 为了充分利用各个栈的存储空间,这时可以采用多个栈共享存储单元,即给多个栈分配一个足够大的存储空间,让多个栈实现存储空间优势互补。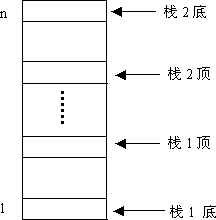
4、两个栈共享同一存储空间 当程序中同时使用两个栈时,可以将两个栈的栈底设在向量空间的两端,让两个栈各自向中间延伸。当一个栈里的元素较多,超过向量空间的一半时,只要另一个栈的元素不多,那么前者就可以占用后者的部分存储空间。 只有当整个向量空间被两个栈占满(即两个栈顶相遇)时,才会发生上溢。因此,两个栈共享一个长度为m的向量空间和两个栈分别占用两个长度为 └ m/2┘和┌m/2┐的向量空间比较,前者发生上溢的概率比后者要小得多。
队列
1、定义 队列(Queue)是只允许在一端进行插入,而在另一端进行删除的运算受限的线性表
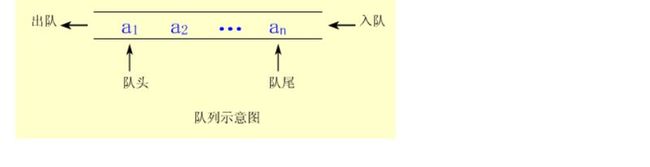
(1)允许删除的一端称为队头(Front)。 (2)允许插入的一端称为队尾(Rear)。 (3)当队列中没有元素时称为空队列。 (4)队列亦称作先进先出(First In First Out)的线性表,简称为FIFO表。 队列的修改是依先进先出的原则进行的。新来的成员总是加入队尾(即不允许"加塞"),每次离开的成员总是队列头上的(不允许中途离队),即当前"最老的"成员离队。
队列的存储结构:
顺序队列 队列的顺序存储结构称为顺序队列,顺序队列实际上是运算受限的顺序表,和顺序表一样,顺序队列也是必须用一个数组来存放当前队列中的元素。由于队列的队头和队尾的位置是变化的,因而要设两个指针和分别指示队头和队尾元素在队列中的位置。
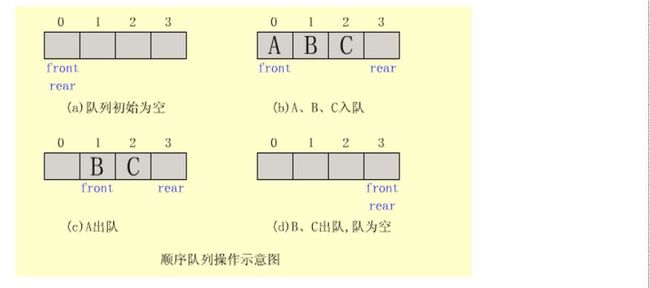
(3) 顺序队列的基本操作 队列也有队空、队满或不空不满三种情况。 1.第一种表示方法 规定:head指向队首元素的位置,tail指向队尾元素的位置。队列初始状态设为head=0,tail=-1. 当队列非空时,tail>=head; 当队列空时, head>tail; 当队列满时, tail=maxsize-1. 2.第二种表示方法 规定:head指向队首元素的前一个位置,tail指向队尾元素的位置。队列初始状态设为head=tail=-1. 1)当队列非空时,tail>head; 2)当队列空时, head=tail; 3)当队列满时, tail=maxsize-1. ①入队时:将新元素插入rear所指的位置,然后将rear加1。 ②出队时:删去front所指的元素,然后将front加1并返回被删元素。
(4)顺序队列中的溢出现象 ① "下溢"现象 当队列为空时,做出队运算产生的溢出现象。“下溢”是正常现象,常用作程序控制转移的条件。 ② "真上溢"现象 当队列满时,做进栈运算产生空间溢出的现象。“真上溢”是一种出错状态,应设法避免。 ③ "假上溢"现象 从顺序存储的队列可以看出,有可能出现这样情况,尾指针指向一维数组最后,但前面有很多元素已经出队,即空出很多位置,这时要插入元素,仍然会发生溢出。例如,在下图中,若队列的最大容量maxsize=4,此时,tail=3,再进队时将发生溢出。我们将这种溢出称为“假溢出”。 要克服“假溢出”,可以将整个队列中元素向前移动,直到头指针head为零,或者每次出队时,都将队列中元素前移一个位置。因此,顺序队列的队满判定条件为tail=maxsize-1。但是,在顺序队列中,这些克服假溢出的方法都会引起大量元素的移动,花费大量的时间,所以在实际应用中很少采用,一般采用下面的循环队列形式。
循环队列
一)定义 为了克服顺序队列中假溢出,通常将一维数组queue[0]到q[maxsize-1]看成是一个首尾相接的圆环,即queue[0]与queue[maxsize-1]相接在一起。将这种形式的顺序队列称为循环队列 。
若tail+1=maxsize,则令tail=0. 这样运算很不方便,可利用数学中的求模运算来实现。
入队:tail=(tail+1) mod maxsize;squeue[tail]=x. 出队:head=(head+1) mod maxsize.
