Hadoop2.2.0--Hadoop Federation、Automatic HA、Yarn完全分布式集群结构
Hadoop有很多的上场时间,与系统上线。手头的事情略少。So,抓紧时间去通过一遍Hadoop2在下面Hadoop联盟(Federation)、Hadoop2可用性(HA)及Yarn的全然分布式配置。现记录在博客中。互相交流学习。话不多说,直入正文。
本文採用倒叙手法。先将终于结果呈现出来。例如以下:
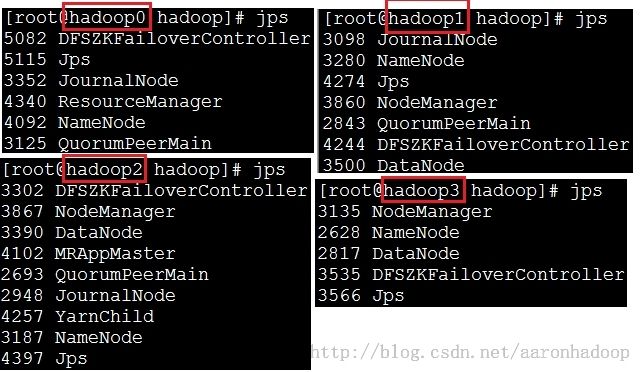
结果展现一,通过jps查看集群守护进程
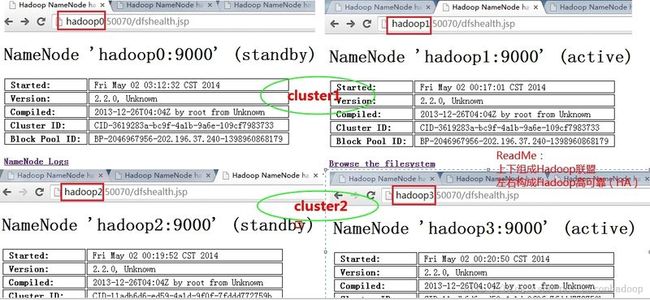
结果展现二。通过web端,查看集群执行情况
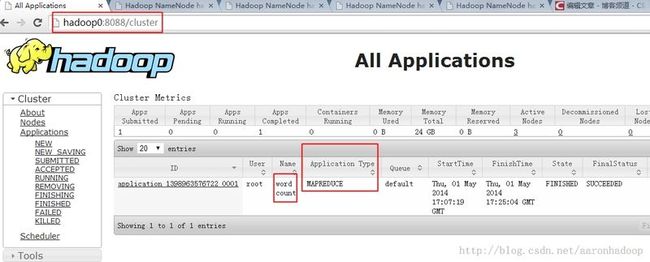
结果展现三,执行Hadoop2自带的wordcount程序。通过web查看。例如以下图,
能够看出Application Type是MapReduce。哈哈,快点在Yarn上把自己的Storm跑起来吧
OK,3张截图已献上,下文依照例如以下思路进行
本文仅仅讲诉安装过程中的重点。对于有些步骤未做具体说明。欢迎留言交流。
一、集群环境
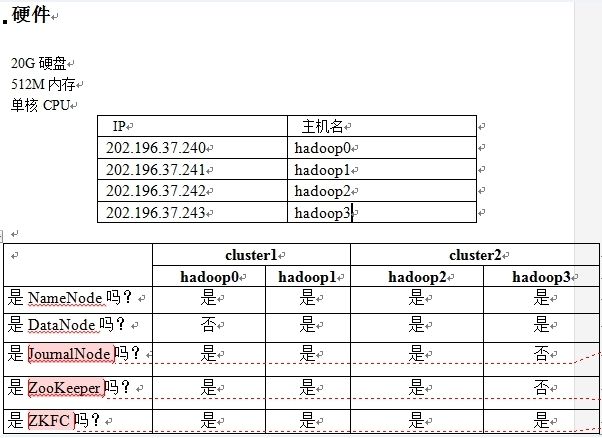

软件解压后,放在/usr/local路径下
二、详细步骤
准备工作
查看CentOS系统版本号
arch/uname–a x86_64(32位的是i386、i686)
改动主机名(重新启动生效)
vi/etc/sysconfig/network
设定IP地址
改动hosts映射文件
vi/etc/hosts
202.196.37.240 hadoop0
202.196.37.241 hadoop1
202.196.37.242 hadoop2
202.196.37.243 hadoop3
配置SSH
hadoop0上运行。生成密钥对
ssh-keygen–t rsa
cp id_rsa.pub authorized_keys
非hadoop0上运行,聚集
ssh-copy-id -i hadoop0(把非hadoop0机器上的id_rsa.pub远程复制到bigdata0中的authorized_keys文件内)
hadoop0上运行,分发
scp authorized_keys hadoop1:/root/.ssh/
配置JDK
安装Zookeeper
改动核心文件zoo.cfg
dataDir=/usr/local/zookeeper-3.4.5/data
logDir=/usr/local/zookeeper-3.4.5/log
server.0=hadoop0:2887:3887
server.1=hadoop1:2887:3887
server.2=hadoop2:2887:3887
启动、验证Zookeeper集群
zkServer.shstart/status
安装Hadoop2
将自编译的64位的hadoop-2.2.0-src放到/usr/local路径下
cp -R/usr/local/hadoop-2.2.0-src/hadoop-dist/target/hadoop-2.2.0 /usr/local/
mvhadoop-2.2.0 hadoop
本文中的全部xml配置文件。都在/usr/local/hadoop/etc/hadoop路径下,
全部配置文件,均已測试通过,略微整理格式后,可直接copy使用。
配置分为两部分,一部分是对Hadoop2的Hadoop Federation、HA的配置;还有一部分是对Hadoop2的Yarn配置。请看下图:
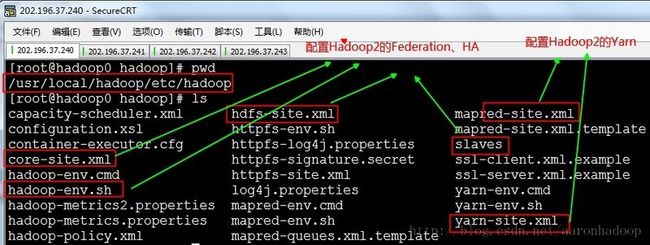
开启配置文件模式。哈哈

首先在cluster1_hadoop0上配置。然后再往其它节点scp
core-site.xml
<configuration>
<property><name> fs.defaultFS</name>
<value>hdfs://cluster1</value>
<description>此处是默认的HDFS路径,在节点hadoop0和hadoop1中使用cluster1。在节点hadoop2和hadoop3中使用cluster2</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop0:2181,hadoop1:2181,hadoop2:2181</value>
<description>Zookeeper集群<description>
</property>
</configuration>
hdfs-site.xml
<configuration>
<!--1描写叙述cluster1集群的信息-->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>cluster1,cluster2</value>
