摘要: 之前我写了几篇关于DDD的介绍和一些小例子说明,我想这对于介绍DDD还是有些模糊,甚至还不知道怎么用DDD来分析设计。昨天和园友讨论也发现没有例子很难说明,所以今天我模拟了一个案例,同时这个案例也是真实的。在写此文时我并没有给出最终的解决方案,是用来和园友交流的,我会不定时把我们讨论的结果作更新,如...
阅读全文
用CQRS+ES实现DDD
这篇文章应该算是对前三篇的一个补充,在写之前说个题外话,有园友评论这是在用三层架构在写DDD,我的个人理解DDD是一种设计思想,跟具体用什么架构应该没有什么关系,DDD也需要分层,也有三层架构的影子在里面。三层架构主要是表现层、业务层和数据层,而DDD已经没有数据层,三层结构里的模型是贫血的,而DDD却是充血的。如果你在用三层框架已经有了聚合,实体,值对象的概念,那说明你已经在靠近DDD了,或者你不愿相信罢了,当然你可以保留自己的观点,这里不作争论,我也不能作出结论,我个人是觉得这种讨论也是有意义的,我也会思考之前所介绍的到底是不是DDD,这个答案留给各位读者吧。总之欢迎形式各样的评论。
接下来我就来介绍一下CQRS(命令和查询职责分离 )风格的框架。在学习CQRS的时候,有很多人说这个太高大上,难以应用。我想说CQRS不是那么可怕,当然也不是那么简单。那么就开始慢慢来揭开面纱。首先还是先看看经典DDD在Application层是这么做的,先定义一个接口

public interface IUserService
{
UserDTO GetUserInfo(string userId);
IEnumerable<UserDTO> GetAllUsers();
void RegisterUser(UserDTO userData);
void ModifyContactInfo(UserDTO userData);
void ModifyPassword(string userId, string oldPwd, string newPwd);
}
通过代码会发现定义的接口有一点点规律,要么是有返回值,要么就是没有返回值的,那么他们有什么特点呢?请注意我在写代码的时候特意在两个接口之间加了回车以区分,上面两个主要为了返回数据,是查询,下面三个其中一个是创建数据,剩下的是修改数据,是命令。也就是说一个方法要么是执行某种动作的命令,要么是返回数据的查询且查询不应该会影响数据,不可能两者同时存在(可能你并不认同,有一种情况是特殊的,就是当实体标识由数据库来提供的,那么有时我们需要知道它的标识,但我也建议该方法不应该有返回值,可以用out,或者是给传输对象进行赋值,在有些环境下后一种也并不能解决),也就类似一次向服务器发送url请求时,要么是get,要么是post,不可能即是get,又是post。
当前接口只定义了一个DTO,该DTO的描述可能会过于宏大,只有当我们知道需要调用哪个接口时才会知道此DTO有哪些数据,于是当ui层去对DTO赋值往往也会不知所措,你是不是有针对不同的接口去定义相应的DTO的想法呢?至少我有,那么这样的DTO和接口是不是具有相同功能的表达呢?我已经开始会将上页分成两个接口了
再来说说查询,查询主要是为了ui呈现数据,经典DDD的查询一般都是通过repository(具体实现很多情况下会选择orm),然后将domain model转成dto,这种方式限制很大,对于一些复杂数据就会显得很难,如当要查看一个user信息时还要展示他的role信息,这样就需要通过repository先查出user,然后再通过user.RoleID再查询role,最终数据转换成ui需要的model,应用层开发就会有点繁琐了,不如关系数据库一句sql来的方便。当然,现在的orm(如nh、ef)提供了级联查询,这样就会在user上定义一个role属性,虽然是方便了很多,但是这样的回报也仅仅是为了查询,对于我们跟踪状态一点用也没有,为什么?当一个用户修改角色时,需要role对象吗?不需要,只需要他的ID,因此在聚合之间的引用应该尽量用引用ID,而不是引用对象,所以聚合之间尽量低耦合,“低耦合高内聚”这个标准也能够更好进行模块式开发。再有一些汇总查询,估计repository实现人员快要疯了,写应用层的人估计更要疯,呵呵。使用orm带来的好处是显而易见的,但是面对查询,orm并不是那么完美,尽管现在的orm查询功能已经很强大。经过以上阐述你可能有了一点想法,让查询绕开仓储。
接下来就开始CQRS吧。不细说查询了,在上述接口重新定义一个名称叫做IUserQuerySerice,我已经开始注重命名了,去掉里面的命令方法就行了。那么只要针对ui展示数据用的查询DTO就行了,他也可以叫ReadModel(只读模型),我个人觉得这个叫法更合适一点。那么实现你用数据库视图也行,用sql也好,达到目的就行。还要就是需要定义多少ReadModel,这个仁者见仁,智者见智。
重点是命令处理,为C端设计一个接口
public interface ICommandBus
{
void Send(ICommand command);
}
就这么简单,但是这带来了需要大量写Command,即每有一个操作就需要定义一个命令模型,然后还要写该命令对应的处理器,还是拿之前的用户注册的例子来演示代码吧
public class RegisterUserCommand : ICommand
{
public string Name { get; set; }
public string Password { get; set; }
public string Email { get; set; }
}
public class RegisterUserHandler : ICommandHandler<RegisterUserCommand>
{
private readonly IRegisterUserService _registerUserService;
private readonly IUserRepository _userRepository;
public void Handle(RegisterUserCommand command)
{
User user = _registerUserService.RegisterNewUser(command.Name, command.Password, command.Email);
_userRepository.Add(user);
}
}
这种架构风格带来了大量的代码工作,就是需要定义很多Command。CommandBus的具体实现就是运用了订阅/发布,即一个Command发送过来,系统会去找对应的CommandHandler,这样的代码写起来会显示更干净。
CQRS不是一个让你觉得是多么炫丽的架构,他的这种复杂性其实也是合理的,因为他是为了解决数据显示的复杂性。
接下来我就说说ES。什么是ES?全称是Event Sourcing,事件源。在未用ES之前,数据库中保存的聚合只是最后一次完整状态的数据,他不能反应聚合的历史变迁,除非你使用了其他的方式。还记得之前我稍微说了一下事件驱动吗?用了ES,必然要有事件驱动的(目前为止我还没有其他好的方式),而且还要接受最终一致性。什么是最终一致性?后面再说吧。还是用代码演示,在这里还是用户注册,为了方便这里用户密码就先不加密了,领域内的代码大致就这些
public class UserCreated : IDomainEvent
{
public UserCreated(string name, string password)
