经典算法题每日演练——第十三题 赫夫曼树
赫夫曼树又称最优二叉树,也就是带权路径最短的树,对于赫夫曼树,我想大家对它是非常的熟悉,也知道它的应用场景,
但是有没有自己亲手写过,这个我就不清楚了,不管以前写没写,这一篇我们来玩一把。
一:概念
赫夫曼树里面有几个概念,也是非常简单的,先来看下面的图:
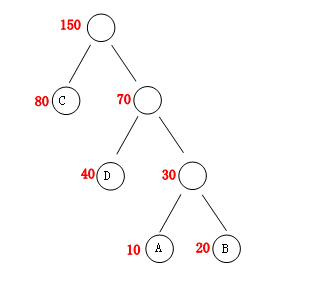
1. 基础概念
<1> 节点的权: 节点中红色部分就是权,在实际应用中,我们用“字符”出现的次数作为权。
<2> 路径长度:可以理解成该节点到根节点的层数,比如:“A”到根节点的路径长度为3。
<3> 树的路径长度:各个叶子节点到根节点的路径长度总和,用WPL标记。
最后我们要讨论的的赫夫曼树也就是带权路径长度最小的一棵树。
2.构建
由于要使WPL最短,赫夫曼树的构建采用自低向上的方式,这里我们采用小根堆来存放当前需要构建的各个节点,我们的方
式是每次从小根堆中取出最小的两个节点,合并后放入堆中,然后继续取两个最小的节点,一直到小根堆为空,最后我们采用
自底向上构建的赫夫曼树也就完毕了。

好了,赫夫曼树的典型应用就是在数据压缩方面,下面我们就要在赫夫曼树上面放入赫夫曼编码了,我们知道普通的ASCII码是
采用等长编码的,即每个字符都采用2个字节,而赫夫曼编码的思想就是采用不等长的思路,权重高的字符靠近根节点,权重低
的字符远离根节点,标记方式为左孩子“0”,右孩子“1”,如下图。
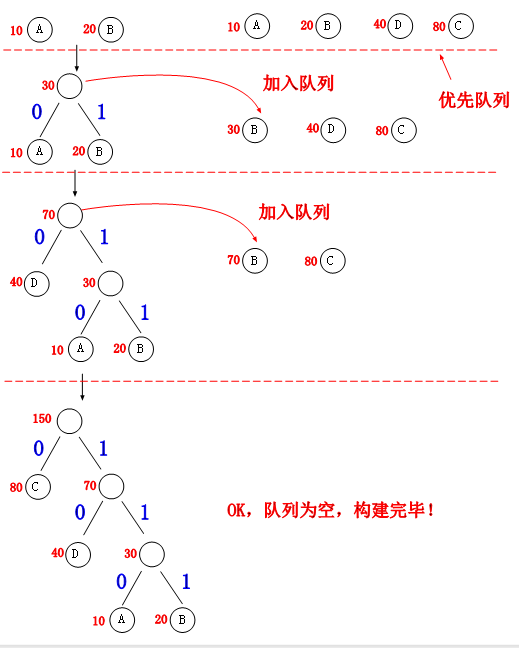
从图中我们可以看到各个字符的赫夫曼编码了,获取字符的编码采用从根往下的方式收集路径上的‘0,1',如:
A:110。
B:111。
C:0。
D:10。
最后我们来比较他们的WPL的长度: ASCII码=10*2+20*2+40*2+80*2=300
赫夫曼码=10*3+20*3+40*2+80*1=250
可以看到,赫夫曼码压缩了50个0,1字符,太牛逼了,是不是啊。。。
三:代码
1. 树节点
我们采用7元节点,其中parent方便我们在DFS的时候找到从叶子节点到根节点的路径上的赫夫曼编码。
1 #region 赫夫曼节点
2 /// <summary>
3 /// 赫夫曼节点
4 /// </summary>
5 public class Node
6 {
7 /// <summary>
8 /// 左孩子
9 /// </summary>
10 public Node left;
11
12 /// <summary>
13 /// 右孩子
14 /// </summary>
15 public Node right;
16
17 /// <summary>
18 /// 父节点
19 /// </summary>
20 public Node parent;
21
22 /// <summary>
23 /// 节点字符
24 /// </summary>
25 public char c;
26
27 /// <summary>
28 /// 节点权重
29 /// </summary>
30 public int weight;
31
32 //赫夫曼“0"or“1"
33 public char huffmancode;
34
35 /// <summary>
36 /// 标记是否为叶子节点
37 /// </summary>
38 public bool isLeaf;
39 }
40 #endregion
1. 构建赫夫曼树(Build)
上面也说了,构建赫夫曼编码树我们采用小根堆的形式构建,构建完后,我们采用DFS的方式统计各个字符的编码,复杂度为N*logN。
关于小根堆(详细内容可以参考我的系列文章 "优先队列")
1 #region 构建赫夫曼树
2 /// <summary>
3 /// 构建赫夫曼树
4 /// </summary>
5 public void Build()