</property>
<property>
<name>dfs.ha.namenodes.cluster1</name>
<value>hadoop0,hadoop1</value>
</property>
<property>
<name>dfs.namenode.rpc-address.cluster1.hadoop0</name>
<value>hadoop0:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.cluster1.hadoop0</name>
<value>hadoop0:50070</value>
</property>
<property>
<name>dfs.namenode.rpc-address.cluster1.hadoop1</name>
<value>hadoop1:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.cluster1.hadoop1</name>
<value>hadoop1:50070</value>
</property>
<!--在cluster1中此处的凝视是关闭的,cluster2反之-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop0:8485;hadoop1:8485;hadoop2:8485/cluster1</value>
<description>指定cluster1的两个NameNode共享edits文件文件夹时,使用的是JournalNode集群来维护</description>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled.cluster1</name>
<value>true</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.cluster1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!--2以下描写叙述cluster2集群的信息-->
<property>
<name>dfs.ha.namenodes.cluster2</name>
<value>hadoop2,hadoop3</value>
</property>
<property>
<name>dfs.namenode.rpc-address.cluster2.hadoop2</name>
<value>hadoop2:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.cluster2.hadoop2</name>
<value>hadoop2:50070</value>
</property>
<property>
<name>dfs.namenode.rpc-address.cluster2.hadoop3</name>
<value>hadoop3:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.cluster2.hadoop3</name>
<value>hadoop3:50070</value>
</property>
<!-- 在cluster1中此处的凝视是打开的。cluster2反之
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop0:8485;hadoop1:8485;hadoop2:8485/cluster1</value>
<description>指定cluster2的两个NameNode共享edits文件文件夹时。使用的是JournalNode集群来维护</description>
</property>
-->
<property>
<name>dfs.ha.automatic-failover.enabled.cluster2</name>
<value>true</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.cluster2</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!--3配置cluster1、cluster2公共的信息-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/usr/local/hadoop/tmp/journal</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
</configuration>
以上配置完毕后,分发scp
scp -rq hadoop hadoop1:/usr/local/
