javascript实现数据结构: 树和二叉树的应用--最优二叉树(赫夫曼树),回溯法与树的遍历--求集合幂集及八皇后问题
赫夫曼树及其应用
赫夫曼(Huffman)树又称最优树,是一类带权路径长度最短的树,有着广泛的应用。
最优二叉树(Huffman树)
1 基本概念
① 结点路径:从树中一个结点到另一个结点的之间的分支构成这两个结点之间的路径。
② 路径长度:结点路径上的分支数目称为路径长度。
③ 树的路径长度:从树根到每一个结点的路径长度之和。
以下图为例:

A到F :结点路径 AEF ;
路径长度(即边的数目) 2 ;
树的路径长度:3*1+5*2+2*3=19;
④ 结点的带权路径长度:从该结点的到树的根结点之间的路径长度与结点的权(值)的乘积。
权(值):各种开销、代价、频度等的抽象称呼。
⑤ 树的带权路径长度:树中所有叶子结点的带权路径长度之和,记做:
WPL=w1*l1+w2*l2+⋯+wn*ln=∑wi*li (i=1,2,⋯,n)
其中:n为叶子结点的个数;wi为第i个结点的权值; li为第i个结点的路径长度。
⑥ Huffman树:具有n个叶子结点(每个结点的权值为wi) 的二叉树不止一棵,但在所有的这些二叉树中,必定存在一棵WPL值最小的树,称这棵树为Huffman树(或称最优树) 。
在许多判定问题时,利用Huffman树可以得到最佳判断算法。
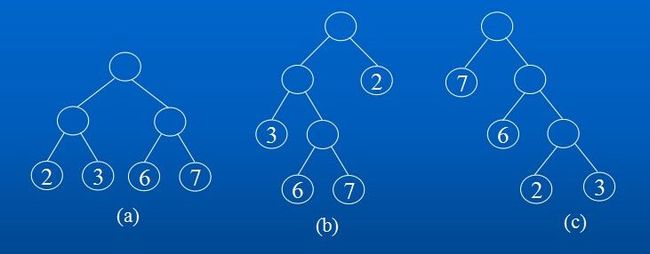
下图是权值分别为2、3、6、7,具有4个叶子结点的二叉树,它们的带权路径长度分别为:
(a) WPL=2*2+3*2+6*2+7*2=36 ;
(b) WPL=2*1+3*2+6*3+7*3=47 ;
(c) WPL=7*1+6*2+2*3+3*3=34 。
其中(c)的 WPL值最小,可以证明是Huffman树。
2 Huffman树的构造
① 根据n个权值{w1, w2, ⋯,wn},构造成n棵二叉树的集合F={T1, T2, ⋯,Tn},其中每棵二叉树只有一个权值为wi的根结点,没有左、右子树;
② 在F中选取两棵根结点权值最小的树作为左、右子树构造一棵新的二叉树,且新的二叉树根结点权值为其左、右子树根结点的权值之和;
③ 在F中删除这两棵树,同时将新得到的树加入F中;
④ 重复②、③,直到F只含一棵树为止。
构造Huffman树时,为了规范,规定F={T1,T2, ⋯,Tn}中权值小的二叉树作为新构造的二叉树的左子树,权值大的二叉树作为新构造的二叉树的右子树;在取值相等时,深度小的二叉树作为新构造的二叉树的左子树,深度大的二叉树作为新构造的二叉树的右子树。
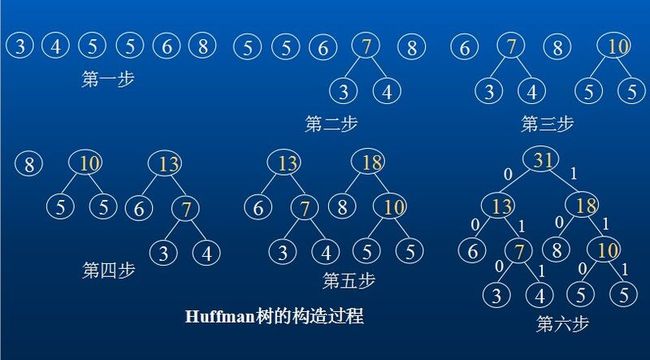
下图是权值集合W={8, 3, 4, 6, 5, 5}构造Huffman树的过程。所构造的Huffman树的WPL是: WPL=6*2+3*3+4*3+8*2+5*3+5*3 =79
赫夫曼编码及其算法
1 Huffman编码
在电报收发等数据通讯中,常需要将传送的文字转换成由二进制字符0、1组成的字符串来传输。为了使收发的速度提高,就要求电文编码要尽可能地短。此外,要设计长短不等的编码,还必须保证任意字符的编码都不是另一个字符编码的前缀,这种编码称为前缀编码。
Huffman树可以用来构造编码长度不等且译码不产生二义性的编码。
设电文中的字符集C={c1,c2, ⋯,ci, ⋯,cn},各个字符出现的次数或频度集W={w1,w2, ⋯,wi, ⋯,wn}。
Huffman编码方法
以字符集C作为叶子结点,次数或频度集W作为结点的权值来构造 Huffman树。规定Huffman树中左分支代表“0”,右分支代表“1” 。
从根结点到每个叶子结点所经历的路径分支上的“0”或“1”所组成的字符串,为该结点所对应的编码,称之为Huffman编码。
由于每个字符都是叶子结点,不可能出现在根结点到其它字符结点的路径上,所以一个字符的Huffman编码不可能是另一个字符的Huffman编码的前缀。
若字符集C={a, b, c, d, e, f}所对应的权值集合为W={8, 3, 4, 6, 5, 5},如上图所示,则字符a,b, c,d, e,f所对应的Huffman编码分别是:10,010,011,00 ,110,111。
2 Huffman编码算法实现
(1) 数据结构设计
Huffman树中没有度为1的结点棵有n个叶子结点的Huffman树共有2n-1个结点,则可存储在大小为2n-1的一维数组中。
原因:
◆ 求编码需从叶子结点出发走一条从叶子到根的路径;
◆ 译码需从根结点出发走一条到叶子结点的路径。
1 // 赫夫曼树和赫夫曼编码的存储结构 2 function HuffmanNode(weight, parent, leftChild, rightChild) { 3 this.weight = weight || 0; 4 this.parent = parent || 0; 5 this.leftChild = leftChild || 0; 6 this.rightChild = rightChild || 0; 7 }
