大语言模型的技术发展历程,从N-gram到DeepSeek-R1
本文主要从技术角度回顾自然语言处理NLP领域的发展历程,介绍各个模型的思路和创新点,聚焦NLP经典模型和技术突破的理解,不深入数学推导过程
前言
根据整个自然语言处理NLP领域的技术发展,可以将其分为四个技术阶段:统计语言模型,神经网络模型,预训练语言模型PLM,大型语言模型LLM
下文将按照这四个主要发展阶段各自介绍涌现出的经典模型和技术
统计语言模型阶段
统计语言模型主要依靠统计学方法,通过前文预测后续的单词,代表模型即N-gram
N-gram
核心思想是通过统计词序列的概率来预测下一个词,当前词的概率只依赖于前N−1个词
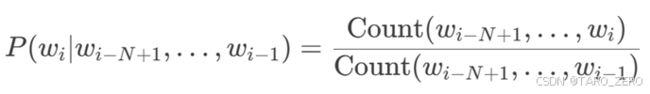
例如,当需要预测“狗坐在__”之后的下一个字词是,根据语料库中出现的次数,“狗坐在地(板上)”是出现频率最高的,那么我们就可以选择“地”作为预测的下一个字词
可以类比输入法里的后续字词推荐,会根据你此前输入的文本统计下一个字的概率并排序
很显然,这种方法无法捕捉长距离依赖关系,且数据稀疏问题严重
神经网络模型阶段
神经网络模型阶段一般会将任务拆分为词嵌入(embedding)和神经网络两个步骤,前者将单词转化为可以被计算处理的向量,后者在具体的任务上训练好模型
词嵌入模型
对于输入的字符(token),我们需要将他们处理成可以被计算机处理运算的数字形式,也就是向量,最开始我们使用独热码one-hot,但显然在字符数量增多以后独热码的存储和计算都极其不方便,我们考虑在实数域内的多维向量,这样可以在固定的维数内表征所有字符
对于输入模型中的字符,我们希望转化后的词向量能够尽可能全面的表征字符的语义特征,并让字符向量之间相互关联,用一个经典的例子来说明,“ 国王 - 男人 + 女人 = 女王 ”,越精准全面的词向量表征越有利于后续的下游任务处理
由此我们诞生了word2vec和GloVe等经典词嵌入模型
Word2vec
word2vec模型的思想很简单,每个单词都对应一个向量,那么一个句子中上下文的单词向量应该可以预测出中心词的概率,同理,一个句子的中心词应该也可以用来预测其上下文单词出现的概率,这分别是CBoW和Skip-gram的思路
基于这一思想,定义好表征上下文/中心词单词出现概率的计算方法(softmax)和表征计算误差的损失函数后,就可以通过迭代运算得到每个字符的向量表征
GloVe
与word2vec使用上下文窗口来预测不同,GloVe使用全局单词共现矩阵来计算词向量
基于这些词嵌入模型后,在下游任务的处理上,既可以直接使用训练好的模型参数进行处理,也可以利用模型重新学习一个embedding层,此后的语言任务基本都采用词嵌入+后续模型这个模式来完成(包括大语言模型)
序列模型
将单词转化为词向量后,在下游任务中,就需要用神经网络模型来基于单词序列解决特定语言任务,例如文本分类和机器翻译等
RNN系列模型
循环神经网络RNN系列模型曾是神经网络阶段NLP领域的主流模型,一经提出就受到广泛的使用,其思路来自于顺序文本的语义连贯性,根据输入文本顺序处理运算每个字符的词向量,同时每层使用相同的神经网络,训练同一个参数矩阵,通过上层结果和新的输入变量共同预测结果
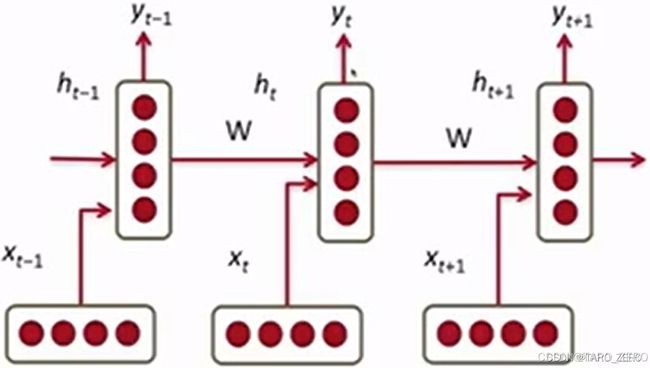
RNN网络每层输出预测的概率向量 ,由隐藏向量
,由隐藏向量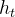 经过概率公式转化而来,则由前一个字符的隐藏向量
经过概率公式转化而来,则由前一个字符的隐藏向量 以及当前字符的词向量
以及当前字符的词向量 共同矩阵运算得到
共同矩阵运算得到
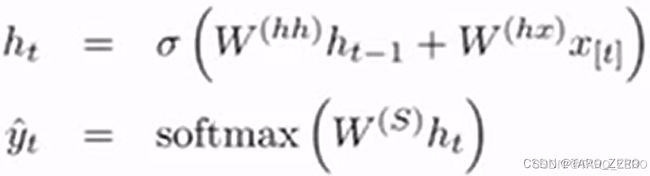
由于基础的RNN无法记忆太早之前的单词信息,模型往往不能在长句中维持精准性,GRU和LSTM模型又在每个神经元进行了进一步的改进,加入了各种门控参数,优化了每个神经元内更新隐藏向量的算法
编码器-解码器模型
RNN系列模型的输出结果是隐藏层向量或者概率预测向量,在处理文本分类等分类任务时可以直接接入一个分类器完成训练,在处理机器翻译等生成任务时则不能直接得到输出结果,由此诞生了编码器-解码器模型
由编码器将输入序列压缩成指定长度的向量,解码器再将向量转化成输出序列
在解码器中,每一层的计算不仅依赖上一层,还依赖编码器的结果向量和上一层输出的单词,最终按顺序逐个输出字符
注意力机制
人类在处理大量信息时会更加关注更具价