扩散模型(Diffusion Models)用于图像去噪:开启图像去噪模型新前沿
✨个人主页欢迎您的访问


✨扩散模型基本原理✨
扩散模型(Diffusion Models)近年来在计算机视觉领域引起了广泛关注,尤其在图像生成和图像去噪任务中取得了显著的成果。扩散模型的核心思想来源于物理学中的扩散过程,通过逐步添加噪声并反向模拟去噪过程,最终恢复出清晰的图像。在图像去噪领域,扩散模型的表现优于传统方法,且具备生成性强、结构化处理能力等优点。本文将深入探讨扩散模型在图像去噪中的应用,介绍其基本原理,展示相应的代码示例,并与传统的去噪模型进行对比。
扩散模型的灵感来源于马尔可夫过程。在训练阶段,扩散模型通过多步向图像添加噪声,逐渐将其破坏成纯噪声图像。然后在推理阶段,模型通过反向过程逐步恢复图像,最终生成去噪后的清晰图像。具体而言,扩散模型的核心过程可以分为两个阶段:正向扩散(Forward Diffusion)和逆向生成(Reverse Generation)。
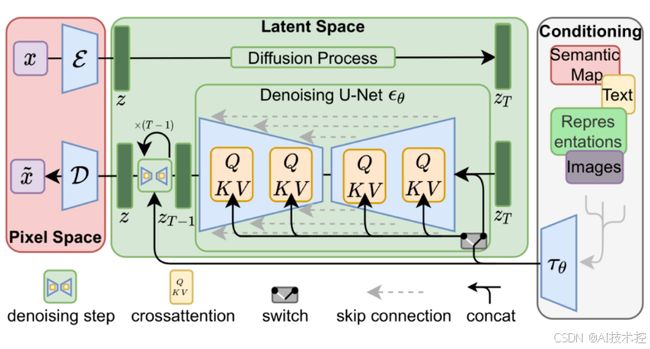 扩散模型(Diffusion model)
扩散模型(Diffusion model)
1.正向扩散(Forward Diffusion)
- 这个过程从真实图像开始,逐步向其添加噪声。假设原始图像是 x0,经过 T 步噪声添加,生成 xT,直到图像变成纯噪声。
- 该过程通过一个逐步增加噪声的方式,通常是高斯噪声。每一步的噪声添加是通过一个线性调度过程来控制的。
在正向扩散过程中,模型从真实图像开始,逐步添加噪声,最终将图像转换为纯噪声。这个过程可以用以下公式表示:
![]()
其中,βt 是一个预定义的噪声调度参数,控制每一步添加的噪声量。
2.逆向生成(Reverse Generation)
- 反向过程是从纯噪声开始,逐步去噪还原图像的过程。这个过程可以看作是一个条件生成过程,条件是每一步的噪声。
- 通过训练神经网络来预测每一步的噪声成分,并利用预测的噪声来去除噪声,恢复出清晰的图像。
逆向生成是正向扩散的逆过程。模型从纯噪声开始,逐步去噪,最终生成一幅清晰的图像。逆向过程的核心是学习一个条件概率分布:
![]()
其中,μθ 和 Σθ 是通过神经网络学习得到的参数。
3.训练目标
扩散模型的训练目标是最小化去噪误差,即预测噪声的误差:
![]()
其中,ϵ是正向扩散过程中添加的噪声,ϵθ是模型预测的噪声。
✨去噪任务中的应用✨
图像去噪任务的目标是从受噪声污染的图像中恢复原始图像。对于扩散模型而言,这意味着从噪声图像开始,反向扩散过程能够逐步去除噪声,恢复出干净的图像。
具体去噪流程
- 噪声图像输入:将噪声图像(如高斯噪声图像)作为输入。
- 反向扩散过程:模型通过反向过程进行去噪,利用预测的噪声逐步恢复清晰图像。
- 输出去噪图像:最终输出去噪后的图像。
✨扩散模型与其他图像去噪方法的对比✨
扩散模型与传统的图像去噪方法(如BM3D、非局部均值(NLM))和基于深度学习的方法(如U-Net、卷积神经网络)有显著的不同。
1. 与传统去噪方法的对比
- BM3D(Block-Matching and 3D filtering):传统的图像去噪方法,基于块匹配和3D滤波。BM3D具有较强的信号保留能力,但在复杂噪声或高噪声情况下效果较差。
- 非局部均值(NLM):通过计算图像中每个像素与其周围像素的相似性,来去除噪声。它的缺点是对于高噪声的处理效果有限,且计算复杂度较高。
与这些方法相比,扩散模型通过学习图像噪声分布并模拟去噪过程,能在复杂的噪声场景下取得更好的去噪效果,尤其是在强噪声下。扩散模型的反向过程能够生成高质量的去噪图像,并且具有生成模型的灵活性,能够处理各种噪声类型。
2. 与基于深度学习的去噪方法的对比
- U-Net:U-Net是卷积神经网络(CNN)的一种结构,常用于图像分割和去噪任务。U-Net通过编码器和解码器架构,逐步恢复图像的细节。
