聚簇索引 二级索引(辅助索引、非聚簇索引) 联合索引
针对主键构建的索引,我们称之为聚簇索引,而针对非主键构建的索引,我们称之为非聚簇索引(辅助索引或者是二级索引)
聚簇索引 二级索引(辅助索引、非聚簇索引) 联合索引
1. 聚簇索引(Clustered Index)
数据即索引,索引即数据,形成了一种你中有我,我中有你的关系。
聚簇索引并不需要直接用INDEX语句去创建,一旦创建表添加数据,自动出来聚簇索引
定义
- 数据存储顺序与索引顺序一致,即索引的叶子节点直接存储了数据。
- 每张表只能有一个聚簇索引,因为数据的物理存储方式只能有一种。
- InnoDB 存储引擎默认使用主键作为聚簇索引,如果没有主键,会选取唯一索引,否则自动生成一个隐藏的
rowid作为聚簇索引。
特点
✅ 查询主键很快,因为索引和数据存储在一起,数据不用从多个数据块里面提取数据,减少一次磁盘 I/O。
✅ 范围查询快,如 BETWEEN,数据是物理连续存储的,读取更高效。
✅ 排序查找快,如 ORDER BY 主键,因为 InnoDB 的聚簇索引 会按主键顺序存储数据,数据是逻辑上连续存储的(尽量减少页分裂)。
❌ 可能存在碎片化,即便有索引,仍可能导致较多磁盘随机 I/O,影响查询性能。
❌ 更新、插入数据时可能触发页分裂,影响性能。 插入数据严重依赖于插入排序,更新主键的代价很高。对于InnoDB表,我们一般会定义一个自增ID作为主键。,同时设置主键为不可更新
❌ 影响二级索引的查询速度(回表查询).二级索引需要两次索引查找,第一次找到主键的值,第二次根据主键的值找到数据
限制
1 对于mysql数据库目前只有InnoDB数据引擎支持聚簇索引,但是MyISAM并不支持聚簇索引
2 数据物理存储排序方式智能有一种,所以每个mysql只能有一个聚簇索引,一般情况下是这个表的主键
3 如果没有定义主键,Innodb会选择非空的唯一索引代替,如果没有这样的索引,Innodb会隐式的定义一个主键来作为聚簇索引
4 为了充分的利用聚簇索引的聚簇特性,所以主键需要选择用有序的顺序ID,而不建议用无序的ID,比方说UUID,MD5,HASH,字符串序列等主键无法保证数据的顺序增长(这样不会按照顺序依照次序排列)
示例
CREATE TABLE users (
id INT PRIMARY KEY, -- 主键自动成为聚簇索引
name VARCHAR(100),
age INT
);
查询:
SELECT * FROM users WHERE id = 100;
- 查询过程:
- B+ 树叶子节点直接存储
id=100的完整数据,无需回表查询。
- B+ 树叶子节点直接存储
2. 二级索引(Secondary Index / 辅助索引 / 非聚簇索引)
如果想用其他的列作为搜索条件,那么就需要多建几棵B+树,类似于树的树,组成了二级,这个上层树的叶子节点,存的就是底层树的信息,而不是实际的数据
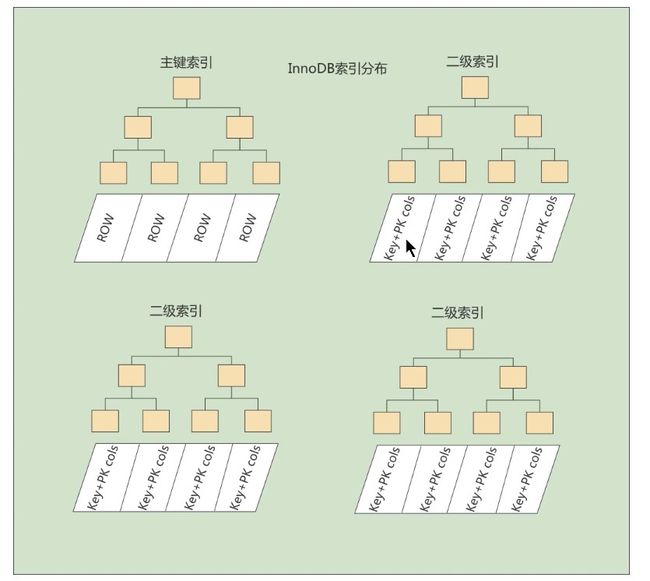
定义
- 二级索引(非聚簇索引)是普通的 B+ 树索引,叶子节点存储的不是数据行,而是主键的值。
- 查找时,数据库先通过二级索引找到主键,然后再通过聚簇索引找到完整数据。
特点
✅ 可以创建多个二级索引,优化不同查询。
❌ 查询时可能需要回表,因为存储的是主键而不是完整数据。
❌ 占用额外存储空间,二级索引还要存主键信息。
❌ 插入删除更加麻烦,二级索引还需要穿透一层。