6 {
7 //构建
8 while (queue.Count() > 0)
9 {
10 //如果只有一个节点,则说明已经到根节点了
11 if (queue.Count() == 1)
12 {
13 root = queue.Dequeue().t;
14
15 break;
16 }
17
18 //节点1
19 var node1 = queue.Dequeue();
20
21 //节点2
22 var node2 = queue.Dequeue();
23
24 //标记左孩子
25 node1.t.huffmancode = '0';
26
27 //标记为右孩子
28 node2.t.huffmancode = '1';
29
30 //判断当前节点是否为叶子节点,hufuman无度为1点节点(方便计算huffman编码)
31 if (node1.t.left == null)
32 node1.t.isLeaf = true;
33
34 if (node2.t.left == null)
35 node2.t.isLeaf = true;
36
37 //父节点
38 root = new Node();
39
40 root.left = node1.t;
41
42 root.right = node2.t;
43
44 root.weight = node1.t.weight + node2.t.weight;
45
46 //当前节点为根节点
47 node1.t.parent = node2.t.parent = root;
48
49 //将当前节点的父节点入队列
50 queue.Eequeue(root, root.weight);
51 }
52
53 //深度优先统计各个字符的编码
54 DFS(root);
55 }
56 #endregion
2:编码(Encode,Decode)
树构建起来后,我会用字典来保存字符和”赫夫曼编码“的对应表,然后拿着明文或者密文对着编码表翻译就行了, 复杂度O(N)。
1 #region 赫夫曼编码
2 /// <summary>
3 /// 赫夫曼编码
4 /// </summary>
5 /// <returns></returns>
6 public string Encode()
7 {
8 StringBuilder sb = new StringBuilder();
9
10 foreach (var item in word)
11 {
12 sb.Append(huffmanEncode[item]);
13 }
14
15 return sb.ToString();
16 }
17 #endregion
18
19 #region 赫夫曼解码
20 /// <summary>
21 /// 赫夫曼解码
22 /// </summary>
23 /// <returns></returns>
24 public string Decode(string str)
25 {
26 StringBuilder decode = new StringBuilder();
27
28 string temp = string.Empty;
29
30 for (int i = 0; i < str.Length; i++)
31 {
32 temp += str[i].ToString();
33
34 //如果包含 O(N)时间
35 if (huffmanDecode.ContainsKey(temp))
36 {
37 decode.Append(huffmanDecode[temp]);
38
39 temp = string.Empty;
40 }
41 }
42
43 return decode.ToString();
44 }
45 #endregion
最后我们做个例子,压缩9M的文件,看看到底能压缩多少?
