一步步学习汇编之(9)前面八讲内容总结
n bx、si、di、bp
n 机器指令处理的数据所在位置
n 汇编语言中数据位置的表达
n 寻址方式
n 指令要处理的数据有多长?
n 寻址方式的综合应用
n div 指令
n 伪指令 dd
n Dup
下面我们来一步步阐述:
1.bx、si、di、bp
这4个寄存器(bx、bp、si、di)可以用在“[…]” 中来进行内存单元的寻址。
正确的指令
mov ax,[bx]
mov ax,[bx+si]
mov ax,[bx+di]
mov ax,[bp]
mov ax,[bp+si]
mov ax,[bp+di]
错误的指令
mov ax,[cx]
mov ax,[ax]
mov ax,[dx]
mov ax,[ds]
只要在[…]中使用寄存器bp,而指令中没有显性的给出段地址,段地址就默认在ss中。比如:
mov ax,[bp] 含义: (ax)=((ss)*16+(bp))
n mov ax,[bp+idata] 含义:(ax)=((ss)*16+(bp)+idata)
n mov ax,[bp+si] 含义:(ax)=((ss)*16+(bp)+(si))
n mov ax,[bp+si+idata] 含义:(ax)=((ss)*16+(bp)+(si)+idata)
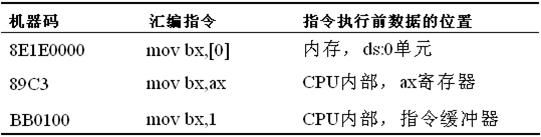
2.机器指令处理的数据所在位置
n 指令在执行前,所要处理的数据可以在三个地方:
CPU内部、内存、端口
n 立即数(idata)
对于直接包含在机器指令中的数据(执行前在cPu 的指令缓冲器中),在汇编语言中称为:立即数(idata ) ,在汇编指令中直接给出。例如:
mov ax,1
add bx,2000h
or bx,00010000b
mov al,’a’
n 寄存器
指令要处理的数据在寄存器中,在汇编指令中给出相应的寄存器名。例如:
mov ax,bx
mov ds,ax
n 段地址(SA)和偏移地址(EA)
指令要处理的数据在内存中,在汇编指令中可用[X]的格式给出EA,SA在某个段寄存器中。
3.汇编语言中数据位置的表达
n 存放段地址的寄存器是默认的
n 示例:
mov ax,[0]
mov ax,[bx]
段地址默认在ds中
显性的给出存放段地址的寄存器
mov ax,ds:[bp]
4.寻址方式
n 当数据存放在内存中的时候,我们可以用多种方式来给定这个内存单元的偏移地址,这种定位内存单元的方法一般被称为寻址方式。
5.指令要处理的数据有多长
n 对于这个问题,汇编语言中用以下方法处理。
n (1)通过寄存器名指明要处理的数据的尺寸。
n (2)在没有寄存器名存在的情况下,用操作符X ptr指明内存单元的长度,X在汇编指令中可以为word或byte。
n (3)其他方法
n 下面的指令中,寄存器指明了指令进行的是字操作:
n mov ax,1
n mov bx,ds:[0]
n mov ds,ax
n mov ds:[0],ax
n inc ax
n add ax,1000
n 下面的指令中,寄存器指明了指令进行的是字节操作:
n mov al,1
n mov al,bl
n mov al,ds:[0]
n mov ds:[0],al
n inc al
n add al,100
n 下面的指令中,用word ptr指明了指令访问的内存单元是一个字单元:
n mov word ptr ds:[0],1
n inc word ptr [bx]
n inc word ptr ds:[0]
n add word ptr [bx],2
n 下面的指令中,用byte ptr指明了指令访问的内存单元是一个字节单元:
n mov byte ptr ds:[0],1
n inc byte ptr [bx]
n inc byte ptr ds:[0]
n add byte ptr [bx],2
n 在没有寄存器参与的内存单元访问指令中,用word ptr或byte ptr显性地指明所要访问的内存单元的长度是很必要的。
n 否则,CPU无法得知所要访问的单元是字单元,还是字节单元。
n 假设我们用Debug查看内存的结果如下:
2000:1000 FF FF FF FF FF FF……
那么指令:
mov ax,2000H
mov ds,ax
mov byte ptr [1000H],1
将使内存中的内容变为:
2000:1000 01 FF FF FF FF FF……
n 有些指令默认了访问的是字单元还是字节单元,
比如:push [1000H]就不用指明访问的是字单元还是字节单元,
因为push指令只进行字操作。
6.寻址方式的综合应用
关于DEC公司的一条记录(1982年):
公司名称:DEC
总裁姓名:Ken Olsen
排 名:137
收 入:40
著名产品:PDP
1988年DEC公司的信息有了变化:
1、Ken Olsen 在富翁榜上的排名已升至38位;
2、DEC的收入增加了70亿美元;
3、该公司的著名产品已变为VAX系列计算机。
任务:编程修改内存中的过时数据。
内存分布图表示如下:

分析:
