策略模式解析-JAVA类库中TreeSet源码为例
策略模式-JAVA类库TreeSet为例
1 策略模式概述
1.1 策略模式定义
策略模式定义了一系列的算法,并将每一个算法封装起来,而且使它们还可以相互替换。策略模式让算法独立于使用它的客户而独立变化。(原文:The Strategy Pattern defines a family of algorithms, encapsulates each one, and makes them interchangeable. Strategy lets the algorithm vary independently from clients that use it.)
策略模式体现了面向对象设计两个最基本的设计原则:
1、封装变化的概念
2、编程中使用接口而不是用接口的实现
1.2 策略模式组成
抽象策略角色: 策略类,通常由一个接口或者抽象类实现。
具体策略角色:包装了相关的算法和行为。
环境角色:持有一个策略类的引用,最终给客户端调用。
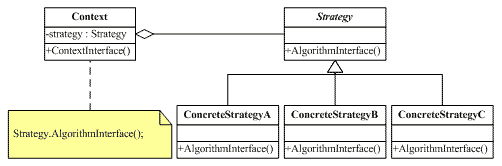
Context(应用场景):
1、需要使用Concrete Strategy提供的算法。
2、 内部维护一个Strategy的实例。
3、 负责动态设置运行时Strategy具体的实现算法。
4、负责跟Strategy之间的交互和数据传递。
Strategy(抽象策略类):
1、 定义了一个公共接口,各种不同的算法以不同的方式实现这个接口,Context使用这个接口调用不同的算法,一般使用接口或抽象类实现。
Concrete Strategy(具体策略类):
1、 实现了Strategy定义的接口,提供具体的算法实现。
1.3 应用场景
- 多个类只区别在表现行为不同,可以使用Strategy模式,在运行时动态选择具体要执行的行为。
- 需要在不同情况下使用不同的策略(算法),或者策略还可能在未来用其它方式来实现。
- 对客户隐藏具体策略(算法)的实现细节,彼此完全独立。
2 JAVA类库中TreeSet的策略模式
TreeSet编程
1 public class TreeSetTest2 { 2 public static void main(String[] args) { 3 Set<Person> set=new TreeSet<Person>(new Mycomparator()); 4 //(1) 5 Person p1=new Person(1,"ll"); 6 Person p2=new Person(2, "xx"); 7 Person p3=new Person(3, "ss"); 8 9 set.add(p1); 10 set.add(p2); 11 set.add(p3); 12 13 for(Iterator<Person> itr=set.iterator();itr.hasNext();){ 14 System.out.println(itr.next().getName()); 15 } 16 } 17 } 18 19 class Person{ 20 private int ID; 21 private String name; 22 23 public Person(int id,String name){ 24 this.ID=id; 25 this.name=name; 26 } 27 public int getID() { 28 return ID; 29 } 30 public String getName() { 31 return name; 32 } 33 } 34 35 class Mycomparator implements Comparator<Person>{ 36 public int compare(Person o1, Person o2) { 37 return o1.getID()-o2.getID(); 38 } 39 40 }
结果:

上面代码实现的功能非常简单,将Person这个类放入到TreeSet这个集合中,并实现对放入对象的一个排序。TreeSet是java类库里面的一个标准类,对于要add进去的类,在编码时并知道,那么是如何实现排序的呢?在TreeSet生成时,我们传入了一个Comparator的类,既是抽象策略类。
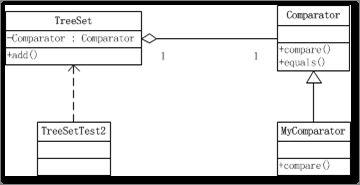
具体的排序算法,在java类库也是封装好的,我们并不需要关心。在这个例子中,MyComparator类即是具体的实现类,虽然呢传入对象千差万别。我们将通过,源码进行分析。
2.1 环境角色-TreeSet
在查看源码时,我们习惯性的第一步肯定是看TreeSet这个类(从(1)->(2)),里面到底是如何实现对添加进去的类实现排序的。
TreeSet代码(部分)
1 public class TreeSet<E> extends AbstractSet<E> 2 implements NavigableSet<E>, Cloneable, java.io.Serializable 3 { 4 TreeSet(NavigableMap<E,Object> m) { 5 this.m = m; 6 } 7 8 public TreeSet(Comparator<? super E> comparator) { 9 this(new TreeMap<>(comparator));//(2) 10 } 11 }
上面的代码中给出的构造方法是众多构造函数中的一个,也是我们例子中使用到的构造函数。可以很明显看出,TreeSet在底层是用TreeMap实现的(Map中的key并不会重复)。这样,我们就必须要转到TreeMap的代码去看了(从(2)->(3))。
TreeMap代码(部分)
1 public class TreeMap<K,V> 2 extends AbstractMap<K,V> 3 implements NavigableMap<K,V>, Cloneable, java.io.Serializable 4 { 5 private final Comparator<? super K> comparator; 6 7 private transient Entry<K,V> root = null; 8 9 public TreeMap(Comparator<? super K> comparator) { 10 this.comparator = comparator;//(3) 11 } 12 }