Weight:权值域;
Parent:双亲结点下标
leftChild, rightChild:分别标识左、右子树的下标
(2) Huffman树的生成
1 // 创建一棵叶子结点数为n的Huffman树 2 function buildHuffmanTree(weights, n) { 3 n = n || weights.length; 4 var m = 2 * n - 1; 5 var huffmanTree = []; 6 7 // 初始化 8 for (var i = 0; i < n; i++) 9 huffmanTree[i] = new HuffmanNode(weights[i], 0, 0, 0); 10 for (; i < m; i++) 11 huffmanTree[i] = new HuffmanNode(0, 0, 0, 0); 12 13 for (i = n; i < m; i++) { 14 // 在HT[1..i-1]选择parent为0且weight最小的两个结点,返回其序号为[s1, s2] 15 var ret = select(huffmanTree, i); 16 var s1 = ret[0]; 17 var s2 = ret[1]; 18 huffmanTree[s1].parent = i; 19 huffmanTree[s2].parent = i; 20 huffmanTree[i].leftChild = s1; 21 huffmanTree[i].rightChild = s2; 22 huffmanTree[i].weight = huffmanTree[s1].weight + huffmanTree[s2].weight; 23 } 24 25 return huffmanTree; 26 } 27 28 function select(huffmanTree, len) { 29 var ret = []; 30 for (var i = 0; i < len; i++) { 31 var node = huffmanTree[i]; 32 if (node.parent !== 0) continue; 33 34 if (ret.length < 2) { 35 ret.push(i); 36 } else { 37 var index = huffmanTree[ret[0]].weight > huffmanTree[ret[1]].weight 38 ? 0 : 1; 39 40 if (node.weight < huffmanTree[ret[index]].weight) 41 ret[index] = i; 42 } 43 } 44 45 if (ret[0] > ret[1]) { 46 var temp = ret[0]; 47 ret[0] = ret[1]; 48 ret[1] = temp; 49 } 50 51 return ret; 52 }
说明:生成Huffman树后,树的根结点的下标是2n-1 ,即m-1 。
(3) Huffman编码算法
根据出现频度(权值)Weight,对叶子结点的Huffman编码有两种方式:
① 从叶子结点到根逆向处理,求得每个叶子结点对应字符的Huffman编码。
② 从根结点开始遍历整棵二叉树,求得每个叶子结点对应字符的Huffman编码。
由Huffman树的生成知,n个叶子结点的树共有2n-1个结点,叶子结点存储在数组HT中的下标值为1∽n。
① 编码是叶子结点的编码,只需对数组HT[1…n]的n个权值进行编码;
② 每个字符的编码不同,但编码的最大长度是n。
算法实现:
1 function huffManCoding(weights) { 2 var n = weights.length; 3 if (n < 1) return; 4 5 var huffmanTree = buildHuffmanTree(weights, n); 6 7 // 从叶子到根逆向求每个字符的赫夫曼编码 8 var hc = calcHuffmanCode(huffmanTree, n); 9 10 return [huffmanTree, hc]; 11 } 12 13 function calcHuffmanCode(huffmanTree, n) { 14 // 从叶子到根逆向求每个字符的赫夫曼编码 15 var hc = []; 16 var cd = []; 17 for (var i = 0; i < n; i++) { 18 var start = n - 1; 19 for (var c = i, f = huffmanTree[i].parent; f != 0; c = f, f = huffmanTree[f].parent) { 20 if (huffmanTree[f].leftChild == c) cd[--start] = '0'; 21 else cd[--start] = '1'; 22 } 23 24 hc[i] = strCopy(cd, start); 25 } 26 27 return hc; 28 } 29 30 function strCopy(str, start) { 31 var s = ''; 32 for (; str[start]; start++) { 33 s += str[start]; 34 } 35 return s; 36 }
全部代码实现:
1 // 赫夫曼树和赫夫曼编码的存储结构 2 function HuffmanNode(weight, parent, leftChild, rightChild) { 3 this.weight = weight || 0; 4 this.parent = parent || 0; 5 this.leftChild = leftChild || 0; 6 this.rightChild = rightChild || 0; 7 } 8 function huffManCoding(weights) { 9 var n = weights.length; 10 if (n < 1) return; 11 12 var huffmanTree = buildHuffmanTree(weights, n); 13 14 // 从叶子到根逆向求每个字符的赫夫曼编码 15 var hc = calcHuffmanCode(huffmanTree, n); 16 17 return [huffmanTree, hc]; 18 } 19 20 function calcHuffmanCode(huffmanTree, n) { 21 // 从叶子到根逆向求每个字符的赫夫曼编码 22 var hc = []; 23 var cd = []; 24 for (var i = 0; i < n; i++) { 25 var start = n - 1; 26 for (var c = i, f = huffmanTree[i].parent; f != 0; c = f, f = huffmanTree[f].parent) { 27 if (huffmanTree[f].leftChild == c) cd[--start] = '0'; 28 else cd[--start] = '1'; 29 } 30 31 hc[i] = strCopy(cd, start); 32 } 33 34 return hc; 35 } 36 37 // 创建一棵叶子结点数为n的Huffman树 38 function buildHuffmanTree(weights, n) { 39 n = n || weights.length; 40 var m = 2 * n - 1; 41 var huffmanTree = []; 42 43 // 初始化 44 for (var i = 0; i < n; i++) 45 huffmanTree[i] = new HuffmanNode(weights[i], 0, 0, 0); 46 for (; i < m; i++) 47 huffmanTree[i] = new HuffmanNode(0, 0, 0, 0); 48 49 for (i = n; i < m; i++) { 50 // 在HT[1..i-1]选择parent为0且weight最小的两个结点,返回其序号为[s1, s2] 51 var ret = select(huffmanTree, i); 52 var s1 = ret[0]; 53 var s2 = ret[1]; 54 huffmanTree[s1].parent = i; 55 huffmanTree[s2].parent = i; 56 huffmanTree[i].leftChild = s1; 57 huffmanTree[i].rightChild = s2; 58 huffmanTree[i].weight = huffmanTree[s1].weight + huffmanTree[s2].weight; 59 } 60 61 return huffmanTree; 62 } 63 64 function strCopy(str, start) { 65 var s = ''; 66 for (; str[start]; start++) { 67 s += str[start]; 68 } 69 return s; 70 } 71 72 function select(huffmanTree, len) { 73 var ret = []; 74 for (var i = 0; i < len; i++) { 75 var node = huffmanTree[i]; 76 if (node.parent !