n 从要修改的内容,我们就可以逐步地确定修改的方法:
n (1)我们要访问的数据是DEC公司的记录,所以,首先要确定DEC公司记录的位置:R=seg:60
确定了公司记录的位置后,我们下面就进一步确定要访问的内容在记录中的位置。
n (2)确定排名字段在记录中的位置:0CH。
n (3)修改R+0CH处的数据。
n (4)确定收入字段在记录中的位置:0EH。
n (5)修改R+0EH处的数据。
n (6)确定产品字段在记录中的位置:10H。要修改的产品字段是一个字符串(或一个数组),需要访问字符串中的每一个字符。所以我们要进一步确定每一个字符在字符串中的位置。
n (7)确定第一个字符在产品字段中的位置:P=0。
n (8)修改R+10H+P处的数:P=P+1。
n (9)修改R+10H+P处的数据: P=P+1。
n (10)修改R+10H+P处的数据。
n 根据上面的分析,程序如下:
mov ax,seg
mov ds,ax
mov bx,60h
mov word ptr [bx+0ch],38
add word ptr [bx+0eh],70
mov si,0
mov byte ptr [bx+10h+si],’V’
inc si
mov byte ptr [bx+10h+si],’A’
inc si
mov byte ptr [bx+10h+si],’X’
7. div 指令
n div是除法指令,使用div作除法的时候:
n 除数:8位或16位,在寄存器或内存单元中
n 被除数:(默认)放在AX 或 DX和AX中
n 结果:运算 8位 16位
商 AL AX
余数 AH DX
n div指令格式:
n div reg
n div 内存单元
n 现在我们可以用多种方法来表示一个内存单元了。
n 编程:
利用除法指令计算100001/100。(程序)
mov dx,1
mov ax,86A1H ;(dx)*10000H+(ax)=100001
mov bx,100
div bx
程序执行后,(ax)=03E8H(即1000),(dx)=1(余数为1)。
读者可自行在Debug中实践。
8. 伪指令 dd
n 前面我们用db和dw定义字节型数据和字型数据。
n dd是用来定义dword (double word双字)型数据的。
n 示例:data segment
db 1
dw 1
dd 1
data ends
在data段中定义了三个数据:
n 第一个数据为01H,在data:0处,占1个字节;
n 第二个数据为0001H,在data:1处,占1个字;
n 第三个数据为00000001H,在data:3处,占2个字节;
n 用div 计算data段中第一个数据除以第二个数据后的结果,商存放在第3个数据的存储单元中。
data segment
dd 100001
dw 100
dw 0
data ends
mov ax,data
mov ds,ax
mov ax,ds:[0] ;ds:0字单元中的低16位存储在ax中
mov dx,ds:[2] ;ds:2字单元中的高16位存储在dx中
div word ptr ds:[4];用dx:ax中的32位数据除以ds:4字
;单元中的数据
mov ds:[6],ax ;将商存储在ds:6字单元中
9.dup
n dup是一个操作符,在汇编语言中同db、dw、dd 等一样,也是由编译器识别处理的符号。
n 它是和db、dw、dd 等数据定义伪指令配合使用的,用来进行数据的重复。
n dup示例
n db 3 dup (0)
定义了3个字节,它们的值都是0,
相当于 db 0,0,0
n dup示例
n db 3 dup (0,1,2)
定义了9个字节,它们是
0、1、2、0、1、2、0、1、2,
相当于 db 0,1,2,0,1,2,0,1,2
n 可见,dup的使用格式如下:
n db 重复的次数 dup (重复的字节型数据)
n dw 重复的次数 dup (重复的字型数据)
n dd 重复的次数 dup (重复的双字数据)
n dup是一个十分有用的操作符
比如我们要定义一个容量为 200 个字节的栈段,如果不用dup,则必须用这样的格式:
stack segment
dw 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
dw 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
dw 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
dw 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
dw 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
stack ends
n 当然,读者可以用dd,使程序变得简短一些,但是如果要求定义一个容量为1000字节或10000字节的呢?
如果没有dup,定义部分的程序就变得太长了;
有了dup就可以轻松解决。如下:
stack segment
db 200 dup (0)
stack ends