1 public static void Main()
2 {
3 StringBuilder sb = new StringBuilder();
4
5 for (int i = 0; i < 1 * 10000; i++)
6 {
7 sb.Append("人民网北京12月8日电 (记者 宋心蕊) 北京时间8日晚的央视《新闻联播》节目出现了直播失误。上一条新闻尚未播放完毕时,播就将画面切换回了演播间,主播李梓萌开始播报下一条新闻,导致两条新闻出现了“混音”播出。央视新闻官方微博账号在21点09分发布了一条致歉微博:【致歉】今晚《新闻联播》因导播员口令失误,导致画面切换错误,特此向观众朋友表示歉意。央视特约评论员杨禹在个人微博中写道:今晚《新闻联播》出了个切换错误,@央视新闻 及时做了诚恳道歉。联播一直奉行“金标准”,压力源自全社会的高要求。其实报纸亦都有“勘误”一栏,坦诚纠错与道歉。《新闻联播》是中国影响力最大的电视新闻节目。它有不可替代的符号感,它有失误,更有悄然的进步。新的改进正在或即将发生,不妨期待");
8 }
9
10 File.WriteAllText(Environment.CurrentDirectory + "//1.txt", sb.ToString());
11
12 Huffman huffman = new Huffman(sb.ToString());
13
14 Stopwatch watch = Stopwatch.StartNew();
15
16 huffman.Build();
17
18 watch.Stop();
19
20 Console.WriteLine("构建赫夫曼树耗费:{0}", watch.ElapsedMilliseconds);
21
22 //将8位二进制转化为ascII码
23 var s = huffman.Encode();
24
25 var remain = s.Length % 8;
26
27 List<char> list = new List<char>();
28
29 var start = 0;
30
31 for (int i = 8; i < s.Length; i = i + 8)
32 {
33 list.Add((char)Convert.ToInt32(s.Substring(i - 8, 8), 2));
34
35 start = i;
36 }
37
38 var result = new String(list.ToArray());
39
40 //当字符编码不足8位时, 用‘艹'来标记,然后拿出’擦‘以后的所有0,1即可
41 result += "艹" + s.Substring(start);
42
43 File.WriteAllText(Environment.CurrentDirectory + "//2.txt", result);
44
45 Console.WriteLine("压缩完毕!");
46
47 Console.Read();
48
49 //解码
50 var str = File.ReadAllText(Environment.CurrentDirectory + "//2.txt");
51
52 sb.Clear();
53
54 for (int i = 0; i < str.Length; i++)
55 {
56 int ua = (int)str[i];
57
58 //说明已经取完毕了 用'艹'来做标记
59 if (ua == 33401)
60 sb.Append(str.Substring(i));
61 else
62 sb.Append(Convert.ToString(ua, 2).PadLeft(8, '0'));
63 }
64
65 var sss = huffman.Decode(sb.ToString());
66
67 Console.Read();
68 }
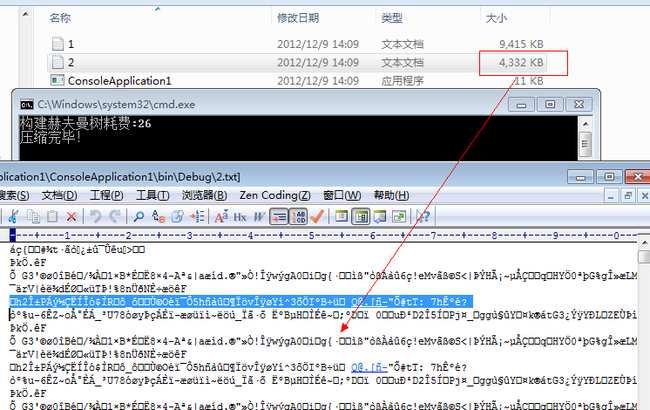
看看,多帅气,将9M的文件压缩到了4M,同时我也打开了压缩后的秘文,相信这些东西是什么,你懂我懂的。
主程序:
1 using System; 2 using System.Collections.Generic; 3 using System.Linq; 4 using System.Text; 5 using System.Diagnostics; 6 using System.Threading; 7 using System.IO; 8 9 namespace ConsoleApplication2 10 { 11 public class Program 12 { 13 public static void Main() 14 { 15 StringBuilder sb = new StringBuilder(); 16 17 for (int i = 0; i < 1 * 10000; i++) 18 { 19 sb.Append("人民网北京12月8日电 (记者 宋心蕊) 北京时间8日晚的央视《新闻联播》节目出现了直播失误。上一条新闻尚未播放完毕时,播就将画面切换回了演播间,主播李梓萌开始播报下一条新闻,导致两条新闻出现了“混音”播出。央视新闻官方微博账号在21点09分发布了一条致歉微博:【致歉】今晚《新闻联播》因导播员口令失误,导致画面切换错误,特此向观众朋友表示歉意。央视特约评论员杨禹在个人微博中写道:今晚《新闻联播》出了个切换错误,@央视新闻 及时做了诚恳道歉。联播一直奉行“金标准”,压力源自全社会的高要求。其实报纸亦都有“勘误”一栏,坦诚纠错与道歉。《新闻联播》是中国影响力最大的电视新闻节目。它有不可替代的符号感,它有失误,更有悄然的进步。新的改进正在或即将发生,不妨期待"); 20 } 21 22 File.WriteAllText(Environment.CurrentDirectory + "//1.txt", sb.ToString()); 23 24 Huffman huffman = new Huffman(sb.ToString()); 25 26 Stopwatch watch = Stopwatch.StartNew(); 27 28 huffman.Build(); 29 30 watch.Stop(); 31 32 Console.WriteLine("构建赫夫曼树耗费:{0}", watch.ElapsedMilliseconds); 33 34 //将8位二进制转化为ascII码 35 var s = huffman.Encode(); 36 37 var remain = s.Length % 8; 38 39 List<char> list = new List<char>(); 40 41 var start = 0; 42 43 for (int i = 8; i < s.Length; i = i + 8) 44 { 45 list.Add((char)Convert.ToInt32(s.Substring(i - 8, 8), 2)); 46 