示例
CREATE TABLE users (
id INT PRIMARY KEY, -- 聚簇索引
name VARCHAR(100),
age INT,
INDEX idx_name (name) -- 非聚簇索引
);
查询:
SELECT * FROM users WHERE name = 'Alice';
- 查询过程:
- 先查
idx_name二级索引,找到name='Alice'对应的主键id。 - 再根据
id查找 聚簇索引,获取完整数据。
- 先查
3. 联合索引(Composite Index)
定义
- 多个列组合在一起建立的索引,用于优化多列查询。
- 遵循 最左前缀匹配 原则(必须从左到右匹配)。
特点
✅ 查询多个列时性能更高,避免创建多个单列索引。
❌ 最左前缀原则,查询时必须从左到右依次匹配,否则索引失效。
示例
CREATE TABLE users (
id INT PRIMARY KEY,
name VARCHAR(100),
age INT,
INDEX idx_name_age (name, age) -- 联合索引
);
索引 (name, age) 适用于:
✅ WHERE name = 'Alice' AND age = 25 ✅(匹配整个索引)
✅ WHERE name = 'Alice' ✅(匹配索引的第一列)
❌ WHERE age = 25 ❌(无法利用索引)
索引对比总结
| 索引类型 | 数据存储方式 | 查询方式 | 优点 | 缺点 |
|---|---|---|---|---|
| 聚簇索引 | 叶子节点存储完整数据 | 直接查找到数据 | ✅ 主键查询快 ✅ 范围查询快 | ❌ 影响二级索引性能 ❌ 更新/插入可能触发页分裂 |
| 二级索引 | 叶子节点存主键 | 需要回表查询数据 | ✅ 可创建多个索引 | ❌ 需要回表 ❌ 额外占存储 |
| 联合索引 | 多列索引,按最左前缀匹配 | 根据最左列顺序优化查询 | ✅ 多列查询性能好 | ❌ 受最左前缀限制 |
索引优化时需要合理选择索引类型,平衡存储与查询性能。
存储引擎
MySQL 的存储引擎主要有 InnoDB 和 MyISAM,它们在索引结构、存储方式、性能、事务支持等方面存在较大差异,尤其是在索引上有本质不同。
1. InnoDB 索引
1.1 索引存储方式
-
聚簇索引(Clustered Index):
- InnoDB 的主键索引就是聚簇索引,叶子节点直接存储完整数据。
- 如果没有显式定义主键,则选择唯一索引作为聚簇索引;如果没有唯一索引,则自动生成一个
rowid作为聚簇索引。 - 数据按照主键的顺序存储,物理存储和索引结构紧密结合。
-
二级索引(Secondary Index):
- InnoDB 允许创建多个二级索引(普通索引)。
- 叶子节点存储的是主键值,需要先查找二级索引,再回表查询数据。
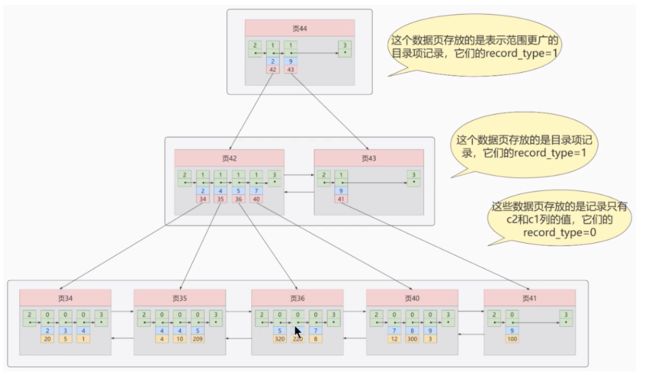
1.2 InnoDB 索引示意图
假设有如下表:
CREATE TABLE users (
id INT PRIMARY KEY, -- 聚簇索引
name VARCHAR(100),
age INT,
INDEX idx_name (name) -- 普通二级索引
);
查询:
SELECT * FROM users WHERE name = 'Alice';
