正则表达式的简单认识
文本搜索工具,根据用户指定的"模式(pattern)"对目标文本进行过滤,显示被模式匹配到的行。
一、什么是正则表达式?
正则表达式:由一类字符书写的模式,其中有些字符不表示字符的字面意义,而是表示控制或通配的功能;
二、正则表达式元字符
正则表达式语言由两种基本字符类型组成:原义(正常)文本字符和元字符。元字符使正则表达式具有处理能力。元字符既可以是放在 [] 中的任意单个字符(如 [a] 表示匹配单个小写字符 a ),也可以是字符序列(如 [a-d] 表示匹配 a 、 b 、 c 、 d 之间的任意一个字符,而 \w 表示任意英文字母和数字及下划线),下面是一些常见的元字符:
. 匹配除 \n 以外的任意单字符(注意元字符是小数点)。
[abcde] 匹配 abcde 之中的任意一个字符
[a-h] 匹配 a 到 h 之间的任意一个字符
[^fgh] 不与 fgh 之中的任意一个字符匹配
\w 匹配大小写英文字符及数字 0 到 9 之间的任意一个及下划线,相当于 [a-zA-Z0-9_]
\W 不匹配大小写英文字符及数字 0 到 9 之间的任意一个,相当于 [^a-zA-Z0-9_]
\s 匹配任何空白字符,相当于 [ \f\n\r\t\v]
\S 匹配任何非空白字符,相当于 [^\s]
\d 匹配任何 0 到 9 之间的单个数字,相当于 [0-9]
\D 不匹配任何 0 到 9 之间的单个数字,相当于 [^0-9]
[\u4e00-\u9fa5] 匹配任意单个汉字(这里用的是 Unicode 编码表示汉字的 )
三、正则表达式的分类
1、grep及基本正则表达式
grep [OPTION]... 'PATTERN' FILE...
字符匹配:
. : 匹配任意单个字符
[[:digit:]]===[0-9]
[[:lower:]]===[a-z]
[[:upper:]]===[A-Z]
[[:alpha:]]===[a-zA-Z]
[[:alnum:]]==[0-9a-zA-Z]
[[:space:]]
[[:punct:]]
[^]: 匹配指定集合外的任意单个字符
匹配次数:用于对其前面紧邻的字符所能够出现的次数作出限定
*: 匹配其前面的字符任意次,0,1或多次;
例如:grep 'x*y'
xy, xxy, xxxy, y
\?:匹配其前面的字符0次或1次;
例如:grep 'x\?y'
xy, xxy, y, xxxxxy, aby
\+: 匹配其前面的字符出现至少1次;
\{m\}: 匹配其前面的字符m次;
例如:grep 'x\{2\}y'
xy, xxy, y, xxxxxy, aby
\{m,n\} 匹配其前面的字符至少m次,至多n次;
例如: grep 'x\{2,4\}y'
xy, xxy, y, xxxxxxy, aby
grep 'x\{0,4\}y'
xy, xxy, y, xxxxxxxxxy, aby
grep 'x\{2,\}y'
xy, xxy, y, xxxxxy
.*: 匹配任意长度的任意字符
位置锚定:
^: 行首锚定
写在模式的最左侧
$: 行尾锚定
写在模式的最右侧
^$: 空白行
\<: 词首锚定, 相当于\b
出现在要查找的单词模式的左侧;\<char
\>:词尾锚定, 相当于\b
出现在要查找的单词模式的右侧;char\>
\<pattern\>: 匹配单词
分组:
后向引用:模式中,如果使用\(\)实现了分组,在某行文本的检查中,如果\(\)的模式匹配到了某内容,此内容后面的模式中可以被引用;
\1, \2, \3
模式自左而右,引用第#个左括号以及与其匹配右括号之间的模式匹配到的内容;
来个习题来形象的解释后向引用
习题: 添加用户bash, testbash, basher, nologin(SHELL为/sbin/nologin),而找出当前系统上其用户名和默认shell相同的用户;
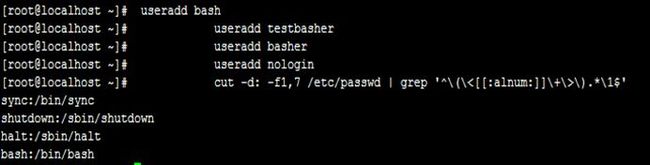
grep选项:
-v: 反向选取
-o: 仅显示匹配到内容
-i: 忽略字符大小写
-E: 使用扩展正则表达式
-A #:打印后#行的内容
-B #:打印前#行的内容
-C #:打印#行的输出内容
2、egrep及其扩展正则表达式
egrep:egrep = grep -E 可以使用基本的正则表达外, 还可以用扩展表达式. 注意区别.