{
this.Name = name;
this.Password = password;
}
public string SourceId { get; set; }
public int Version { get; set; }
public string Name { get; private set; }
public string Password { get; private set; }
}
public class User : IAggregateRoot
{
private readonly IList<IDomainEvent> _uncommittedEvents = new List<IDomainEvent>();
IEnumerable<IDomainEvent> IAggregateRoot.Events
{
get { return this._uncommittedEvents; }
}
public User(string id)
{
this.Id = id;
}
public User(string name, string password)
: this(Guid.NewGuid().ToString())
{
OnUserCreated(new UserCreated(name, password));
}
private void OnUserCreated(UserCreated @event)
{
@event.SourceId = this.Id;
@event.Version = this.Version + 1;
Handler(@event);
this.Version = @event.Version;
_uncommittedEvents.Add(@event);
}
private void Handle(UserCreated @event)
{
this.Name = @event.Name;
this.Password = @event.Password;
}
void IAggregateRoot.LoadFrom(IEnumerable<IDomainEvent> events)
{
foreach (var @event in events) {
Handle(@event);
this.Version = @event.Version;
}
}
public string Id { get; private set; }
public int Version { get; private set; }
public string Name { get; private set; }
public string Password { get; private set; }
}
public class IRepository
{
T Get<T>(string id) where T : class, IAggregateRoot;
void Save<T>(T aggregate, string commandId) where T : class, IAggregateRoot;
}
不知道上面的代码你能不能够大致明白。在这里仓储的功能更为有限,只有获取和保存聚合。当new一个user时会产生个事件,同时为事件记录一个版本号,聚合会得到最终的版本号,而且状态的修改是由事件驱动的。这个时候我们还看不出来事件的作用。别急,简单看下仓储的实现。保存聚合到底发生了什么
public class SourcedEvent
{
public SourcedEvent(string aggregateId, string aggregateName, int version)
{
this.AggregateId = aggregateId;
this.AggregateName = aggregateName;
this.Version = version;
}
public string AggregateId { get; private set; }
public string AggregateName { get; private set; }
public int Version { get; private set; }
public string Payload { get; set; }
public string CorrelationId { get; set; }
}
public class EventSourcedRepository : IRepository
{
public void Save<T>(T aggregate, string commandId) where T : class, IAggregateRoot
{
var events = aggregate.Events
.Select(@event => new SourcedEvent(aggregate.Id, typeof(T).Name, @event.Version) {
CorrelationId = commandId,
Payload = _serializer.Serialize(@event)
}).ToArray();
using (var connection = new SqlConnection()) {
using (var trans = connection.BeginTransaction()) {
try {
foreach (var @event in events) {
//TODO添加事件sql
}
trans.Commit();
}
catch (Exception) {
trans.RollBack();
throw;
}
}
}
_eventBus.Publish(aggregate.Events);
}
}
你会看到此时保存的仅仅是事件,持久化成功了,会将事件发布出去。这样C端的写数据库设计可以简单到只需要记录Events的一张表。而且最大的好处在于只会对event进行insert,还是就是他的存储介质不一定就需要db,甚至文本文件都行(为每个聚合创建一个文件,然后将事件追加,多么简单),想想都会兴奋,有点颠覆吧。
然后你再写个同步读数据库的EventHandler,还是再贴上代码,已经写了这么多了,不在乎再写一个了
public class UserDataSyncHandler : IEventHandler<UserCreated>
{
public void Handle(UserCreated @event)
{
string sql = string.Format("insert user(id, name, password) values('{0}','{1}','{2}')",
@event.SourceId, @event.Name, @event.Password);
}
}
至此,大致做法已经介绍完了。在这过程中你会发现用了CQRS+ES架构,可以完全抛弃ORM了,喜欢写sql的伙伴们可能会更兴奋,也许会和我一样想说“ORM我早就看你有点不爽了”,呵呵。还要说明一下前面所说的最终一致性,就是C端的事件持久化完时此时Q端的数据并没有同步过来,会存在一点延迟,但这种延迟不会太久,甚至会感觉不到。到了这里我还要有一个感触就是有了这样的架构去实现DDD,你还认为聚合模型就是数据模型吗?或者说他俩是同胞兄弟吗?