- DnCNN(Denoising CNN):DnCNN是另一种基于卷积神经网络的去噪方法,通过训练网络去除噪声。
与U-Net、DnCNN等方法相比,扩散模型的优势在于其生成性质。扩散模型不仅仅依赖于去噪训练数据,而是通过学习噪声分布并模拟逆过程,可以更好地恢复细节,减少伪影,尤其在高噪声或缺失数据的情况下表现优异。
✨优秀论文及资源✨
扩散模型(Diffusion Models)是近年来在生成模型领域取得显著进展的一个重要方向。它们被广泛应用于图像生成、图像超分辨率、去噪等任务。以下是一些关于扩散模型的经典论文,您可以参考这些论文来深入理解这一领域的发展。
1. "Denoising Diffusion Probabilistic Models"
- 论文链接: https://arxiv.org/abs/2006.11239
- 作者: Jonathan Ho, Ajay Jain, Pieter Abbeel
- 简介: 这篇论文提出了Denoising Diffusion Probabilistic Models (DDPM),是最早系统地引入扩散过程的生成模型之一。DDPM通过模拟一个逐步扩散过程,然后反向生成数据,成功地在图像生成任务中展示了优异的效果。它是扩散模型研究的奠基性工作,推动了该领域的进一步发展。
2. "Improved Denoising Diffusion Probabilistic Models"
- 论文链接: https://arxiv.org/abs/2006.11239
- 作者: Jonathan Ho, Xiang Xu, Tim Salimans
- 简介: 这篇论文提出了对DDPM的改进,尤其是在网络架构和训练过程中。通过新的噪声调度策略和其他技巧,提出的改进模型大大提高了生成质量,并减少了训练时间。该论文为后续的扩散模型研究奠定了基础。
3. "Score-based Generative Models"
- 论文链接: https://arxiv.org/abs/1907.05600
- 作者: Yang Song, Stefano Ermon
- 简介: 这篇论文介绍了基于评分(score-based)的生成模型,它使用了类似于扩散过程的构造思想,但通过评分模型来反向恢复数据分布。该模型在图像生成和无监督学习方面也表现出色,是扩散模型研究的另一重要方向。
4. "Latent Diffusion Models"
- 论文链接: https://arxiv.org/abs/2112.10752
- 作者: Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, Björn Ommer
- 简介: 本文提出了Latent Diffusion Models (LDMs),它将扩散模型应用于潜在空间,显著减少了计算开销,同时保持了生成质量。LDMs特别适用于生成高分辨率图像,并且能够在多种生成任务中实现优异的效果,成为目前非常流行的扩散模型变种之一。
5. "Guided Diffusion Models"
- 论文链接: https://arxiv.org/abs/2207.01097
- 作者: Prafulla Dhariwal, Alexander Nichol
- 简介: 本文提出了Guided Diffusion Models,这些模型利用条件信息(如文本描述)来引导扩散过程。通过对生成过程进行条件控制,模型能够生成符合给定条件的高质量样本。Guided Diffusion Models在多模态生成任务中(如图像生成和文本生成配对)具有广泛应用。
6. "Contrastive Language-Image Pretraining (CLIP)"
- 论文链接: https://arxiv.org/abs/2103.00020
- 作者: Alec Radford, Jong Wook Kim, et al.