扩展表达式:
扩展正则表达式的元字符:
字符匹配:
. : 匹配其任意单个字符
[]: 匹配指定集合中的任意单个字符
[^]:匹配指定集合外的任意单个字符
匹配次数限定:
*:匹配其前面的字符任意次,0,1或多次;
?: 匹配其前面字符0次或1次;
+:匹配其前面的字符至少1次;
{m,n}:{m,}表示匹配其前面至少m次, {0,n}表示匹配其前面之多n次;
锚定:
^: 行首锚定
写在模式的最左侧
$: 行尾锚定
写在模式的最右侧
^$: 空白行
\<: 词首锚定, 相当于\b
出现在要查找的单词模式的左侧;\<char
\>:词尾锚定, 相当于\b
出现在要查找的单词模式的右侧;char\>
\<pattern\>: 匹配单词
分组:
() ---------注意grep里的是用\(\)
后向引用:模式中,如果使用()实现了分组,在某行文本的检查中,如果()的模式匹配到了某内容,此内容后面的模式中可以被引用;
\1, \2, \3
模式自左而右,引用第#个左括号以及与其匹配右括号之间的模式匹配到的内容;
或者:
a|b: a或者b
ab|cd:
下面我来通过大量习题讲解来进一步揭开grep与egrep的神秘面纱
习题
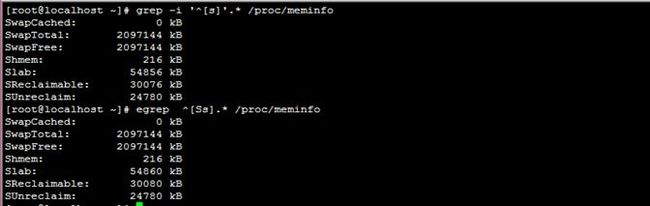
1、显示/proc/meminfo文件中以大写或小写S开头的行;
grep -i '^[s]'.* /proc/meminfo
egrep ^[Ss].* /proc/meminfo
注释:知识点 (1) 这里用到了^: 行首锚定
(2) []: 匹配指定集合中的任意单个 字符
(3)-i: 忽略字符大小写
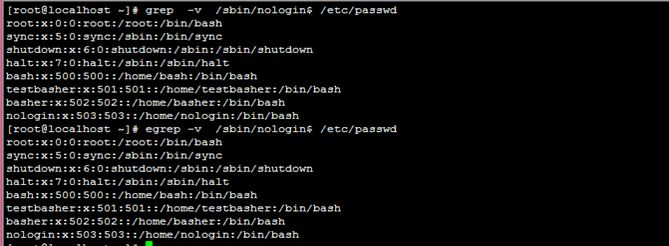
2、显示/etc/passwd文件中其默认shell为非/sbin/nologin的用户;
grep -v /sbin/nologin$ /etc/passwd
egrep -v /sbin/nologin$ /etc/passwd
注释:知识点 (1) -v: 反向选取
(2) $: 行尾锚定, 写在模式的最右侧
3、显示/etc/passwd文件中其默认shell为/bin/bash的用户;进一步:仅显示上述结果中其ID号最大的用户;
grep /bin/bash /etc/passwd|sort -n -r -t: -k3 | head -1
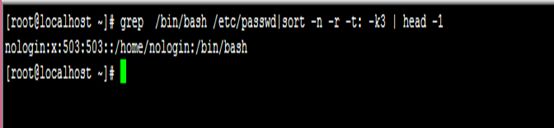