二)循环队列的变化
在循环队列中,若head=tail,则称为队空, 若(tail+1) mod maxsize=head, 则称为队满,这时,循环队列中能装入的元素个数为maxsize-1,即浪费一个存储单元,但是这样可以给操作带来较大方便。
三)循环队列上五种运算实现
1.进队列
1)进队列算法
(1)检查队列是否已满,若队满,则进行溢出错误处理;
(2)将队尾指针后移一个位置(即加1),指向下一单元;
(3)将新元素赋给队尾指针所指单元。
2) 进队列实现程序
int head=0,tail=0;
int enqueue (elemtype queue[], elemtype x)
{ if ((tail+1)%maxsize = = head) return(1);
else
{
tail=(tail+1)%maxsize;
queue[tail]=x;
return(0);
}
}
2. 出队列
1)出队列算法
(1)检查队列是否为空,若队空,则进行下溢错误处理;
(2)将队首指针后移一个位置(即加1);
(3)取队首元素的值。
2) 出队列实现程序
int head=0,tail=0;
int dlqueue(elemtype queue[ ],elemtype *p_x )
{
if (head= =tail) return(1);
else
{
head =(head+1) % maxsize;
*p_x=queue[head]];
return(0);
}
}
(3) 队列初始化 head=tail=0;
(4) 取队头元素(注意得到的应为头指针后面一个位置值)
elemtype gethead(elemtype queue[ ] )
{ if (head= =tail) return(null);
else return (queue[(head+1)%maxsize]);
}
(5) 判队列空否
int empty(elemtype queue[ ] )
{
if (head= =tail) reurn (1);
else return (0);
}
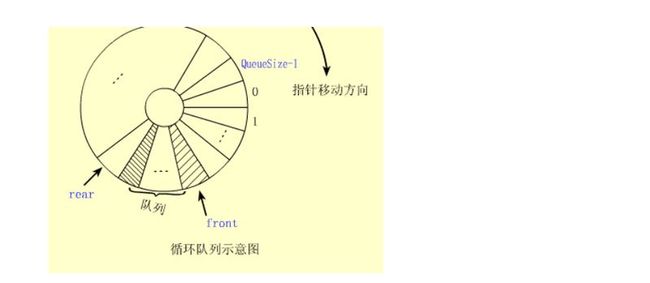
(1) 循环队列的基本操作
循环队列中进行出队、入队操作时,头尾指针仍要加1,朝前移动。
只不过当头尾指针指向向量上界(QueueSize-1)时,其加1操作的结果是指向向量的下界0。
这种循环意义下的加1操作可以描述为:
① 方法一: if(i+1==QueueSize) //i表示front或rear i=0;
else i++;
② 方法二--利用"模运算"
i=(i+1)%QueueSize;
(2) 循环队列边界条件处理
循环队列中,由于入队时尾指针向前追赶头指针;出队时头指针向前追赶尾指针,造成队空和队满时头尾指针均相等。因此,无法通过条件front==rear来判别队列是"空"还是"满"。
【参见动画演示】 解决这个问题的方法至少有三种:
① 另设一布尔变量以区别队列的空和满;
② 少用一个元素的空间。约定入队前,测试尾指针在循环意义下加1后是否等于头指针,若相等则认为队满(注意:rear所指的单元始终为空);
③使用一个计数器记录队列中元素的总数(即队列长度)。
(3) 循环队列的类型定义
#define Queur Size 100 //应根据具体情况定义该值
typedef char Queue DataType; //DataType的类型依赖于具体的应用
typedef Sturet{ //头指针,队非空时指向队头元素
int front; //尾指针,队非空时指向队尾元素的下一位置
int rear; //计数器,记录队中元素总数
DataType data[QueueSize]
}CirQueue;
(4) 循环队列的基本运算 用第三种方法,循环队列的六种基本运算:
① 置队空
void InitQueue(CirQueue *Q)
{
Q->front=Q->rear=0;
Q->count=0; //计数器置0
}
② 判队空
int QueueEmpty(CirQueue *Q)
{
return Q->count==0; //队列无元素为空
}
③ 判队满
int QueueFull(CirQueue *Q)
{
return Q->count==QueueSize; //队中元素个数等于QueueSize时队满
}
④ 入队
void EnQueue(CirQueuq *Q,DataType x)
{
if(QueueFull((Q))
Error("Queue overflow"); //队满上溢
Q->count ++; //队列元素个数加1
Q->data[Q->rear]=x; //新元素插入队尾
Q->rear=(Q->rear+1)%QueueSize; //循环意义下将尾指针加1
⑤ 出队
DataType DeQueue(CirQueue *Q)
{
DataType temp;
if(QueueEmpty((Q))
Error("Queue underflow"); //队空下溢
temp=Q->data[Q->front];
Q->count--; //队列元素个数减1
Q->front=(Q->front+1)&QueueSize; //循环意义下的头指针加1
return temp;
}
⑥取队头元素
DataType QueueFront(CirQueue *Q)
{
if(QueueEmpty(Q))
Error("Queue if empty.");
return Q->data[Q->front];
}
链队列
一、队列的链式存储结构 队列的链式存储是用一个线性链表来实现一个队列的方法,线性链表表示的队列称为链队列。
在链队列中,链表的第一个节点存放队列的队首结点,链表的最后一个节点存放队列的队尾首结点,队尾结点的链接指针为空。并设一头指针指向队首结点,设一尾指针指向队尾结点。 当队列为空时,有head=NULL.
二、链队列上的基本运算
1 .入队列
1)进队算法
(1) 为待进队元素申请一个新结点,给该结点赋值;
(2)将x结点链到队尾结点上;
(3)队尾指针改为指向x结点。
2)实现程序
NODE *head=NULL, *tail;
Void link_ins_queue(elemtype x)
{
NODE *p;
p=(NODE *)malloc(sizeof(NODE));
p->data=x;
p->link=null;
if (head==null) head=p;
else tail->link=p;
tail=p;
}
2. 出队列
1)出队算法
(1) 检查队列是否为空,若为空进行下溢错误处理;
(2)取队首元素的值并将队首指针暂存;
(3)头指针后移,指向新队首结点,并删除原队首结点。
2) 实现程序
int del_queue(elemtype *p_x)
{ NODE *p;
if (head= =NULL)
return(1);
*p_x=head->data;
p=head;
head=head->link;
free(p);
return(0);
}

注意: 增加指向链表上的最后一个结点的尾指针,便于在表尾做插入操作。 链队列示意图见上图,图中Q为LinkQueue型的指针。
注意: ①和链栈类似,无须考虑判队满的运算及上溢。 ②在出队算法中,一般只需修改队头指针。但当原队中只有一个结点时,该结点既是队头也是队尾,故删去此结点时亦需修改尾指针,且删去此结点后队列变空。 ③以上讨论的是无头结点链队列的基本运算。和单链表类似,为了简化边界条件的处理,在队头结点前也可附加一个头结点,增加头结点的链队列的基本运算。