scp -rq hadoop hadoop2:/usr/local/
scp -rq hadoop hadoop3:/usr/local/
在其它节点改动时,须要注意的地方
hadoop-env.sh 无需改动
slaves 无需改动
core-site.xml
1、<property>
<name>fs.defaultFS</name>
<value>hdfs://cluster1</value>
</property>
cluster1节点中的value值:hdfs://cluster1
cluster2节点中的value值:hdfs://cluster2
hdfs-site.xml
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop0:8485;hadoop1:8485;hadoop2:8485/cluster2</value>
</property>
cluster1节点中的value值:qjournal://hadoop0:8485;hadoop1:8485;hadoop2:8485/cluster1
cluster2节点中的value值:qjournal://hadoop0:8485;hadoop1:8485;hadoop2:8485/cluster2
此处的实质是使用JournalNode集群来维护Hadoop集群中两个NameNode共享edits文件文件夹的信息。重在理解,不可盲目copy哟
仅仅需相应改动这两个地方就可以。
測试启动
1、启动Zookeeper
在hadoop0、hadoop1、hadoop2上运行zkServer.shstart
2、启动JournalNode
在hadoop0、hadoop1、hadoop2上运行sbin/hadoop-daemon.shstart journalnode
3、格式化ZooKeeper
在hadoop0、hadoop2上运行bin/hdfs zkfc -formatZK
由于Zookeeper要担当运行高可用(HA)切换的任务
对cluster1
41、对hadoop0节点进行格式化和启动
bin/hdfs namenode -format
sbin/hadoop-daemon.sh start namenode
51、对hadoop1节点进行格式化和启动
bin/hdfs namenode -bootstrapStandby
sbin/hadoop-daemon.sh start namenode
61、在hadoop0、hadoop1上启动zkfc
sbin/hadoop-daemon.sh start zkfc
运行后, hadoop0、hadoop1有一个节点就会变为active状态。
对cluster2
42、对hadoop2节点进行格式化和启动
bin/hdfs namenode -format
sbin/hadoop-daemon.sh start namenode
52、对hadoop3节点进行格式化和启动
bin/hdfs namenode -bootstrapStandby
sbin/hadoop-daemon.sh start namenode
62、在hadoop2、hadoop3上启动zkfc
sbin/hadoop-daemon.sh start zkfc
运行后。 hadoop2、hadoop3有一个节点就会变为active状态。
7、
启动datanode,在hadoop0上运行
sbin/hadoop-daemons.sh start datanode
集群的执行情况,请參见文章开头的截图
截至到此,已经能够对Hadoop2的HDFS进行操作。
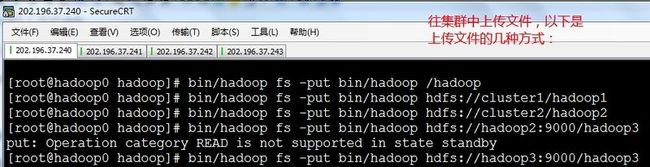
以下进行Yarn的配置。配置后,就能够在Yarn上执行MapReduce作业啦,哈哈
配置Yarn
下面配置文件依然是在/usr/local/hadoop/etc/hadoop路径下
mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop0</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
測试Yarn
启动yarn,在hadoop0上运行
sbin/start-yarn.sh
执行測试程序
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jarwordcount /testFile /out
測试结果。请见博文開始。
OK!
已越过这道坎——Hadoop2中Hadoop Federation、HA、Yarn全然分布式配置。
今天,Hadoop2你搭建成功了吗?DO it !
文章中的xml配置未做具体description,欢迎留言交流。
Storm学习,从我自己去......
版权声明:本文博客原创文章。博客,未经同意,不得转载。