Hadoop2.3.0具体安装过程
前言:
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;并且它提供高吞吐量(high throughput)来訪问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,能够以流的形式訪问(streaming access)文件系统中的数据。
Hadoop的框架最核心的设计就是:HDFS和MapReduce.HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
1,系统架构
集群角色:
主机名 ip地址 角色
name01 192.168.52.128 NameNode、ResourceManager(JobTracker)
data01 192.168.52.129 NameNode、ResourceManager(JobTracker)
data02 192.168.52.130 DataNode、NodeManager(TaskTracker)
系统环境:
centos6.5 x64 vmware vpc
硬盘:30G
内存:1G
hadoop版本号:hadoop-2.3.0
2,环境准备
2.1 系统设置
关闭iptables:
/sbin/service iptables stop
/sbin/chkconfig iptables off
关闭selinux: setenforce 0
sed "s@^SELINUX=enforcing@SELINUX=disabled@g" /etc/sysconfig/selinux
设置节点名称,全部节点运行:
/bin/cat <<EOF> /etc/hosts
localhost.localdomain=data01 #或者name01,data02
192.168.52.128 name01
192.168.52.129 data01
192.168.52.130 data02
EOF
hostname node0*
send "s@HOSTNAME=localhost.localdomain@HOSTNAME=node0*@g" /etc/sysconfig/network
2.2 用户文件夹创建
创建hadoop运行账户:
使用root登陆全部机器后,全部的机器都创建hadoop用户
useradd hadoop #设置hadoop用户组
passwd hadoop
#sudo useradd –s /bin/bash –d /home/hadoop –m hadoop –g hadoop –G admin //加入一个zhm用户,此用户属于hadoop用户组,且具有admin权限。
#su hadoop //切换到zhm用户中
创建hadoop相关文件夹:
定义须要数据及文件夹的存放路径,定义代码及工具存放的路径
mkdir -p /home/hadoop/src
mkdir -p /home/hadoop/tools
chown -R hadoop.hadoop /home/hadoop/*
定义数据节点存放的路径到跟文件夹下的hadoop文件夹, 这里是数据节点存放文件夹须要有足够的空间存放
mkdir -p /data/hadoop/hdfs
mkdir -p /data/hadoop/tmp
mkdir -p /var/logs/hadoop
设置可写权限
chmod -R 777 /data/hadoop
chown -R hadoop.hadoop /data/hadoop/*
chown -R hadoop.hadoop /var/logs/hadoop
定义java安装程序路径
mkdir -p /usr/lib/jvm/
2.3 配置ssh免password登陆
參考文章地址:http://blog.csdn.net/ab198604/article/details/8250461
SSH主要通过RSA算法来产生公钥与私钥,在传输数据过程中对数据进行加密来保障数
据的安全性和可靠性,公钥部分是公共部分,网络上任一结点均能够訪问,私钥主要用于对数据进行加密,以防他人盗取数据。总而言之,这是一种非对称算法,
想要破解还是非常有难度的。Hadoop集群的各个结点之间须要进行数据的訪问,被訪问的结点对于訪问用户结点的可靠性必须进行验证,hadoop採用的是ssh的方
法通过密钥验证及数据加解密的方式进行远程安全登录操作,当然,假设hadoop对每一个结点的訪问均须要进行验证,其效率将会大大减少,所以才须要配置SSH免
password的方法直接远程连入被訪问结点,这样将大大提高訪问效率。
namenode节点配置免password登陆其它节点,每一个节点都要产生公钥password,Id_dsa.pub为公钥,id_dsa为私钥,紧接着将公钥文件复制成authorized_keys文件,这个步骤是必须的,步骤例如以下:
2.3.1 每一个节点分别产生密钥
# 提示:
(1):.ssh文件夹须要755权限,authorized_keys须要644权限;
(2):Linux防火墙开着,hadoop须要开的端口须要加入,或者关掉防火墙;
(3):数据节点连不上主服务器还有可能是使用了机器名的缘故,还是使用IP地址比較稳妥。
name01(192.168.52.128)主库上面:
namenode主节点hadoop账户创建服务器登陆公私钥:
mkdir -p /home/hadoop/.ssh
chown hadoop.hadoop -R /home/hadoop/.ssh
chmod 755 /home/hadoop/.ssh
su - hadoop
cd /home/hadoop/.ssh
ssh-keygen -t dsa -P '' -f id_dsa
[hadoop@name01 .ssh]$ ssh-keygen -t dsa -P '' -f id_dsa
Generating public/private dsa key pair.
open id_dsa failed: Permission denied.
Saving the key failed: id_dsa.
[hadoop@name01 .ssh]$
报错,解决的方法是: setenforce 0
[root@name01 .ssh]# setenforce 0
su - hadoop
[hadoop@name01 .ssh]$ ssh-keygen -t dsa -P '' -f id_dsa
Generating public/private dsa key pair.
Your identification has been saved in id_dsa.
Your public key has been saved in id_dsa.pub.