47 start = i; 48 } 49 50 var result = new String(list.ToArray()); 51 52 //当字符编码不足8位时, 用‘艹'来标记,然后拿出’擦‘以后的所有0,1即可 53 result += "艹" + s.Substring(start); 54 55 File.WriteAllText(Environment.CurrentDirectory + "//2.txt", result); 56 57 Console.WriteLine("压缩完毕!"); 58 59 Console.Read(); 60 61 //解码 62 var str = File.ReadAllText(Environment.CurrentDirectory + "//2.txt"); 63 64 sb.Clear(); 65 66 for (int i = 0; i < str.Length; i++) 67 { 68 int ua = (int)str[i]; 69 70 //说明已经取完毕了 用'艹'来做标记 71 if (ua == 33401) 72 sb.Append(str.Substring(i)); 73 else 74 sb.Append(Convert.ToString(ua, 2).PadLeft(8, '0')); 75 } 76 77 var sss = huffman.Decode(sb.ToString()); 78 79 Console.Read(); 80 } 81 } 82 83 public class Huffman 84 { 85 #region 赫夫曼节点 86 /// <summary> 87 /// 赫夫曼节点 88 /// </summary> 89 public class Node 90 { 91 /// <summary> 92 /// 左孩子 93 /// </summary> 94 public Node left; 95 96 /// <summary> 97 /// 右孩子 98 /// </summary> 99 public Node right; 100 101 /// <summary> 102 /// 父节点 103 /// </summary> 104 public Node parent; 105 106 /// <summary> 107 /// 节点字符 108 /// </summary> 109 public char c; 110 111 /// <summary> 112 /// 节点权重 113 /// </summary> 114 public int weight; 115 116 //赫夫曼“0"or“1" 117 public char huffmancode; 118 119 /// <summary> 120 /// 标记是否为叶子节点 121 /// </summary> 122 public bool isLeaf; 123 } 124 #endregion 125 126 PriorityQueue<Node> queue = new PriorityQueue<Node>(); 127 128 /// <summary> 129 /// 编码对应表(加速用) 130 /// </summary> 131 Dictionary<char, string> huffmanEncode = new Dictionary<char, string>(); 132 133 /// <summary> 134 /// 解码对应表(加速用) 135 /// </summary> 136 Dictionary<string, char> huffmanDecode = new Dictionary<string, char>(); 137 138 /// <summary> 139 /// 明文 140 /// </summary> 141 string word = string.Empty; 142 143 public Node root = new Node(); 144 145 public Huffman(string str) 146 { 147 this.word = str; 148 149 Dictionary<char, int> dic = new Dictionary<char, int>(); 150 151 foreach (var s in str) 152 { 153 if (dic.ContainsKey(s)) 154 dic[s] += 1; 155 else 156 dic[s] = 1; 157 } 158 159 foreach (var item in dic.Keys) 160 { 161 var node = new Node() 162 { 163 c = item, 164 weight = dic[item] 165 }; 166 167 //入队 168 queue.Eequeue(node, dic[item]); 169 } 170 } 171 172 #region 构建赫夫曼树 173 /// <summary> 174 /// 构建赫夫曼树 175 /// </summary> 176 public void Build() 177 { 178 //构建 179 while (queue.Count() > 0) 180 { 181 //如果只有一个节点,则说明已经到根节点了 182 if (queue.Count() == 1) 183 { 184 root = queue.Dequeue().t; 185 186 break; 187 } 188 189 //节点1 190 var node1 = queue.Dequeue(); 191 192 //节点2 193 var node2 = queue.Dequeue(); 194 195 //标记左孩子 196 node1.t.huffmancode = '0'; 197 198 //标记为右孩子 199 node2.t.huffmancode = '1'; 200 201 //判断当前节点是否为叶子节点,hufuman无度为1点节点(方便计算huffman编码) 202 if (node1.t.left == null) 203 node1.t.isLeaf = true; 204 205 if (node2.t.left == null) 206 node2.t.isLeaf = true; 207 208 //父节点 209 root = new Node(); 210 211 root.left = node1.t; 212 213 root.right = node2.t; 214 215 root.weight = node1.t.weight + node2.t.weight; 216 217 //当前节点为根节点 218 node1.t.parent = node2.t.parent = root; 219 220 //将当前节点的父节点入队列 221 