AI测试之Midscene.js
文章目录
- 介绍
- 一、通过 Chrome 插件快速体验
-
- 1.准备工作
- 2.安装与配置
- 二、使用 YAML 格式的自动化脚本
-
- 1.案例代码
- 2.执行步骤
- 3.结果
- yaml 文件结构
-
- target
- tasks
- 总结
-
- 即时操作(Instant Actions)- 让交互表现更稳定
- 深度思考(Deep Think)- 让元素定位更准确
介绍
Midscene.js 是字节跳动团队开源的一款基于 AI 技术的自动化 SDK,主要用于 UI 自动化测试。以下主要特点:
- 核心功能:
基于多模态大语言模型,能让测试人员使用自然语言控制页面、执行断言以及提取 JSON 格式的数据。通过自然语言交互,极大降低了自动化测试门槛,非专业编程人员也能轻松开展 UI 自动化测试工作。 - 技术支持:
采用多模态大语言模型(LLM),可直观 “理解” 用户界面并执行操作,支持公共的多模态 LLM,如 GPT - 4 等,无需定制训练。 - 工作原理:
内部采用先进的 AI 技术,基于自然语言处理(NLP)模型解析测试人员输入的自然语言文本,识别操作意图和目标元素等关键信息,通过 AI agent 实现自然语言控制页面、页面信息提取和断言页面状态等功能。同时,采用多种工程手段,如 AI 结果缓存、AI 任务报告等,提升执行速度和中间透明化。 - 可视化报告:
提供可视化报告文件,方便用户理解和调试整个测试过程,报告包含动画回放功能和每个步骤的详细信息,如操作执行时间、操作前后页面元素的状态变化等。 - 丰富接口:
支持丰富的 API 接口,方便开发者进行自定义扩展和集成,还支持与 YAML 脚本、Puppeteer 和 Playwright 等多种工具集成,能灵活适应多种自动化测试场景。
此外,Midscene.js 还提供了 Chrome 扩展,无需编写代码即可开始体验核心功能。用户也可以通过.yaml 文件定义自动化脚本,用于更高级的用例以及与 CI/CD 管道集成。
一、通过 Chrome 插件快速体验
通过使用 Midscene.js Chrome 插件,你可以快速在任意网页上体验 Midscene 的主要功能,而无需编写任何代码。
该扩展与 npm @midscene/ 包共享了相同的代码,因此你可以将其视为 Midscene 的一个 Playground 或调试工具。
1.准备工作
请先准备好以下任意模型的 API 密钥:OpenAI GPT 4o, Qwen-2.5-VL, UI-TARS 或任何其他支持的模型。
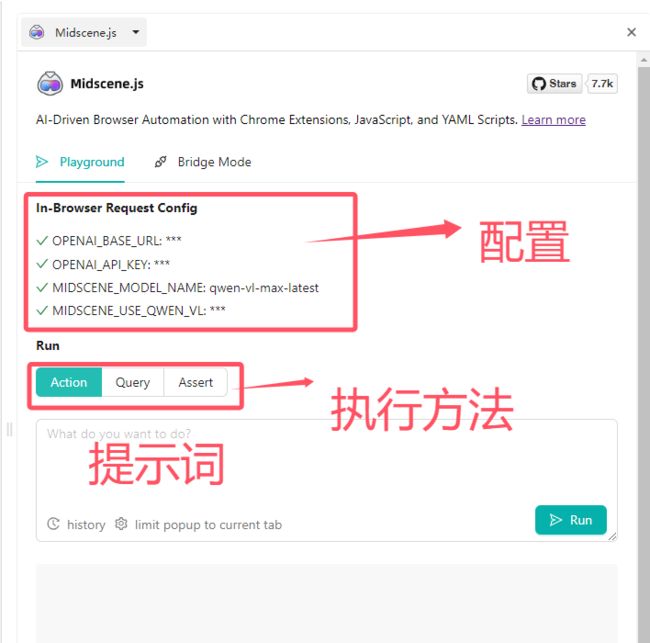
2.安装与配置
前往 Chrome 扩展商店安装 Midscene 扩展:Midscene
启动扩展(可能默认折叠在 Chrome 扩展列表中),通过粘贴 Key=Value 格式配置插件环境:(我用的是阿里云官方的 qwen-vl-max-latest 模型)
OPENAI_BASE_URL=“https://dashscope.aliyuncs.com/compatible-mode/v1” # 或任何其他提供商的接入点。
OPENAI_API_KEY=“…”
MIDSCENE_MODEL_NAME=“qwen-vl-max-latest”
MIDSCENE_USE_QWEN_VL=1 # 别忘了配置这项,用于启用 Qwen 2.5 模式!
二、使用 YAML 格式的自动化脚本
在大多数情况下,开发者编写自动化脚本只是为了执行一些冒烟测试,比如检查某些内容是否出现,或者验证某个关键用户路径是否可用。在这种情况下,维护一个大型测试项目会显得毫无必要。
Midscene 提供了一种基于 .yaml 文件的自动化测试方法,这有助于你专注于脚本本身,而不是测试框架。以此,任何团队内的成员都可以编写自动化脚本,而无需学习任何 API。
1.案例代码
示例如下:访问本地index.html,重定向
target:
serve: ./public
url: index.html
tasks:
- name: 页面重定向
flow:
- aiAction: 点击 'Go to planet list'
- sleep: 1000
- aiAssert: 页面包含 'Earth'
2.执行步骤
midscene ./midscene-scripts/local-static-server.yml
默认情况下,脚本会在无界面模式下运行。
如果你想运行在有界面模式下,你可以使用 --headed 选项。此外,如果你想在脚本运行结束后保持浏览器窗口打开,你可以使用 --keep-window 选项。–keep-window 选项会自动开启 --headed 模式。
headed 模式会消耗更多资源,所以建议你仅在本地使用。
3.结果
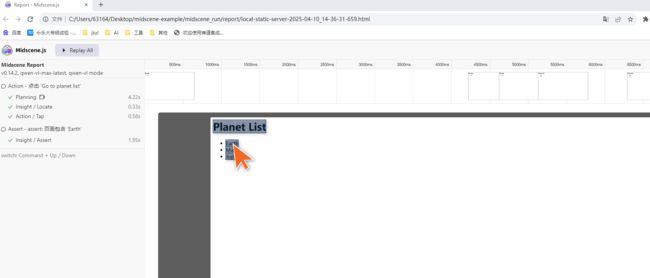
yaml 文件结构
在 .yaml 文件中,有两个部分:target 和 tasks。
target
target 部分定义了任务的基本信息:
target:
# 访问的 URL,必填。如果提供了 `serve` 参数,则提供相对路径
url: <url>
# 在本地路径下启动一个静态服务,可选
serve: <root-directory>
# 浏览器 UA,可选
userAgent: <ua>
# 浏览器视口宽度,可选,默认 1280
viewportWidth: <width>
# 浏览器视口高度,可选,默认 960
viewportHeight: <height>
# 浏览器设备像素比,可选,默认 1
deviceScaleFactor: <scale>
# JSON 格式的浏览器 Cookie 文件路径,可选
cookie: <path-to-cookie-file>
# 等待网络空闲的策略,可选
waitForNetworkIdle:
# 等待超时时间,可选,默认 10000ms
timeout: <ms>
# 是否在等待超时后继续,可选,默认 true
continueOnNetworkIdleError: <boolean>
# 输出 aiQuery 结果的 JSON 文件路径,可选
output: <path-to-output-file>
# 是否限制页面在当前 tab 打开,可选,默认 true
forceSameTabNavigation: <boolean>
# 桥接模式,可选,默认 false,可以为 'newTabWithUrl' 或 'currentTab'。更多详情请参阅后文
bridgeMode: false | 'newTabWithUrl' | 'currentTab'
# 是否在桥接断开时关闭新创建的标签页,可选,默认 false
closeNewTabsAfterDisconnect: <boolean>
# 在调用 aiAction 时发送给 AI 模型的背景知识,可选
aiActionContext: <string>
tasks
tasks 部分是一个数组,定义了脚本执行的步骤。记得在每个步骤前添加 - 符号,表明这些步骤是个数组。
flow 部分的接口与 API 几乎相同,除了一些参数的嵌套层级。
tasks:
- name: <name>
continueOnError: <boolean> # 可选,错误时是否继续执行下一个任务,默认 false
flow:
# 自动规划(Auto Planning, .ai)
# ----------------
# 执行一个交互,`ai` 是 `aiAction` 的简写方式
- ai: <prompt>
# 这种用法与 `ai` 相同
- aiAction: <prompt>
# 即时操作(Instant Action, .aiTap, .aiHover, .aiInput, .aiKeyboardPress, .aiScroll)
# ----------------
# 点击一个元素,用 prompt 描述元素位置
- aiTap: <prompt>
deepThink: <boolean> # 可选,是否使用深度思考(deepThink)来精确定位元素