注释:知识点 (1)sort [option…]
-n :按数值大小排序
-r :逆序
-t :指定字段以什么为分隔符
-k # :指定用于排序的第#字段
(2)head [options]
-n #或是-# :指定前#行
4、找出/etc/passwd文件中的一位数或两位数;
# egrep '\<([0-9]|[1-9][0-9])\>' /etc/passwd
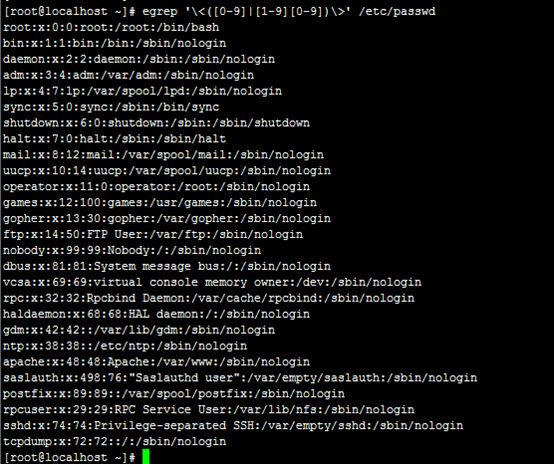
注释:知识点 (1) \<pattern\>: 匹配单词
5、显示/boot/grub/grub.conf中以至少一个空白字符开头的行;
#grep '^[[:space:]]\+' /boot/grub/grub.conf
#egrep '^[[:space:]]+' /boot/grub/grub.conf
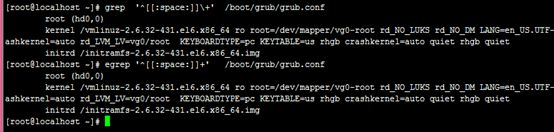
注释:知识点(1) 这里用到了^: 行首锚定
(2) [[:space:]] 匹配任意单个空白字符
(3) 在grep里\+:匹配其前面的字符至少1次;
(4) 在grep里\+:匹配其前面的字符至少1次;
6、显示/etc/rc.d/rc.sysinit文件中,以#开头,后面跟至少一个空白字符,而后又有至少一个非空白字符的行;
grep '^#[[:space:]]\+[^[:space:]]\+' /etc/rc.d/rc.sysinit
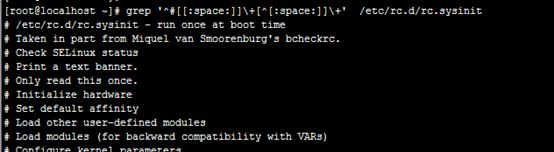
注释:知识点与第五题一样
7、找出netstat -tan命令执行结果中以'LISTEN'(后可有空白字符)结尾的行;
netstat -tan | grep 'LISTEN[[:space:]]\+' --color=auto
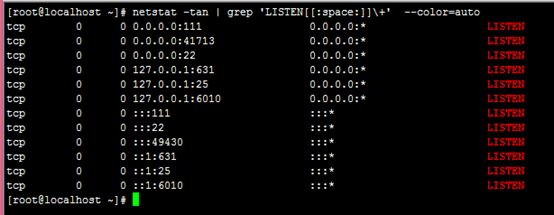
注释:知识点(1)netstat 命令用于显示各种网络相关信息
(2) | 为管道,连接命令,实现将前一个命令的输出当作后一个命令的输入;
(3) --color=auto 是增加颜色显示
(4)其它可参照第五题
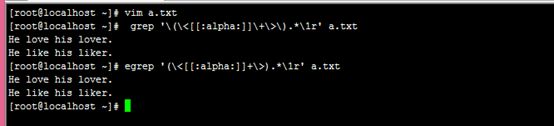
8、扩展题:新建一个文本文件,假设有如下内容:
He like his lover.
He love his lover.
He like his liker.
He love his liker.
