最最最详细的梯度下降与代价函数,公式理解+可视化~
文章目录
- 前言
- 一、线性回归
- 二、代价函数与梯度下降
-
- 1.代价函数
- 2.梯度下降
- 代码与可视化~
- 总结
前言
本文将对线性回归中的代价函数,梯度下降公式及其可视化进行研究,让我们一起入门机器学习叭~
一、线性回归
利用数理统计中回归分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法
通俗来讲,就是用一条最适合的一次函数(如y = wx + b) 去拟合现有的数据,并用这条直线去预测某一个x值对应的y值。
例如:3r,5r,7r分别可以买1,2,3个面包,那小明带了9r预计可以买几个面包?
对于一个小学生可能会举起手来说买4个面包!但是电脑可不会举手回答,那我们该如何让电脑学会回答这类问题呢?
二、代价函数与梯度下降
如果你问小学生为什么会回答四个面包呀,ta会和你说因为只要花2r就可以多买一个面包,也就是说买面包价格函数为y = 2x + 1,y = 9 x自然就为4个。
那么我们接下来就来探讨一下如何让电脑学会获得y中的2x + 1
也就是让电脑学会根据数据集计算 y ^ = w x + b \hat y = w x + b y^=wx+b中 w w w和b的值
1.代价函数
损失函数(Loss Function):定义在单个样本上,计算一个样本的误差。
代价函数(Cost Function):定义在整个训练集上,是所有样本误差的平均。线性回归通常也采用最小二乘法求解参数
这里我们采用代价函数而不使用损失函数(随机梯度下降(SGD))。
理解概念:通过计算整个样本在当前预测值与实际值的差别
( y ^ i − y i \hat y_{i} - y_{i} y^i−yi),整体差别越大的代表代价越大,也就是当前的模型拟合效果不行,下面为代价函数的完整版
J ( w , b ) = 1 2 n Σ i = 0 n ( y ^ i − y i ) 2 J(w, b) = \frac{1}{2n}{\Sigma^{n}_{i=0}(\hat y_{i} - y_{i})^{2}} J(w,b)=2n1Σi=0n(y^i−yi)2
n为样本的数量,最小二乘法体现在
- 最小:整体的差别越小代价越小,模型拟合程度也越好
- 二乘:开平方计算代价
那么我们该如何优化y = wx + b 中的权重w与参数b,使得代价函数最小呢
2.梯度下降
梯度,可以认为是函数在某一点的斜率,例如下图中红色点点和黄色点点
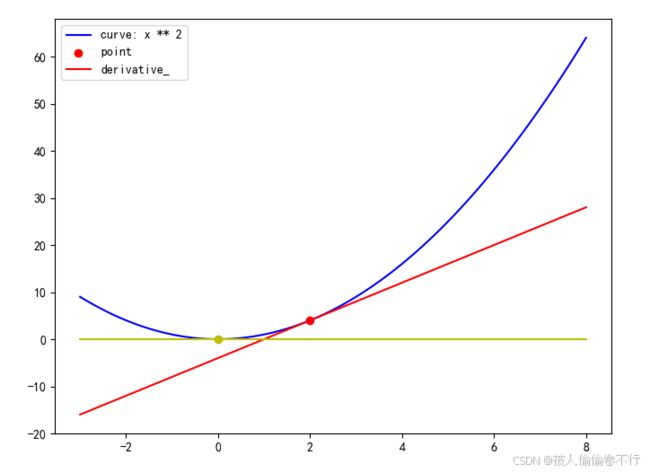
我们发现,当切线斜率接近为0(黄色线线)时,将会使得其值最小,这个点也叫做极值点,当左边切线斜率小于0,右边切线斜率大于0,则为极小值点,反之则为极大值点(高中知识)
最小的极小值点也就是我们要求的答案——代价函数的最小值
所以所谓的梯度下降,就是参数沿着代价函数切线斜率逼近0(极小值点)的方向前进
那么该如何让程序学会梯度下降呢,引入梯度下降的公式
w = w − α ∂ J ( w , b ) ∂ w w = w - \alpha \frac{\partial{J}(w, b)}{\partial{w}} w=w−α∂w∂J(w,b)
b = w − α ∂ J ( w , b ) ∂ b b = w - \alpha \frac{\partial{J}(w, b)}{\partial{b}} b=w−α∂b∂J(w,b)
α \alpha α为学习率, ∂ \partial ∂为偏导,请记住 w , b w,b w,b是同时更新的
根据 J ( w , b ) = 1 2 n Σ i = 0 n ( y ^ i − y i ) 2 J(w, b) = \frac{1}{2n}{\Sigma^{n}_{i=0}(\hat y_{i} - y_{i})^{2}} J(w,b)=2n1Σi=0n(y^i−yi)2
因为 y ^ = w x + b \hat{y} = w x + b y^=wx+b进行偏导可得,对w偏导还有x,而对b偏导则为1