# 鼠标悬停一个元素,用 prompt 描述元素位置
- aiHover: <prompt>
deepThink: <boolean> # 可选,是否使用深度思考(deepThink)来精确定位元素
# 输入文本到一个元素,用 prompt 描述元素位置
- aiInput: <输入框的最终文本内容>
locate: <prompt>
deepThink: <boolean> # 可选,是否使用深度思考(deepThink)来精确定位元素
# 在元素上按下某个按键(如 Enter,Tab,Escape 等),用 prompt 描述元素位置
- aiKeyboardPress: <按键>
locate: <prompt>
deepThink: <boolean> # 可选,是否使用深度思考(deepThink)来精确定位元素
# 全局滚动,或滚动 prompt 描述的元素
- aiScroll:
direction: 'up' # 或 'down' | 'left' | 'right'
scrollType: 'once' # 或 'untilTop' | 'untilBottom' | 'untilLeft' | 'untilRight'
distance: <number> # 可选,滚动距离,单位为像素
locate: <prompt> # 可选,执行滚动的元素
deepThink: <boolean> # 可选,是否使用深度思考(deepThink)来精确定位元素
# 数据提取
# ----------------
# 执行一个查询,返回一个 JSON 对象
- aiQuery: <prompt> # 记得在提示词中描述输出结果的格式
name: <name> # 查询结果在 JSON 输出中的 key
# 更多 API
# ----------------
# 等待某个条件满足,并设置超时时间(ms,可选,默认 30000)
- aiWaitFor: <prompt>
timeout: <ms>
# 执行一个断言
- aiAssert: <prompt>
# 等待一定时间
- sleep: <ms>
- name: <name>
flow:
# ...
总结
通过 MidSceneJS + AI模型 的组合,测试工程师可以无需编写复杂代码,快速生成可读性强的测试脚本,突破传统自动化测试的局限性,直接验证视觉与语义内容,无缝对接Playwright:结合成熟的浏览器控制能力,覆盖Web/APP/H5全场景。
另外从 Midscene v0.14.0 开始,工具引入了两个新功能:即时操作(Instant Actions)和深度思考(Deep Think)。
即时操作(Instant Actions)- 让交互表现更稳定
例如,当进行搜索时,你可以这样做:
await agent.ai(‘在搜索框中输入 “Headphones”,按下回车键’);
在接口的背后,Midscene 会调用 LLM 来规划步骤并执行它们。你可以在报告中看到整个过程。这是一个非常常见的 AI Agent运行模式。
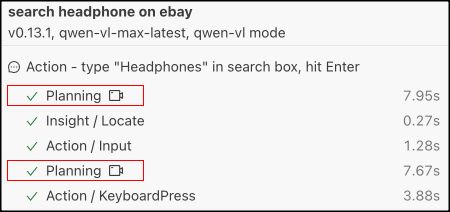
当在 AI 模型中使用复杂 prompt 时,一些 LLM 模型可能规划出错误的步骤,或者返回元素的坐标不准确。
为了解决这个问题,引入了 aiTap(), aiHover(), aiInput(), aiKeyboardPress(), aiScroll() 接口。这些接口会直接执行指定的操作,而 AI 模型只负责底层任务,如定位元素等。使用这些接口后,整个过程可以明显更快和更可靠。
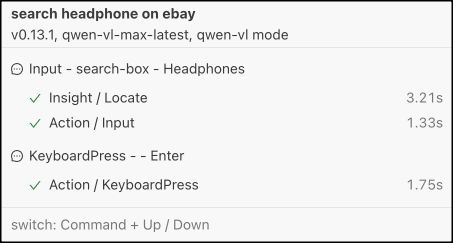
例如,上面的搜索操作可以重写为:
await agent.aiInput(‘耳机’, ‘搜索框’);
await agent.aiKeyboardPress(‘Enter’);
在报告中,你会看到现在已经没有了规划 (Planning) 过程:
深度思考(Deep Think)- 让元素定位更准确
当使用 Midscene 与一些复杂的 UI 控件交互时,LLM 可能很难定位目标元素。一个新的选项 deepThink(深度思考)引入到即时操作接口中。
await agent.aiTap(‘target’, { deepThink: true });
deepThink 是一种策略。它会首先找到一个包含目标元素的区域,然后“聚焦”在这个区域中再次搜索元素。通过这种方式,目标元素的坐标会更准确。
deepThink 只适用于支持视觉定位的模型,如 qwen2.5-vl。如果你使用的是像 gpt-4o 这样的模型,deepThink 将无法发挥作用。