找出其中最后一个单词是由此前某单词加r构成的行。
# grep '\(\<[[:alpha:]]\+\>\).*\1r' a.txt
# egrep '(\<[[:alpha:]]+\>).*\1r' m.txt
后向引用:模式中,如果使用\(\)实现了分组,在某行文本的检查中,如果\(\)的模式匹配到了某内容,此内容后面的模式中可以被引用;
\1, \2, \3
模式自左而右,引用第#个左括号以及与其匹配右括号之间的模式匹配到的内容;
(2) () -------注意grep里的是用\(\)
后向引用:模式中,如果使用()实现了分组,在某行文本的检查中,如果()的模式匹配到了某内容,此内容后面的模式中可以被引用;
\1, \2, \3
模式自左而右,引用第#个左括号以及与其匹配右括号之间的模式匹配到的内容;
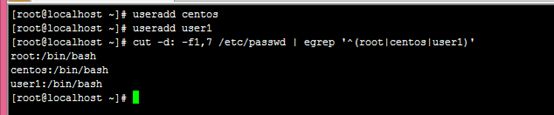
9、显示当前系统上root、centos或user1用户的默认shell及用户名;下面几种表示方法
# cut -d: -f1,7 /etc/passwd | egrep ^'root|centos|user1'
# cut -d: -f1,7 /etc/passwd | egrep '^root|^centos|^user1'
# cut -d: -f1,7 /etc/passwd | egrep '^(root|centos|user1)'
如是有user10,则需要固定一个词
# cut -d: -f1,7 /etc/passwd | egrep '^(root|centos|\<user1\>)'
注释:知识点(1)cut option FILE…
-d 后边指定字段分隔符
-f # |#-# |#,# 指定要显示的字段(其中#表示第1段,#-#表示两#区间内连续的段落,(#,#)表示只要两个#段的本身)
(2)参照第五题的知识点
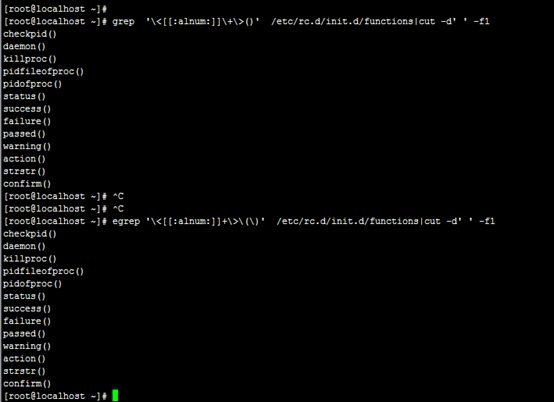
10、找出/etc/rc.d/init.d/functions文件中某单词后面跟一对小括号"()"的行;
#grep '\<[[:alnum:]]\+\>()' /etc/rc.d/init.d/functions|cut -d' ' -f1
#egrep '\<[[:alnum:]]+\>\(\)' /etc/rc.d/init.d/functions|cut -d' ' -f1
注释:知识点(1) [[:alnum:]]==[0-9a-zA-Z]
(2) 在grep里\+:匹配其前面的字符至少1次;
(3) 在grep里\+:匹配其前面的字符至少1次;
(4)在egrep里小括号()表示词组引用,所以想表示小括号的原义需要转义-- \(\)
11、使用echo输出一个路径,而使用egrep取出其基名;
#echo '/etc/sysconfig/' | egrep -o '[^/]+/?$'

注释:知识点(1)基名(dirname):从文件名中去掉路径信息,只打印
(2) -o: 仅显示匹配到内容
(3) ?: 匹配其前面字符0次或1次;
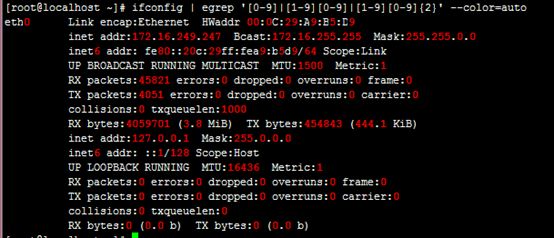
12、找出ifconfig命令结果中的1-255之间的数值;
1.0.0.1 - 223.255.255.254
ifconfig | egrep '[0-9]|[1-9][0-9]|[1-9][0-9]{2}'
--color=auto
注释:知识点(1)在egrep中
{m}:匹配其前面的字符m次;
13、找出ifconfig命令结果中的IP地址;
ifconfig |egrep '\<([1-9]|[1-9][0-9]|1[0-9][0-9]|2[0-1][0-9]|22[0-3])\>\.\<([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])\>\.\<([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])\>\.\<([1-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-4])\>' --color=auto

注释:知识点(1)四种颜色表示ip的四个段落,
(2)我们也可以简化下,因为第二段和第三段一样,效果如下:
ifconfig |egrep '\<([1-9]|[1-9][0-9]|1[0-9][0-9]|2[0-1][0-9]|22[0-3])\>\.(\<([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])\>\.){2}\<([1-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-4])\>' --color=auto