安装CDH4 (Cloudera Distribution Hadoop)步骤
安装流程
机器和系统
3台服务器,安装centos 6.4 64bit系统,内存8G,磁盘60G,cpu单核
已配置好静态ip,并配置好/etc/hosts
下载cdh4版本
https://www.cloudera.com/content/support/en/downloads.html
点击下载cdh4版本,下载cloudera-manager-installer.bin
赋予执行权限
chmod u+x cloudera-manager-installer.bin
执行安装命令
./cloudera-manager-installer.bin
若遇到如下问题
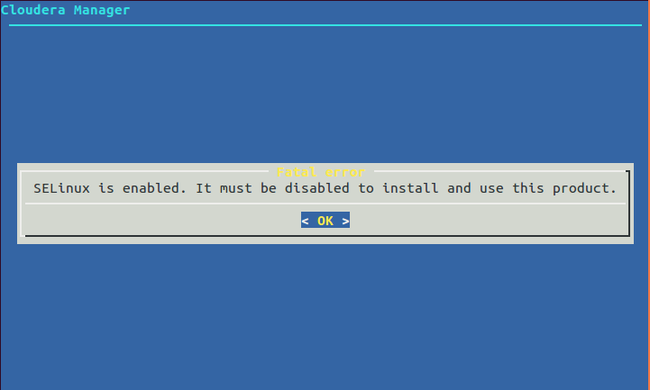
切换到 permissive模式
/usr/sbin/setenforce 0
修改selinux设置选项
vi /etc/selinux/config
| # This file controls the state of SELinux on the system. # SELINUX= can take one of these three values: # enforcing - SELinux security policy is enforced. # permissive - SELinux prints warnings instead of enforcing. # disabled - No SELinux policy is loaded. SELINUX=disabled # SELINUXTYPE= can take one of these two values: # targeted - Targeted processes are protected, # mls - Multi Level Security protection. SELINUXTYPE=targeted |
设置SELINUX=disabled,如上图标红处,所展示的那样
重启生效
roboot
配置域名解析
vi /etc/resolv.conf
| domain localdomain search localdomain nameserver 8.8.8.8 #google域名服务器 nameserver 8.8.4.4 #google域名服务器 |
测试域名服务
ping www.baidu.com
| PING www.a.shifen.com (115.239.210.27) 56(84) bytes of data. 64 bytes from 115.239.210.27: icmp_seq=1 ttl=53 time=6.47 ms 64 bytes from 115.239.210.27: icmp_seq=2 ttl=53 time=6.43 ms 64 bytes from 115.239.210.27: icmp_seq=3 ttl=53 time=6.39 ms 64 bytes from 115.239.210.27: icmp_seq=4 ttl=53 time=6.59 ms ^C --- www.a.shifen.com ping statistics --- 4 packets transmitted, 4 received, 0% packet loss, time 3478ms |
由于访问官方的网络速度缓慢,建议自己搭建yum资源服务器或本地安装rpm
搭建yum资源服务器作为镜像
wget -c -r -np http://archive.cloudera.com/cm4/redhat/6/x86_64/cm/4/
搭建自己的web服务器,推荐apache2
修改本地yum资源仓库
cd /etc/yum.repos.d/
cat cloudera-manager.repo
| [cloudera-manager] name=Cloudera Manager baseurl=http://archive.cloudera.com/cm4/redhat/6/x86_64/cm/4/ gpgkey = http://archive.cloudera.com/cm4/redhat/6/x86_64/cm/RPM-GPG-KEY-cloudera gpgcheck=1 |
修改为自己本地的镜像url替换baseurl,建议设置gpgcheck=0
清空本地yum缓存
yum clean all
查询是否更新
yum search hadoop
一路Next
访问web管理界面
http://<hostname>:7180/cmf/login
访问web失败,需要关闭防火墙,才能正常访问Web管理界面
关闭防火墙
service iptables stop
service iptables status
设置重启服务不启动
chkconfig iptables off
确认
chkconfig –list
| iptables 0:关闭 1:关闭 2:关闭 3:关闭 4:关闭 5:关闭 6:关闭 |
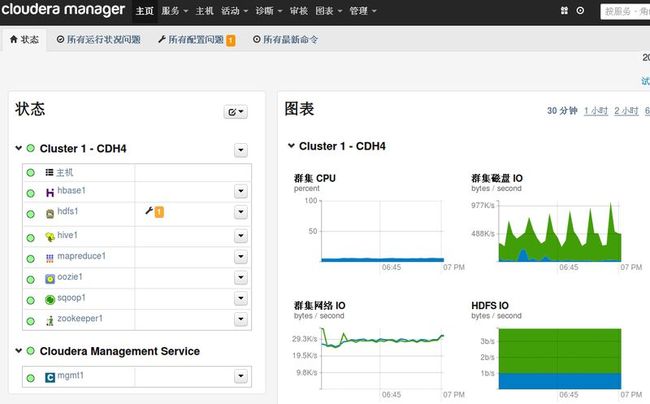
安装成功后界面如下所示: