hello world是怎样运行的?
关于《深入理解计算机系统》
“这本书的中译名为“深入理解计算机系统”,我非常,十分,以及百分之一百二十地不满意。我这么说的原因在于这个译法完全扭曲了书的本意。如果直译原书名,应该是类似于“以程序员的视角理解计算机系统”,何来“深入”二字。可能在国内编辑看来,这是讲系统的,用C和汇编语言的,因此很“深入”,但我认为这只能说明国内技术氛围的浅薄。因为事实上,这是一本入门级别的书,这本书其实并不“深入”,它谈论的内容还是相对比较浅的。但“浅”不代表“浅薄”,写一本面向初学者的好书往往是非常困难的,因此无论是SICP还是CSAPP,它的作者都是顶尖学府的教授,结合多年教学经验而写出来的。
CMU把这本书作为“Introduction to Computer System”课程的教材,是面向计算机专业低年级学生的“计算机系统介绍(导论)”,可能这些学生只是刚刚了解如何使用一门高级语言——如Java进行编程,对于计算机系统的工作方式等话题可谓一点都没有接触过,而CSAPP对读者的背景也只要求是“一些编程经验”而已。这本书的话题覆盖面很广,从计算机的基本组成,二进制数据表示方式,到机器级别的指令,CPU工作方式,存储结构和优化,操作系统的虚拟内存管理,程序运行方式,I/O,网络、到(较底层)程序性能优化和并行程序开发等等。所以,它其实覆盖了“计算机组成原理”,“操作系统”等许多课程的内容,其中的许多话题都能再次展开,继续深入,都能再变成一本,甚至N本经典。事实上,在高年级的计算机专业课程设置中,都会有更加纵向的内容出现。” ——摘自Jeffrey Zhao博文
老赵的这一番话,值得深思,这本书用怎么说呢,并不是深入,而是涉及的知识比较广,但又都是广大程序猿不得不知道的知识,下面我们就来慢慢品尝这本书吧。言归正传,接下来,享读《Computer Systems: A Programmer’s Perspective》的中hello world程序都干了些啥。
1.信息在计算机的中表示
当我们输入以下程序,编译运行,计算机从屏幕输出hello, world。整个过程计算机都怎么运作的呢?
#include <stdio.h>
int main()
{
printf("hello, world\n");
}
我们知道,信息在计算机中都是用0或1表示的。计算机通过这些位信息以及上下文来解读这些0/1。也即:计算机中的信息=位+上下文。
我们输入的hello程序就是由0、1组成的序列,将这些位8位组织成一个字节,每个字节用来表示一个文本字符。ASCII码给出了一种字符与数字的一一对应关系。
hello, world程序以字节方式存放于文件中,如下图所示。其每个字符对应一个数字,具体可参考ASCII码表。

图1 Hello world程序的ASCII码表示
2.将程序翻译成机器可读的格式
因为我们输入的hello, world程序是人可读的,机器并不能直接识别它们。我们需要把这些文字翻译成机器可执行的二进制文件。这一部分的工作是由编译系统完成的。编译系统由预处理器、编译器、汇编器、连接器四部分组成。以hello, world程序为例,各部分共同完成将源文件编译成二进制可执行文件。各个部分完成的具体工作如下:
l 预处理器:根据以#开头的命令,修改源程序。如根据#include <stdio.h>行,预处理器读取系统头文件stdio.h中的内容,代替此行内容。源程序经过预处理后,得到另一个c程序,此程序通常以.i为后缀保存。
l 编译器:将预处理后的.i文件转换成汇编程序。编译器将不同的高级语言(如c语言,C++语言)转换成严格一致的汇编语言格式进行输出。汇编语言以标准的文本格式确切的描述每机器语言指令。编译器得到的文件通常以.s为后缀保存。
l 汇编器:将汇编语言(.s文件)翻译成机器语言指令,并将这些指令打包成一种可定位目标程序格式。汇编后得到的文件即为二进制文件,通常以.o为后缀。
l 链接器:hello, world程序中调用过printf函数,它是一个c标准库里的函数。Printf函数存放在一个名为printf.o的单独预编译的文件中。而这个文件必须以适当的方式并入到我们的程序中,这个工作由链接器完成。将外部的.o文件并入后,得到一个完整的hello, world可执行文件。可执行文件加载到存储器后,由系统复制执行。
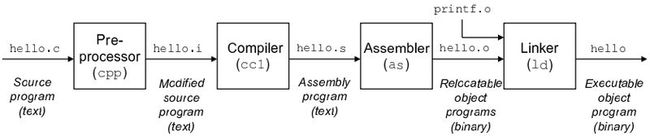
图2 编译系统
在linux系统上,输入编译命令行:
Viidiot>gcc hello.c -o hello
将执行上图所示的四个步骤,得到可执行二进制文件hello。
3.处理器读取并解释存储在存储器中的指令
Shell:命令行解释器,为用户提供了一只与系统打交道的方式。它等待用户的输入,当用户输入一行命令后,shell先判断它是不是一个shell内置命令,如果不是,shell会假定用户输入为一个可执行文件的名字,从而去加载并执行该文件。因此,当我们通过编译系统将源文件编译成可执行二进制文件后,在shell中输入我们得到的可执行二进制文件名,shell将其从磁盘中加载到存储器(注:我们的可执行文件是存放在磁盘上的),并通过处理器进行解释执行,得到最终的结果,输出到终端(显示器)上进行显示。自此,我们的hello, world程序完成了其生命周期。
4.计算机系统硬件结构
为了弄清楚hello, world运行时,系统究竟发生了什么,我们先来了解下一个典型的计算机硬件结构。
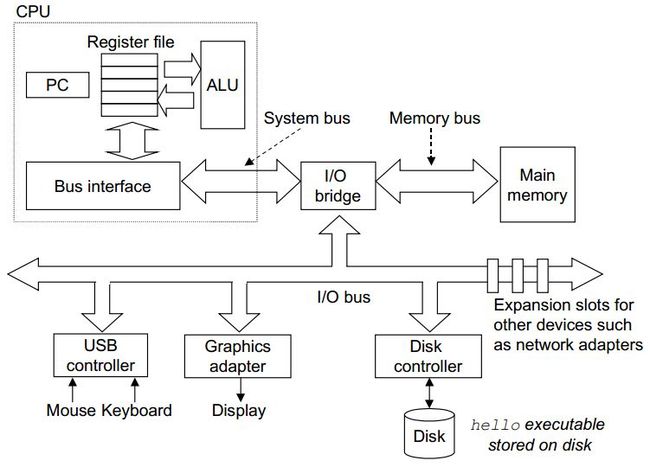
图3 典型的计算机硬件构成
【CPU:中央处理器 ALU:算术/逻辑运算单元 PC:程序计数器 USB:统一串行接口】
下面简单说一下各个部件在系统中所起的作用。
总线:在各个部件之间传输数据。现在的总线宽度一般为32位或者64位,即一次传输的数据为4字节或者8字节。
I/O设备:IO设备是系统与外界通信的通道,如鼠标,键盘,显示器都是典型的IO设备。
主存储器:简称主存,是处理器执行程序时用于临时存放程序及其数据。主存由一组动态随机存储器芯片组成。
处理器:解释执行存储在主存中的指令。其内部包含一个双字节程序计数器(PC),任何时候PC中都存放着接下来要执行的机器指令在主存中的地址。