查询过程(索引回表):
- 先查询
idx_name二级索引,找到name='Alice'对应的id。 - 再通过
id查询聚簇索引,获取完整数据。
1.3 InnoDB 索引特点
✅ 支持事务(MyISAM 不支持)。
✅ 支持外键约束(MyISAM 不支持)。
✅ 支持 MVCC(多版本并发控制),提高并发性能。
✅ 适合高并发的 OLTP(在线事务处理)。
❌ 二级索引查询需要回表,可能增加 I/O 开销。
❌ 更新、删除时可能导致页分裂,影响性能。
2. MyISAM 索引
2.1 索引存储方式
- MyISAM 使用的是非聚簇索引(独立索引)。
- 主键索引与二级索引结构相同,都使用 B+ 树,但叶子节点存储的是数据的物理地址(row pointer),而不是完整数据。
- 数据和索引是分离存储的,数据文件 (
.MYD) 和索引文件 (.MYI) 独立管理。
2.2 MyISAM 索引示意图
假设有如下表:
CREATE TABLE users (
id INT PRIMARY KEY, -- 主键索引
name VARCHAR(100),
age INT,
INDEX idx_name (name) -- 普通索引
);
查询:
SELECT * FROM users WHERE name = 'Alice';
查询过程(索引回表):
- 先查
idx_name索引,找到name='Alice'对应的 数据文件地址(row pointer)。 - 通过该地址,直接读取数据文件中的完整数据。
2.3 MyISAM 索引特点
✅ 二级索引查询更快,因为索引存储的是数据的地址,而不是主键,因此不需要二次查询(回表)。
✅ 适用于读密集型应用,如 OLAP(在线分析处理)或日志系统。
✅ 表级锁机制,适用于批量操作。
❌ 不支持事务,不适用于银行、支付等业务。
❌ 不支持外键,数据完整性需要应用层保证。
❌ 数据文件容易碎片化,可能影响查询性能。
3. InnoDB vs MyISAM 索引对比总结
| 对比项 | InnoDB(默认) | MyISAM(已淘汰) |
|---|---|---|
| 索引结构 | 聚簇索引(主键索引存数据) | 非聚簇索引(索引存数据地址) |
| 主键索引 | 叶子节点存储完整数据 | 叶子节点存数据地址 |
| 二级索引 | 叶子节点存主键,需要回表查询 | 叶子节点存数据地址,不需要回表 |
| 查询效率 | 适用于高并发事务,查询时可能需要回表 | 适用于读密集型应用,查询时不需要回表 |
| 插入/更新 | 插入可能导致页分裂,影响性能 | 插入快,数据写在表末尾 |
| 事务支持 | ✅ 支持 | ❌ 不支持 |
| 外键支持 | ✅ 支持 | ❌ 不支持 |
| 锁机制 | 行级锁,适合高并发 | 表级锁,适合批量读 |
| 适用场景 | OLTP(在线事务处理) | OLAP(数据仓库、日志分析) |
4. 选择哪种索引?
✔ 选择 InnoDB
- 需要事务支持(银行、支付、用户管理等)。
- 需要高并发,适合 OLTP 场景。
- 数据更新频繁,避免碎片化问题。
✔ 选择 MyISAM(已淘汰,不推荐)
- 只读业务,如日志存储、全文搜索、报表分析。
- 不需要事务,主要进行大量
SELECT查询。
目前 MySQL 默认存储引擎是 InnoDB,建议在绝大多数业务场景下使用 InnoDB,因为 MyISAM 已经被淘汰,不再适用于现代高并发事务处理系统。