Python实现Apriori算法
Apriori算法
1.代码实现流程
整体流程如下图所示:
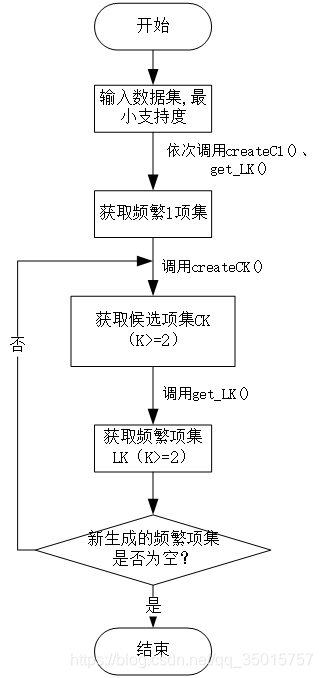
如上图所示,整个代码分为以下几个模块:
1) createC1(dataset)
说明:该函数根据输入的数据集dataset来生成候选1项集。
2)get_LK(dataset, CK, min_sup)
说明:该函数根据候选项集CK,从数据集中搜索,判断CK中每个项集在数据集中的支持度(这里用出现次数表示)是否 >= min_sup。min_sup为手动指定的最小支持度阈值,代码中以出现次数作为支持度的表示,因此min_sup应该为一个整数。
3)createCK(LK, K)
说明:该函数根据频繁项集Lk-1 ,创建候选项集Ck。参数中的k表示将要构造的Ck中每一项的长度。
4)Apriori(dataset, min_sup=2)
说明:该函数是最终的函数,将前三个函数模块整合到一起,根据输入的数据集获取所有的频繁项集。这里默认最小支持度min_sup=2。
2.python代码实现
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
@Author : Sword
@Date : 2019/12/14
@Time : 下午 22:13
@Version : v1.0
@File : Apriori.py
@Describe :关联规则 -- 经验算法
"""
def createC1(dataset):
"""
根据输入的数据集dataset生成候选1项集
"""
# C1:存放候选1项集的列表
C1 = []
# 从数据集中取出一个事物记录
# 每个事物记录都是由多个项组成的列表
for t in dataset:
for item in t:
# 判断C1中是否有这个项
# 因为是1项集,所以每个项都应该是一个集合
# 代码中用list表示集合
if [item] not in C1:
C1.append([item])
# 使用frozenset来冻结C1中的每个元素,方便后续建立字典(key -> value)
return list(map(frozenset, C1))
def get_Lk(dataset, CK, min_sup):
"""
根据候选项集CK,从数据集中搜索CK中每个项集在数据集中支持度是否 >= min_sup
根据候选项集CK,得到频繁项集LK
"""
# 创建一个字典,用于存放各项集及其出现次数.key => item_name, value => count
frequent_dict = {}
for ck in CK:
for t in dataset:
if ck.issubset(t):
# 判断frequent_dict中是否包含当前的项
# 如果没有,则添加该项,并令该项的计数为1
# 否则,令该项的计数+1
if not frequent_dict.__contains__(ck):
frequent_dict[ck] = 1
else:
frequent_dict[ck] += 1
# 创建一个字典,用于存放项集与支持度的关系
# key => item_name, value => sup(支持度)
item_sup = {}
# frequent_item:用于存放频繁项集
frequent_item = []
for f_item, value in frequent_dict.items():
if value >= min_sup:
item_sup[f_item] = value
frequent_item.append(f_item)
return frequent_item, item_sup
def createCK(LK, k):
"""
根据频繁项集L(k-1),创建候选项集CK,这里用LK表示L(k-1)
k:表示将要构造的CK中每一项的长度
"""
# 创建一个列表,存放CK
get_CK = []
for i in range(len(LK)):
for j in range(i + 1, len(LK)):
if len(LK[i] | LK[j]) == k:
get_CK.append(LK[i] | LK[j])
return list(set(get_CK))
def Apriori(dataset, min_sup=2):
"""
Apriori算法:生成所有频繁项集
"""
# 获取候选1项集
C1 = createC1(dataset)
# 创建一个列表all_fre_item:存放所有频繁项集
# 获取频繁1项集
L1, item_sup = get_Lk(dataset, C1, min_sup)
# 默认初始有频繁1项集L1
all_fre_item = [L1]
# k=2:k从2开始循环
k = 2
# 循环获取频繁项集
# 终止条件:新生成的频繁项集不为空
while (len(all_fre_item[k-2]) > 0):
CK = createCK(all_fre_item[k-2], k)
if len(CK) == 0:
break
LK, item_sup_k = get_Lk(dataset, CK, min_sup)
# item_sup为字典,每次循环调用update进行更新,存放所有频繁项集与其支持度
item_sup.update(item_sup_k)
all_fre_item.append(LK)
k += 1
return all_fre_item, item_sup
if __name__ == "__main__":
dataSet = [[1, 3, 4], [1, 3, 4], [2, 3, 5], [1, 2, 3, 5], [2, 5]]
fre_item, item_sup = Apriori(dataSet)
print('fre_item:\n', fre_item)
print('item_sup:\n', item_sup)
输出结果如下所示:
fre_item:
[[frozenset({1}), frozenset({3}), frozenset({4}), frozenset({2}), frozenset({5})], [frozenset({1, 4}), frozenset({3, 5}), frozenset({3, 4}), frozenset({2, 3}), frozenset({2, 5}), frozenset({1, 3})], [frozenset({2, 3, 5}), frozenset({1, 3, 4})]]
item_sup:
{frozenset({1}): 3, frozenset({3}): 4, frozenset({4}): 2, frozenset({2}): 3, frozenset({5}): 3, frozenset({1, 4}): 2, frozenset({3, 5}): 2, frozenset({3, 4}): 2, frozenset({2, 3}): 2, frozenset({2, 5}): 3, frozenset({1, 3}): 3, frozenset({2, 3, 5}): 2, frozenset({1, 3, 4}): 2}
注:代码参考这位博主的代码,进行了一些整理。
https://blog.csdn.net/wangzhanxidian/article/details/85009709