queue.Eequeue(root, root.weight); 222 } 223 224 //深度优先统计各个字符的编码 225 DFS(root); 226 } 227 #endregion 228 229 #region 赫夫曼编码 230 /// <summary> 231 /// 赫夫曼编码 232 /// </summary> 233 /// <returns></returns> 234 public string Encode() 235 { 236 StringBuilder sb = new StringBuilder(); 237 238 foreach (var item in word) 239 { 240 sb.Append(huffmanEncode[item]); 241 } 242 243 return sb.ToString(); 244 } 245 #endregion 246 247 #region 赫夫曼解码 248 /// <summary> 249 /// 赫夫曼解码 250 /// </summary> 251 /// <returns></returns> 252 public string Decode(string str) 253 { 254 StringBuilder decode = new StringBuilder(); 255 256 string temp = string.Empty; 257 258 for (int i = 0; i < str.Length; i++) 259 { 260 temp += str[i].ToString(); 261 262 //如果包含 O(N)时间 263 if (huffmanDecode.ContainsKey(temp)) 264 { 265 decode.Append(huffmanDecode[temp]); 266 267 temp = string.Empty; 268 } 269 } 270 271 return decode.ToString(); 272 } 273 #endregion 274 275 #region 深度优先遍历子节点,统计各个节点的赫夫曼编码 276 /// <summary> 277 /// 深度优先遍历子节点,统计各个节点的赫夫曼编码 278 /// </summary> 279 /// <returns></returns> 280 public void DFS(Node node) 281 { 282 if (node == null) 283 return; 284 285 //遍历左子树 286 DFS(node.left); 287 288 //遍历右子树 289 DFS(node.right); 290 291 //如果当前叶节点 292 if (node.isLeaf) 293 { 294 string code = string.Empty; 295 296 var temp = node; 297 298 //回溯的找父亲节点的huffmancode LgN 的时间 299 while (temp.parent != null) 300 { 301 //注意,这里最后形成的 “反过来的编码” 302 code += temp.huffmancode; 303 304 temp = temp.parent; 305 } 306 307 var codetemp = new String(code.Reverse().ToArray()); 308 309 huffmanEncode.Add(node.c, codetemp); 310 311 huffmanDecode.Add(codetemp, node.c); 312 } 313 } 314 #endregion 315 } 316 }
小根堆:
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Diagnostics;
6 using System.Threading;
7 using System.IO;
8
9 namespace ConsoleApplication2
10 {
11 public class PriorityQueue<T> where T : class
12 {
13 /// <summary>
14 /// 定义一个数组来存放节点
15 /// </summary>
16 private List<HeapNode> nodeList = new List<HeapNode>();
17
18 #region 堆节点定义
19 /// <summary>
20 /// 堆节点定义
21 /// </summary>
22 public class HeapNode
23 {
24 /// <summary>
25 /// 实体数据
26 /// </summary>
27 public T t { get; set; }
28
29 /// <summary>
30 /// 优先级别 1-10个级别 (优先级别递增)
31 /// </summary>
32 public int level { get; set; }
33
34 public HeapNode(T t, int level)
35 {
36 this.t = t;
37 this.level = level;
38 }
39
40 public HeapNode() { }
41 }
42 #endregion
43
44 #region 添加操作
45 /// <summary>
46 /// 添加操作
47 /// </summary>
48 public void Eequeue(T t, int level = 1)
49 {
50 //将当前节点追加到堆尾
51 nodeList.Add(new HeapNode(t, level));
52
53 //如果只有一个节点,则不需要进行筛操作
54 if (nodeList.Count == 1)
55 return;
56
57 //获取最后一个非叶子节点
58 int parent = nodeList.Count / 2 - 1;
59
60 //堆调整
61 UpHeapAdjust(nodeList, parent);
62 }
63 #endregion
64
65 #region 对堆进行上滤操作,使得满足堆性质
66 /// <summary>
67 /// 对堆进行上滤操作,使得满足堆性质
68 /// </summary>
69 /// <param name="nodeList"></param>
70 /// <param name="index">非叶子节点的之后指针(这里要注意:我们
71 /// 的筛操作时针对非叶节点的)
72 /// </param>
73 public void UpHeapAdjust(List<HeapNode> nodeList, int parent)
74 {
75 while (parent >= 0)
76 {