∂ J ( w , b ) ∂ w = 1 n Σ i = 0 n ( y ^ i − y i ) x \frac{\partial{J}(w, b)}{\partial{w}} = \frac{1}{n}\Sigma^{n}_{i=0}(\hat y_{i} - y_{i})x ∂w∂J(w,b)=n1Σi=0n(y^i−yi)x
∂ J ( w , b ) ∂ b = 1 n Σ i = 0 n ( y ^ i − y i ) \frac{\partial{J}(w, b)}{\partial{b}} = \frac{1}{n}\Sigma^{n}_{i=0}(\hat y_{i} - y_{i}) ∂b∂J(w,b)=n1Σi=0n(y^i−yi)
接下来来解析一下梯度下降公式的后半截:
- 学习率有什么用
- 学习率就好比迈出去的步子,步长很大时就容易拉到胯(,导致反复横跳,左脚踩右脚最终获取的点梯度为无穷
所以学习率不能太高;但学习率低了会导致步子太小,也就意味着得很久才能到达最小值点。所以可以多尝试不同的学习率以找到最佳的方案
- 学习率就好比迈出去的步子,步长很大时就容易拉到胯(,导致反复横跳,左脚踩右脚最终获取的点梯度为无穷
- 为什么需要单独偏导
- 因为单独偏导只看该变量对代价函数造成的影响(如偏导为正,在其他变量不变得情况下则函数值,会随该变量上升值上升),由此引导模型参数朝着代价函数最小化的方向更新
- 偏导正负是否会对梯度下降造成影响
- 举出所有例子就明白力
-
当偏导为正,此时 w = w − α ∂ J ( w , b ) ∂ w w = w - \alpha \frac{\partial{J}(w, b)}{\partial{w}} w=w−α∂w∂J(w,b),学习率 α \alpha α为大于0得数,偏导也大于0, w = w − 大于 0 的数 w = w - 大于0的数 w=w−大于0的数,所以w在递减,沿着梯度下降趋于0(极小值点)的方向前进
-
当偏导为负,此时学习率 α \alpha α为大于0,与小于0的偏导相乘小于0, w = w − 小于 0 的数 w = w - 小于0的数 w=w−小于0的数,此时w就会变大,沿着梯度上升到趋于0(极小值点)的方向前进
- 因为极小值点的偏导接近0,所以步子会迈的越来越小,最终反复横跳逼近极小值点(当然如果学习率大就会左脚踩右脚导致偏导无穷)
代码与可视化~
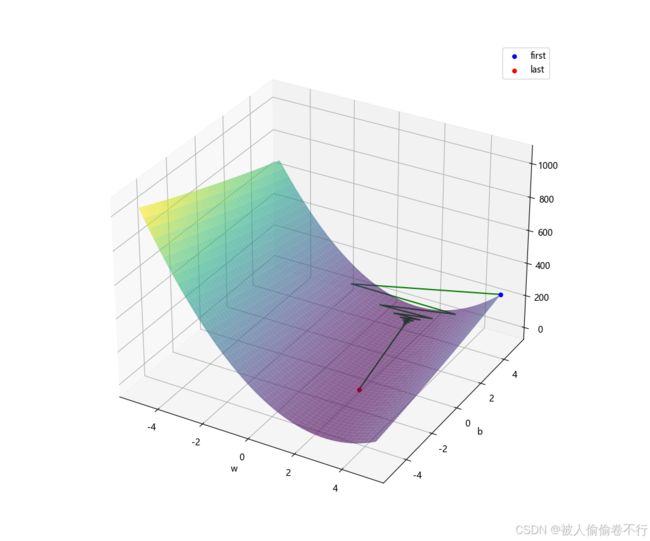
这里给出已经做好的梯度下降可视化与代码~
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
# 以下内容为画图必加,防止中文内容无法显示
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
np.random.seed(42) # 设置固定种子,保证结果复现
# 初始化一个y = 2.3 x - 1.3的一次函数
x = np.linspace(0, 10, 100) # 常用的numpy函数设置x范围
y = 2.3 * x - 1.3 + np.random.randn(100) # 构建y函数并设置噪音
w = np.linspace(-5, 5, 1000)
b = np.linspace(-5, 5, 1000)
w_mesh, b_mesh = np.meshgrid(w, b) # 获取w和b的所有参数组合,相当于排列组合的所有可能集合
def j(w, b):
# 点对应的代价函数
return np.mean((w * x + b - y) ** 2) / 2
def J(w, b):
# 这里本质上是w的shape(1000,1000,1)与x的(100,1)的维度相互对应可以直接广播,相乘后得到(1000,1000,100),在axis=2也就是对每一个第二维度(行维度)取平均,也就是对每一行对应100个x下的代价函数J值取平均,获得所有可能的w与b的组合下对应的代价函数J值
return np.mean((w[:, :, np.newaxis] * x + b[:, :, np.newaxis] - y) ** 2, axis=2) / 2