从上述代码中,我可以发现我们传入的Mycompator对象最后,赋给了TreeMap对象中的comparator。TreeSet的对象已经生成,接下来我们看看使用add()方法是代码是如何进行的。
TreeSet的add()方法:
1 public boolean add(E e) { 2 return m.put(e, PRESENT)==null; 3 }
很显然,TreeSet的add(),使用的是TreeMap的put()方法,将传入的对象作为key,一个空的Object对象作为value。事实上,所有的实现均在TreeMap中,所以继续看TreeMap中的put()方法。
TreeMap的put()方法:
1 public V put(K key, V value) { 2 Entry<K,V> t = root; 3 //空树时,第一个节点给根节点 4 if (t == null) { 5 compare(key, key); // type (and possibly null) check 6 7 root = new Entry<>(key, value, null); 8 size = 1; 9 modCount++; 10 return null; 11 } 12 int cmp; 13 Entry<K,V> parent; 14 // split comparator and comparable paths 15 Comparator<? super K> cpr = comparator; 16 //我们现在的实现方式cpr就不为null,具体实现类时MyComparator 17 if (cpr != null) { 18 do { 19 parent = t; 20 //这一步非常关键,对于排序算法来说,我只要知道两个对象比//较后谁大水小就可以了。对于该算法而言,cpr是一个接口类//(具体实现我不管,反正肯定有compare这个函数,肯定会返//回一个int类型)。这样,我获取到这个值之后就能排序了,//不管要排序的是Person类还是Animal类。 21 cmp = cpr.compare(key, t.key); 22 if (cmp < 0) 23 t = t.left; 24 else if (cmp > 0) 25 t = t.right; 26 else 27 return t.setValue(value); 28 } while (t != null); 29 } 30 //如果comparator为空,就要用comparable这个借口了,也是策略模式 31 else { 32 if (key == null) 33 throw new NullPointerException(); 34 Comparable<? super K> k = (Comparable<? super K>) key; 35 do { 36 parent = t; 37 cmp = k.compareTo(t.key); 38 if (cmp < 0) 39 t = t.left; 40 else if (cmp > 0) 41 t = t.right; 42 else 43 return t.setValue(value); 44 } while (t != null); 45 } 46 Entry<K,V> e = new Entry<>(key, value, parent); 47 if (cmp < 0) 48 parent.left = e; 49 else 50 parent.right = e; 51 fixAfterInsertion(e);//看来还是棵平衡二叉排序树 52 size++; 53 modCount++; 54 return null; 55 }
2.2 具体实现类-Mycomparator
1 class Mycomparator implements Comparator<Person>{ 2 public int compare(Person o1, Person o2) { 3 return o1.getID()-o2.getID(); 4 } 5 6 }
在这个类中,我们实现的是对Person这个类的对象的比较。当然这里你也可以用别的类,阿猫阿狗都没问题只要实现了Comparator这个接口就可以了,这不正体现了策略模式灵活、可扩展的特点。
2.3 抽象类(接口)- Comparator
1 public interface Comparator<T> { 2 int compare(T o1, T o2); 3 boolean equals(Object obj); 4 }
这个接口只定义了两个函数,compare函数的行为很简单如果o1比o2大,就返回一个大于0的整数,反之则小于0。
2.4 客户端类-TreeSetTest2
这个类即是客户端类,同时也实现了具体的算法。在基本的策略模式中,选择所用具体实现的职责由客户端对象承担,并转给策略模式的Context对象。(这本身没有解除客户端需要选择判断的压力,而策略模式与简单工厂模式结合后,选择具体实现的职责也可以由Context来承担,这就最大化的减轻了客户端的压力。)
其实,在某个方面来说这个也不能称之为一个缺点看具体的应用,在这个例子中你就不能把这个负担减轻。Comparator本来就千差万别,不可能交给工厂类。如果是排序的话,可能有很多种具体实现你可以交给工厂类给你来实现。
3 策略模式的优缺点
把策略模式的优缺点放在这个位置不尴不尬。不过,我觉得先看优缺点,思考过后再看后面的对比例子更容易理解。
3.1 策略模式优点
1、 提供了一种替代继承的方法,而且既保持了继承的优点(代码重用)还比继承更灵活(算法独立,可以任意扩展)。
2、 避免程序中使用多重条件转移语句,使系统更灵活,并易于扩展。