77 //当前index节点的左孩子
78 var left = 2 * parent + 1;
79
80 //当前index节点的右孩子
81 var right = left + 1;
82
83 //parent子节点中最大的孩子节点,方便于parent进行比较
84 //默认为left节点
85 var min = left;
86
87 //判断当前节点是否有右孩子
88 if (right < nodeList.Count)
89 {
90 //判断parent要比较的最大子节点
91 min = nodeList[left].level < nodeList[right].level ? left : right;
92 }
93
94 //如果parent节点大于它的某个子节点的话,此时筛操作
95 if (nodeList[parent].level > nodeList[min].level)
96 {
97 //子节点和父节点进行交换操作
98 var temp = nodeList[parent];
99 nodeList[parent] = nodeList[min];
100 nodeList[min] = temp;
101
102 //继续进行更上一层的过滤
103 parent = (int)Math.Ceiling(parent / 2d) - 1;
104 }
105 else
106 {
107 break;
108 }
109 }
110 }
111 #endregion
112
113 #region 优先队列的出队操作
114 /// <summary>
115 /// 优先队列的出队操作
116 /// </summary>
117 /// <returns></returns>
118 public HeapNode Dequeue()
119 {
120 if (nodeList.Count == 0)
121 return null;
122
123 //出队列操作,弹出数据头元素
124 var pop = nodeList[0];
125
126 //用尾元素填充头元素
127 nodeList[0] = nodeList[nodeList.Count - 1];
128
129 //删除尾节点
130 nodeList.RemoveAt(nodeList.Count - 1);
131
132 //然后从根节点下滤堆
133 DownHeapAdjust(nodeList, 0);
134
135 return pop;
136 }
137 #endregion
138
139 #region 对堆进行下滤操作,使得满足堆性质
140 /// <summary>
141 /// 对堆进行下滤操作,使得满足堆性质
142 /// </summary>
143 /// <param name="nodeList"></param>
144 /// <param name="index">非叶子节点的之后指针(这里要注意:我们
145 /// 的筛操作时针对非叶节点的)
146 /// </param>
147 public void DownHeapAdjust(List<HeapNode> nodeList, int parent)
148 {
149 while (2 * parent + 1 < nodeList.Count)
150 {
151 //当前index节点的左孩子
152 var left = 2 * parent + 1;
153
154 //当前index节点的右孩子
155 var right = left + 1;
156
157 //parent子节点中最大的孩子节点,方便于parent进行比较
158 //默认为left节点
159 var min = left;
160
161 //判断当前节点是否有右孩子
162 if (right < nodeList.Count)
163 {
164 //判断parent要比较的最大子节点
165 min = nodeList[left].level < nodeList[right].level ? left : right;
166 }
167
168 //如果parent节点小于它的某个子节点的话,此时筛操作
169 if (nodeList[parent].level > nodeList[min].level)
170 {
171 //子节点和父节点进行交换操作
172 var temp = nodeList[parent];
173 nodeList[parent] = nodeList[min];
174 nodeList[min] = temp;
175
176 //继续进行更下一层的过滤
177 parent = min;
178 }
179 else
180 {
181 break;
182 }
183 }
184 }
185 #endregion
186
187 #region 获取元素并下降到指定的level级别
188 /// <summary>
189 /// 获取元素并下降到指定的level级别
190 /// </summary>
191 /// <returns></returns>
192 public HeapNode GetAndDownPriority(int level)
193 {
194 if (nodeList.Count == 0)
195 return null;
196
197 //获取头元素
198 var pop = nodeList[0];
199
200 //设置指定优先级(如果为 MinValue 则为 -- 操作)
201 nodeList[0].level = level == int.MinValue ? --nodeList[0].level : level;
202
203 //下滤堆
204 DownHeapAdjust(nodeList, 0);
205
206 return nodeList[0];
207 }
208 #endregion
209
210 #region 获取元素并下降优先级
211 /// <summary>
212 /// 获取元素并下降优先级
213 /// </summary>
214 /// <returns></returns>
215 public HeapNode GetAndDownPriority()
216 {
217 //下降一个优先级
218 return GetAndDownPriority(int.MinValue);
219 }
220 #endregion
221
222 #region 返回当前优先队列中的元素个数
223 /// <summary>
224 /// 返回当前优先队列中的元素个数
225 /// </summary>
226 /// <returns></returns>
227 public int Count()
228 {
229 return nodeList.Count;
230 }
231 #endregion
232 }
233 }