def derivative(w, b):
# 获得w与b的偏导
return np.array([np.mean((w * x + b - y) * x), np.mean((w * x + b - y))])
def baby_move(start, learning_rate, iter_round):
points = [start] # 设置路径列表,将初始点加入
start_point = start # 设置开始点
for _ in range(iter_round): # 迭代次数
derivative_ = derivative(start_point[0], start_point[1]) # 获取开始点对应的偏导数值
next_point = start_point - learning_rate * derivative_ # 通过数组广播,同时相减,对应得到w,b的更新值
points.append(next_point) # 加入下一个途径点
start_point = next_point # 设置该途径点为开始点
return np.array(points) # 返回路径
# 初始化参数
fig = plt.figure(figsize=(8, 6))
path = baby_move([5,5], 0.05, 2000)
point = np.array([(i[0], i[1], j(i[0], i[1])) for i in path]) # 获得路径点对应的坐标
sub = fig.add_subplot(111, projection='3d')
sub.plot_surface(w_mesh, b_mesh, J(w_mesh, b_mesh), cmap='viridis', alpha=0.6) # 绘制曲面
sub.scatter(point[0, 0], point[0, 1], point[0, 2], color="blue", label="first") # 绘制起始点
sub.scatter(point[-1, 0], point[-1, 1], point[-1, 2], color="red", label="last") # 绘制终止点
sub.plot(point[:, 0], point[:, 1], point[:, 2], color="green") # 绘制路径图
plt.xlabel("w")
plt.ylabel("b")
plt.legend()
plt.show()
再加一小部分与sklearn的线性回归对比代码~
可以看出数值差别灰常小,api就是调用线性回归函数的结果
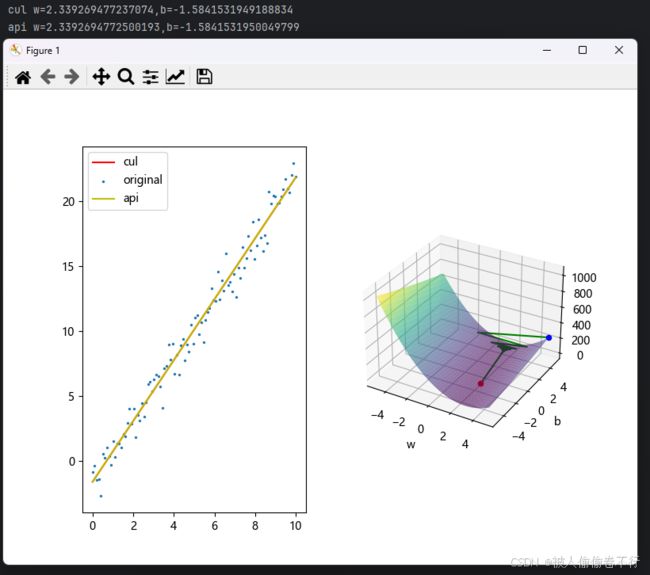
sub1 = fig.add_subplot(121)
w, b = point[-1, 0], point[-1, 1]
plt.plot(x, w * x + b, c="r", label="cul")
plt.scatter(x, y, s=2, label="original")
model = LinearRegression()
model.fit(x.reshape(-1, 1), y)
plt.plot(x, model.predict(x.reshape(-1, 1)), c="y", label="api")
print("cul w={},b={}\napi w={},b={}".format(w, b, model.coef_, model.intercept_))
plt.legend()
plt.show()
总结
本文主要讲述了线性回归中的梯度下降与代价函数,并给出代码解释,适合初学者
接下来也会继续更新机器学习~