3、 遵守大部分GRASP原则和常用设计原则,高内聚、低偶合。
3.2 策略模式的缺点
1、 因为每个具体策略类都会产生一个新类,所以会增加系统需要维护的类的数量。
2、 在基本的策略模式中,选择所用具体实现的职责由客户端对象承担,并转给策略模式的Context对象。(这本身没有解除客户端需要选择判断的压力,而策略模式与简单工厂模式结合后,选择具体实现的职责也可以由Context来承担,这就最大化的减轻了客户端的压力。)
4 对比-非策略模式时
假设一个场景,如果有一个笼子,里面可以放狗Dog或者Bird,且只能放两种中的一种。取出来,要根据他们的编号顺序取出。
4.1 2B程序员做法
1 public class ArrayAnimal { 2 Dog[] dog=new Dog[10]; 3 Bird[] bird=new Bird[10]; 4 int count=0; 5 6 public void add(Dog dog){ 7 //如果空间不够了,分配更大空间 8 //根据插入排序(通过ID),将dog插入适合的位置 9 } 10 public void add(Bird bird){ 11 //如果空间不够了,分配更大空间 12 //根据插入排序(通过ID),将dog插入适合的位置 13 } 14 } 15 16 class Dog{ 17 public int ID; 18 } 19 class Bird{ 20 public int ID; 21 }
这是2B程序员(且泛型也不会用)的做法,如果这个笼子只放狗和鸟,不会有任何问题。设想,如果我们说这个笼子现在鸡鸭都可以放了呢?这个是时候,你就不得不去修改ArrayAnimal这个类了,增加新的add方法。这个时候就完全没有灵活性、扩展性可言了(优点2),基本上不能想象ArrayAnimal这个类放在jar包里,给别人使用。
4.2 进阶版非策略模式
1 public class ArrayAnimal { 2 Animal[] animal=new Animal[10]; 3 int count=0; 4 5 public void add(Animal obj){ 6 //如果空间不够了,分配更大空间 7 //根据插入排序(通过ID),将dog插入适合的位置 8 } 9 } 10 class Animal{ 11 public int ID; 12 int compare(Animal obj){ 13 return ID-obj.ID; 14 } 15 } 16 17 class Dog extends Animal{ 18 public String name; 19 } 20 class Bird{ 21 public String name; 22 }
这个程序,就比前一个高明多了,基本上所有继承Animal的类都能放到这个笼子里面,而且这笼子也不需要修改。但是,扩展依然有限,因为放进笼子里面的都只能是动物。而且,这个程序里面即便是继承Animal类的子类,比较方式可能跟父类不一样(甚至没有比较方法),这个时候你就只能用覆盖的方式来完成了。在程序设计时,还是建议分开会变化和不会变化的部分,把变化的部分独立出来成为接口。
5 简单工厂模式和策略模式区别
这两种模式的作用就是拥抱变化,减少耦合。在变化来临时争取做最小的改动来适应变化。这就要求我们把些“善变”的功能从客户端分离出来,形成一个个的功能类,然后根据多态特性,使得功能类变化的同时,客户端代码不发生变化。
5.1 简单工厂模式
简单工厂模式:有一个父类需要做一个运算(其中包含了不同种类的几种运算),将父类涉及此运算的方法都设成虚方法,然后父类派生一些子类,使得每一种不同的运算都对应一个子类。另外有一个工厂类,这个类一般只有一个方法(工厂的生成方法),这个方法的返回值是一个超类,在方法的内部,根据传入参数的不同,分别构造各个不同的子类的对象,并返回。客户端并不认识子类,客户端只认识超类和工厂类。每次客户端需要一中运算时,就把相应的参数传给工厂类,让工厂类构造出相应的子类,然后在客户端用父类接收(这里有一个多态的运用)。客户端很顺理成章地用父类的计算方法(其实这是一个虚方法,并且已经被子类特化过了,其实是调用子类的方法)计算出来结果。如果要增加功能时,你只要再从父类中派生相应功能的子类,然后修改下工厂类就OK了,对于客户端是透明的。
5.2 策略模式
策略模式:策略模式更直接了一点,没有用工厂类,而是直接把工厂类的生成方法的代码写到了客户端。客户端自己构造出了具有不同功能的子类(而且是用父类接收的,多态),省掉了工厂类。策略模式定义了算法家族,分别封装起来,让他们之间可以互相替换,此模式让算法的变化,不会影响到使用算法的客户。这里的算法家族和简单工厂模式里的父类是同一个概念。当不同的行为堆砌在一个类中时,就很难避免使用条件语句来选择合适的行为,将这些行为封装在一个个独立的策略子类中,可以在客户端中消除条件语句。
简单工厂模式+策略模式:为了将工厂方法的代码从客户端移出来,我们把这些代码搬到了父类的构造函数中,让父类在构造的时候,根据参数,自己实现工厂类的作用。这样做的好处就是,在客户端不用再认识工厂类了,客户端只要知道父类一个就OK,进一步隔离了变化,降低了耦合。
在基本的策略模式中,选择所用具体实现的职责由客户端对象成端,并转给客户端。这本身并没有减除客户端需要选择判断的压力,而策略模式与简单工厂模式结合后,选择具体实现的职责也可以由父类承担,这就最大化地减轻了客户端的职责。
PS:有软件架构这门课上课要求讲,所以索性也把PPT也给分享了得了,网络的精神就应该是分享。http://pan.baidu.com/share/link?shareid=372728&uk=3792525916。也刚刚学设计模式,难免有纰漏,希望批评指正,毕竟没有做过大型项目。
6 参考资料
[1]. 《Head First设计模式》
[2]. http://www.cnblogs.com/syxchina/archive/2011/10/11/2207017.html
[3]. http://fendou.org/post/2011/03/23/factory-strategy/
[4]. http://baike.baidu.com/view/2141079.htm