== 0) continue; 77 78 if (ret.length < 2) { 79 ret.push(i); 80 } else { 81 var index = huffmanTree[ret[0]].weight > huffmanTree[ret[1]].weight 82 ? 0 : 1; 83 84 if (node.weight < huffmanTree[ret[index]].weight) 85 ret[index] = i; 86 } 87 } 88 89 if (ret[0] > ret[1]) { 90 var temp = ret[0]; 91 ret[0] = ret[1]; 92 ret[1] = temp; 93 } 94 95 return ret; 96 } 97 98 console.log('-------huffman coding :------'); 99 console.log(huffManCoding([5, 29, 7, 8, 14, 23, 3, 11]));
回溯法与树的遍历
在程序设计中,有相当一类求一组解,或求全部解或求最优解的问题,例如八皇后问题等,不是根据某种确定的计算法则,而是利用试探和回溯(backtracking)的搜索技术求解。回溯法也是设计递归过程的一种重要方法,它的求解过程实质上是一个选序遍历一棵“状态树”的过程,只是这棵树不是遍历前预先建立的,而是隐含在遍历过程中。
求含n个元素的集合的幂集:
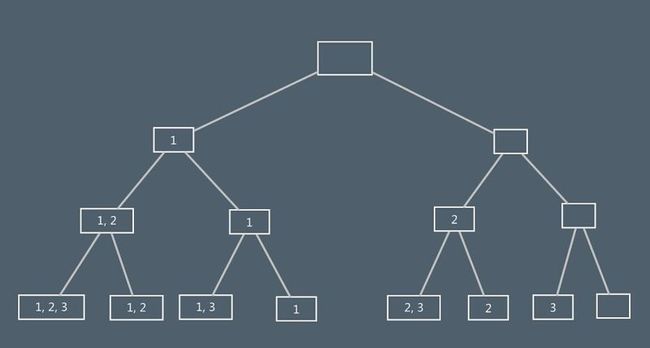
集合A的幂集是由集合A的所有子集所组成的集合。如:A = {1,2,3},则A的幂集p(A) = {{1,2,3}, {1,2}, {1,3}, {1}, {2,3}, {2}, {2}, 空集}
求幂集p(A)的元素的过程可看成是依次对集合A中元素进行“取”或“舍”的过程,并且可用一棵二叉树来表示过程中幂集元素的状态变化状况。
树中根结点表示幂集元素的初始状态(为空集);
叶子结点表示它的终结状态;
而第i(i=2,3,...,n-1)层的分支结点,则表示已对集合A中前i-1个元素进行了取/舍处理的当前状态(左分支表示“取”,右分支表示“舍”)。
如下图所示:
1 // 求含集合aList的幂集 2 // 进入函数时已对A中前i-1个元素做了取舍处理 3 function getPowerSet(i, aList) { 4 var bList = []; 5 6 void function recurse(i, aList) { 7 if (i > aList.length - 1) console.log('set: ' + bList); 8 else { 9 var x = aList[i]; 10 bList.push(x); 11 recurse(i + 1, aList); 12 bList.pop(); 13 recurse(i + 1, aList); 14 } 15 }(i, aList); 16 17 return bList; 18 } 19 20 console.log('getPowerSet:'); 21 var list = [1, 2, 3]; 22 console.log('list: ' + getPowerSet(0, list));
求八皇后问题的所有合法布局:
同理,我们可以用回溯法解决八皇后问题。
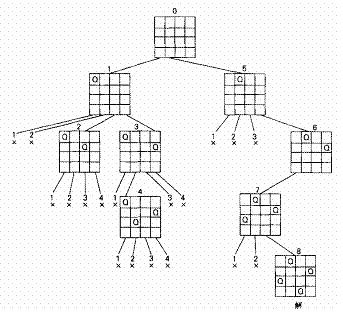
首先,我们把问题简化为四皇后问题。
在求解过程,棋盘的状态变化就像一棵四叉树,树上每个结点表示一个局部布局或一个完整布局。根结点表示棋盘的初始状态:棋盘上无任何棋子。每个(皇后)棋子都有4个可选择的位置,但在任何时刻,棋盘的合法布局都必须满足任何两个棋子都不占据棋盘上同一行,或者同一列,或者同一对角线。
求所有合法布局的过程即为上述约束条件下先根遍历状态树的过程。
遍历中访问结点的操作为,判别棋盘上是否已得到一个完整的布局(即棋盘上是否已有4个棋子)。
若是,则输出该布局;
否则依次先根遍历满足约束条件的各棵子树,即首先判断该子树根的布局是否合法;
若合法,则先根遍历该子树;
否则剪去该子树分支。
为了通用性,我将代码实现成n皇后问题:
1 // 求n皇后问题的所有合法布局 2 function Queen(n) { 3 var board = []; 4 var count = 0; 5 6 this.init = function(){ 7 for(var i = 0; i < n; i++){ 8 board[i] = []; 9 for(var j = 0; j < n; j++){ 10 board[i][j] = 0; 11 } 12 } 13 }; 14 15 this.init(); 16 17 this.getSolutionsCount = function(){ 18 return count; 19 }; 20 21 this.printCurrentLayout = function () { 22 ++count; 23 console.log(board); 24 }; 25 26 this.addPoint = function (i, j) { 27 if(board[i][j] === 0){ 28 board[i][j] = 1; 29 return true; 30 } else { 31 console.log('already occupated!'); 32 return false; 33 } 34 }; 35 36 this.isCurrentLayoutLegal = function (i, j) { 37 return checkHorizontal(i, j) && checkVertical(i, j) && checkLeftTop2RightBottom(i, j) && checkRightTop2LeftBottom(i, j); 38 }; 39 40 function checkHorizontal(x, y){ 41 for(var i = 0; i < y; i++){ 42 if(board[x][i] === 1) return false; 43 } 44 for(i = y + 1; i < n; i++){ 45 if(board[x][i] === 1) return false; 46 } 47 return true; 48 } 49 50 function checkVertical(x, y){ 51 for(var i = 0; i < x; i++){ 52 if(board[i][y] === 1) return false; 53 } 54 for(i = x + 1; i < n; i++){ 55 if(board[i][y] === 1) return false; 56 } 57 return true; 58 } 59 60 function checkLeftTop2RightBottom(x, y){ 61 for(var i = 1; x - i >= 0 && y - i >= 0; i++){ 62 if(board[x - i][y - i] === 1) return false; 63 } 64 for(i = 1; x + i < n && y + i < n; i++){ 65 if(board[x + i][y + i] === 1) return false; 66 } 67 return true; 68 } 69 70 function checkRightTop2LeftBottom(x, y){ 71 for(var i = 1; x - i >= 0 && y + i < n; i++){ 72 if(board[x - i][y + i] === 1) return false; 73 } 74 for(i = 1; x + i < n && y - i >= 0; i++){ 75 if(board[x + i][y - i] === 1) return false; 76 } 77 return true; 78 } 79 80 this.removePoint = function (i, j) { 81 if(board[i][j] === 1){ 82 board[i][j] = 0; 83 } 84 }; 85 86 var me = this; 87 this.trial = function trial(i) { 88 i = i || 0; 89 if (i > n - 1) { 90 me.printCurrentLayout(); 91 } else { 92 for (var j = 0; j < n; j++) { 93 if(me.addPoint(i, j)){ 94 if (me.isCurrentLayoutLegal(i, j)) trial(i + 1); 95 me.removePoint(i, j); 96 } 97 } 98 } 99 }; 100 } 101 102 var test = new Queen(8); 103 test.trial(); 104 console.log('getSolutionsCount: ' + test.getSolutionsCount());