最后再展示下如何通过事件还原聚合,还是上代码吧,谁让我如此喜欢用代码来描述呢
public class EventSourcedRepository : IRepository
{
public T Get<T>(string id) where T : class, IAggregateRoot
{
IEnumerable<IDomainEvent> events;
using (var connection = new SqlConnection()) {
//TODO聚合名称和聚合ID取出事件并对版本号进行升序
}
var aggregate = (T)Activator.CreateInstance(typeof(T), id);
aggregate.LoadFrom(events);
return aggregate;
}
}
这样聚合就可以还原到最后一次的状态了。就像以前的电影胶片一样,每个事件对应着一个画面,放完了也就完了。
通过上面的介绍,你应该会了大致的了解了,现在来看这张图估计你就不会觉得有多么高大上了(先跳过wcf)
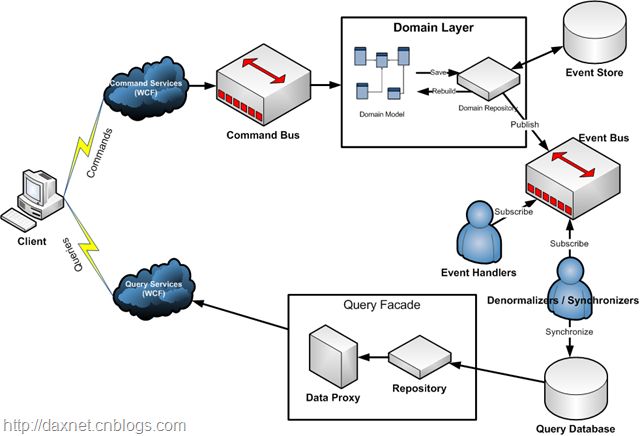
CQRS+ES的结合带来了很大的亮点,但是要应用考虑的会很多,复杂度也会很大,如果同步数据,如果事件丢了怎么办?产生的事件执行顺序跟我们的预期不一样怎么办?遇到并发怎么办?实体的id生成策略等等好多问题。有了问题自己的知识范围也会扩大和提高。总之,CQRS+ES可讨论的太多了,我也无法一一列举。就先写到这儿了,这一篇应该是这周最长的一篇了,明天周末了,歇两天。
摘要: 这篇文章应该算是对前三篇的一个补充,在写之前说个题外话,有园友评论这是在用三层架构在写DDD,我的个人理解DDD是一种设计思想,跟具体用什么架构应该没有什么关系,DDD也需要分层,也有三层架构的影子在里面。三层架构主要是表现层、业务层和数据层,而DDD已经没有数据层,三层结构里的模型是贫血的,而DD...
阅读全文
摘要: 写这篇文章主要是之前三篇对DDD的介绍算是自己学习的一次试水,也希望能够有更多的人能帮我发现其中的问题。昨天继续阅读了DDD书,发现了自己之前的例子存在了一些问题,早上也和园友进行了一些讨论。最后整理出此文,还记得第一篇用户注册是怎么做的吗?再次回顾一下,但也有一点变化,为了更好的符合DDD, 这次...
阅读全文
摘要: 连续写了两篇文章,这一篇我想是序的完结篇了。结合用户注册的例子再将他简单丰富一下。在这里只添加一个简单需求,就是用户注册成功后给用户发一封邮件。补充一下之前的代码public class DomainService{ public void Register(User user) { ...
阅读全文
摘要: 上一篇针对用户注册案例简单介绍了如何使用 DDD,接下来我将继续针对这个例子做一下补充。先将User模型丰富起来,因为目前看上去他和贫血模型还没有啥大的区别。首先还是由领域专家来说明业务,他提出了用户注册成功后需要完善个人信息,这些信息包括姓名、生日、手机号。还需要用户提供一些联系信息,如地址,邮编...
阅读全文
摘要: 在开始DDD之前,你需要了解DDD的一些基础知识,聚合(AggregateRoot)、实体(Entity)、值对象(ValueObject),工厂(Factory),仓储(Repository)和领域服务(DomainService)。在这里值对象有区别于C#的值类型,请不要将两者混淆,一开始我也范...
阅读全文