处理器的操作主要是围绕PC、ALU、主存来进行运作的。处理器首先从PC所指向的主存存储单元读取指令,解释指令中的位,执行该指令指示的简单操作,然后更新PC寄存器,使其指向下一条要执行的指令。CPU会执行的操作有:
加载:把一个字节或一个字从主存复制到寄存器,覆盖掉寄存器中原来的值。
存储:把一个字节或一个从寄存器复制到主存,并覆盖主存中原来的值。
操作:把两个寄存器的内容复制到ALU,ALU对两个字做算术运算后存回其中的一个寄存器,该寄存器中原来的值会被覆盖。
跳转:从cpu执行的指令抽取一个字的内容存入PC,覆盖掉原来的值,从而改变下一条要执行的指令,达到跳转的目的。
在了解了一些基本的硬件结构,以及各个部分的作用后,我们再来看看之前的hello, world程序的运行过程。
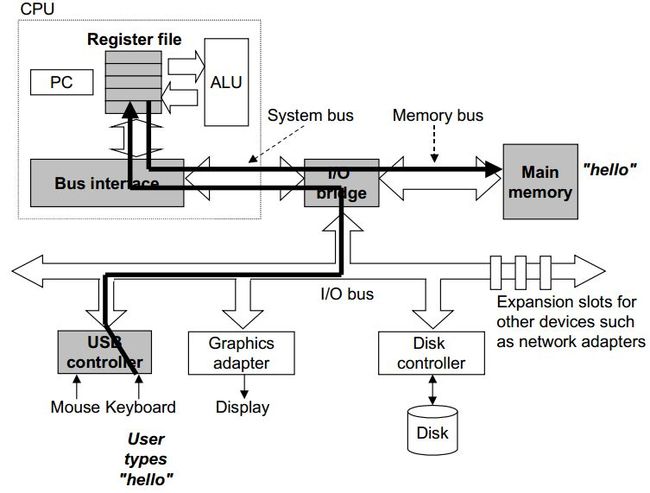
图4 加载可执行文件到主存的过程
在linux系统下,我们在shell中敲入以下命令
Viidiot>./hello
由于shell没有内置hello命令,因此shell将我们输入的hello视为一个可执行文件,从而通过执行一系列机器指令,将可执行文件hello从磁盘复制到主存,如图4所示。
注意,如果通过DMA方式加载程序,则不需要通过CPU,而是将hello可执行文件直接从磁盘复制到主存,示意图如图5。
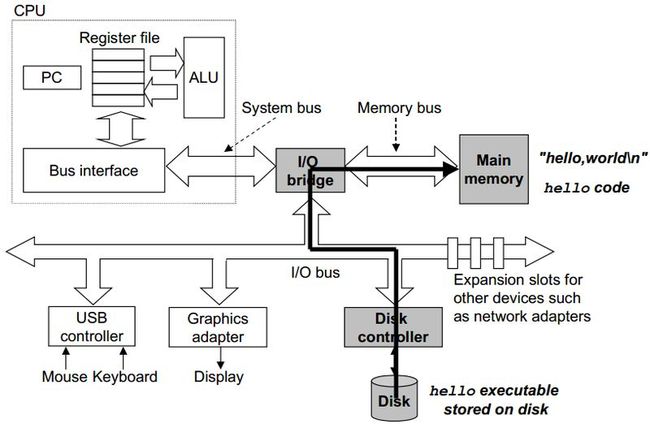
图5 DMA方式加载程序到主存
可执行程序加载到主存后,cpu就执行hello程序的机器指令,而这些指令完成的工作便是将”hello,world\n”这几个字符从主存中复制寄存器文件中(register file),再将其从寄存寄文件中复制到显示设备上进行显示。过程示意图如图6所示。
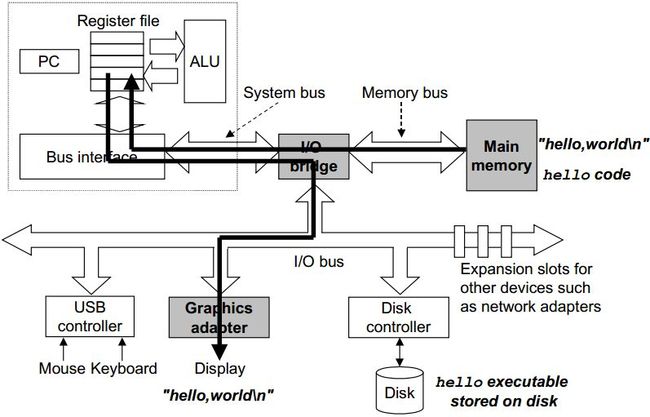
图6 cpu执行指令,将 “hello,world\n”从内存复制到显示设备
至此,hello,world程序的执行过程已经完成。
题外话:
从上面的程序实例我们可以看到,程序花费了大量的时间将数据从一个部件复制到另外一个部件。程序加载时,将hello程序的机器指令从磁盘复制到主存,程序运行时,又将其从主存复制到cpu,最后又从cpu复制到外部显示器。将根据机械原理,大容量的存储设备速度比小容量存储设备慢,快速设备的造价比慢速设备的造价高。对于计算机硬件系统,CPU的速度远高于主存的速度,而主存的速度远高于磁盘,不同部件的速度严重不对等,从而快的设备的性能没能得到充分发挥。为解决各类设备速度不匹配的问题,引入了高速缓存设备来缓解速度匹配问题。如图7所示,为加入了高速缓存后的系统部分结构。
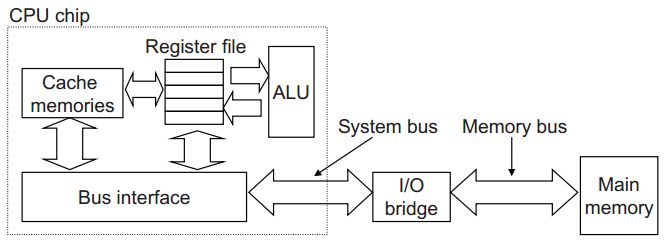
图7 高速缓存存储器
现代计算机为提高系统性能,一般都加入了多级缓存结构。高速缓存采样的是静态随机存储器硬件(SRAM)技术,速度快于主存(采样动态随机存储器技术)。如图8是存储器结构金字塔,越往上速度越快,造价也更昂贵。

图8 存储器金字塔
作者:Viidiot 微信公众号:linux-code