- 简介: 这篇论文虽然并不专门聚焦于扩散模型,但它提出的CLIP(Contrastive Language-Image Pretraining)模型与扩散模型结合得非常好,用于引导图像生成过程。通过文本和图像的联合训练,扩散模型能够更好地生成符合文本描述的图像,推动了生成模型和跨模态学习的结合。
7. "Stable Diffusion: A Latent Text-to-Image Diffusion Model"
- 论文链接: https://arxiv.org/abs/2112.10752
- 作者: Robin Rombach, Andreas Blattmann, et al.
- 简介: 这篇论文介绍了Stable Diffusion,一个基于扩散的文本到图像生成模型。Stable Diffusion通过在潜在空间中运行扩散过程,能够在较低的计算成本下生成高质量的图像,并且支持通过文本提示生成图像。该模型在生成质量和计算效率上都有了显著提升,广泛应用于实际的图像生成任务。
8. "Deep Unsupervised Learning using Nonequilibrium Thermodynamics"
- 论文链接: https://arxiv.org/abs/1503.03585
- 作者: Jascha Sohl-Dickstein, et al.
- 简介: 本文是扩散模型领域的早期开创性工作,提出了基于热力学的生成模型,即利用扩散过程生成数据。虽然这一理论框架较为复杂,但它为后来的扩散模型提供了理论支持。
扩散模型已成为生成模型领域的重要一员,从DDPM到Stable Diffusion,它们在图像生成和多模态学习中展现了巨大的潜力。如果您想深入理解这一领域,建议从上述经典论文入手,逐步掌握不同类型的扩散模型及其应用。
✨扩散模型去噪的代码实现✨
以下是一个基于 PyTorch 的扩散模型去噪示例代码:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import numpy as np
# 简单的U-Net架构作为扩散模型的网络结构
class UNet(nn.Module):
def __init__(self):
super(UNet, self).__init__()
self.encoder = nn.Sequential(
nn.Conv2d(1, 64, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(64, 128, kernel_size=3, padding=1),
nn.ReLU()
)
self.decoder = nn.Sequential(
nn.Conv2d(128, 64, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(64, 1, kernel_size=3, padding=1)
)
def forward(self, x):
x = self.encoder(x)
x = self.decoder(x)
return x
# 定义噪声添加函数
def add_noise(image, noise_level=0.5):
noise = torch.randn_like(image) * noise_level
noisy_image = image + noise
return noisy_image
# 加载数据集(以MNIST为例)
transform = transforms.Compose([transforms.ToTensor()])
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
# 初始化模型,损失函数和优化器
model = UNet().cuda()
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
# 训练过程
num_epochs = 5
for epoch in range(num_epochs):
for batch_idx, (data, _) in enumerate(train_loader):
data = data.cuda()
noisy_data = add_noise(data) # 添加噪声
optimizer.zero_grad()
output = model(noisy_data)
loss = criterion(output, data) # 计算去噪损失
loss.backward()
optimizer.step()
if batch_idx % 100 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Step [{batch_idx+1}/{len(train_loader)}], Loss: {loss.item():.4f}')
这段代码展示了一个简单的基于 U-Net 的去噪模型。通过添加噪声并训练模型去预测去噪图像,我们可以实现在图像去噪中的应用。