The key fingerprint is:
52:69:9a:ff:07:f4:fc:28:1e:48:18:fe:93:ca:ff:1d hadoop@name01
The key's randomart image is:
+--[ DSA 1024]----+
| |
| . |
| . + |
| . B . |
| * S. o |
| = o. o |
| * ..Eo |
| . . o.oo.. |
| o..o+o. |
+-----------------+
[hadoop@name01 .ssh]$ ll
total 12
-rw-------. 1 hadoop hadoop 668 Aug 20 23:58 id_dsa
-rw-r--r--. 1 hadoop hadoop 603 Aug 20 23:58 id_dsa.pub
drwxrwxr-x. 2 hadoop hadoop 4096 Aug 20 23:48 touch
[hadoop@name01 .ssh]$
Id_dsa.pub为公钥,id_dsa为私钥,紧接着将公钥文件复制成authorized_keys文件,这个步骤是必须的,步骤例如以下:
[hadoop@name01 .ssh]$ cat id_dsa.pub >> authorized_keys
[hadoop@name01 .ssh]$ ll
total 16
-rw-rw-r--. 1 hadoop hadoop 603 Aug 21 00:00 authorized_keys
-rw-------. 1 hadoop hadoop 668 Aug 20 23:58 id_dsa
-rw-r--r--. 1 hadoop hadoop 603 Aug 20 23:58 id_dsa.pub
drwxrwxr-x. 2 hadoop hadoop 4096 Aug 20 23:48 touch
[hadoop@name01 .ssh]$
用上述相同的方法在剩下的两个结点中如法炮制就可以。
data01(192.168.52.129)
2.3.2 在data01(192.168.52.129)上面运行:
useradd hadoop #设置hadoop用户组
passwd hadoop #设置hadooppassword为hadoop
setenforce 0
su - hadoop
mkdir -p /home/hadoop/.ssh
cd /home/hadoop/.ssh
ssh-keygen -t dsa -P '' -f id_dsa
cat id_dsa.pub >> authorized_keys
2.3.3 在data01(192.168.52.130)上面运行:
useradd hadoop #设置hadoop用户组
passwd hadoop #设置hadooppassword为hadoop
setenforce 0
su - hadoop
mkdir -p /home/hadoop/.ssh
cd /home/hadoop/.ssh
ssh-keygen -t dsa -P '' -f id_dsa
cat id_dsa.pub >> authorized_keys
2.3.4 构造3个通用的authorized_keys
在name01(192.168.52.128)上操作:
su - hadoop
cd /home/hadoop/.ssh
scp hadoop@data01:/home/hadoop/.ssh/id_dsa.pub ./id_dsa.pub.data01
scp hadoop@data02:/home/hadoop/.ssh/id_dsa.pub ./id_dsa.pub.data02
cat id_dsa.pub.data01 >> authorized_keys
cat id_dsa.pub.data02 >> authorized_keys
例如以下所看到的:
[hadoop@name01 .ssh]$ scp hadoop@data01:/home/hadoop/.ssh/id_dsa.pub ./id_dsa.pub.data01
The authenticity of host 'data01 (192.168.52.129)' can't be established.
RSA key fingerprint is 5b:22:7b:dc:0c:b8:bf:5c:92:aa:ff:93:3c:59:bd:d3.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'data01,192.168.52.129' (RSA) to the list of known hosts.
hadoop@data01's password:
Permission denied, please try again.
hadoop@data01's password:
id_dsa.pub 100% 603 0.6KB/s 00:00
[hadoop@name01 .ssh]$
[hadoop@name01 .ssh]$ scp hadoop@data02:/home/hadoop/.ssh/id_dsa.pub ./id_dsa.pub.data02
The authenticity of host 'data02 (192.168.52.130)' can't be established.
RSA key fingerprint is 5b:22:7b:dc:0c:b8:bf:5c:92:aa:ff:93:3c:59:bd:d3.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'data02,192.168.52.130' (RSA) to the list of known hosts.
hadoop@data02's password:
id_dsa.pub 100% 603 0.6KB/s 00:00
[hadoop@name01 .ssh]$
[hadoop@name01 .ssh]$ cat id_dsa.pub.data01 >> authorized_keys
[hadoop@name01 .ssh]$ cat id_dsa.pub.data02 >> authorized_keys
[hadoop@name01 .ssh]$ cat authorized_keys
ssh-dss AAAAB3NzaC1kc3MAAACBAI2jwEdOWNFFcpys/qB4OercYLY5o5XvBn8a5iy9K/WqYcaz35SimzxQxGtVxWq6AKoKaO0nfjE3m1muTP0grVd5i+HLzysRcpomdFc6z2PXnh4b8pA4QbFyYjxEAp5HszypYChEGGEgpBKoeOei5aA1+ufF1S6b8yEozskITUi7AAAAFQDff2ntRh50nYROstA6eV3IN2ql9QAAAIAtOFp2bEt9QGvWkkeiUV3dcdGd5WWYSHYP0jUULU4Wz0gvCmbpL6uyEDCAiF88GBNKbtDJKE0QN1/U9NtxL3RpO7brTOV7fH0insZ90cnDed6qmZTK4zXITlPACLafPzVB2y/ltH3z0gtctQWTydn0IzppS2U5oe39hWDmBBcYEwAAAIBbV8VEEwx9AUrv8ltbcZ3eUUScFansiNch9QNKZ0LeUEd4pjkvMAbuEAcJpdSqhgLBHsQxpxo3jXpM17vy+AiCds+bINggkvayE6ixRTBvQMcY6j1Bu7tyRmsGlC998HYBXbv/XyC9slCmzbPhvvTk4tAwHvlLkozP3sWt0lDtsw== hadoop@name01
ssh-dss AAAAB3NzaC1kc3MAAACBAJsVCOGZbKkL5gRMapCObhd1ndv1UHUCp3ZC89BGQEHJPKOz8DRM9wQYFLK7pWeCzr4Vt5ne8iNBVJ6LdXFt703b6dYZqp5zpV41R0wdh2wBAhfjO/FI8wUskAGDpnuqer+5XvbDFZgbkVlI/hdrOpKHoekY7hzX2lPO5gFNeU/dAAAAFQDhSINPQqNMjSnyZm5Zrx66+OEgKwAAAIBPQb5qza7EKbGnOL3QuP/ozLX73/7R6kxtrgfskqb8ejegJbeKXs4cZTdlhNfIeBew1wKQaASiklQRqYjYQJV5x5MaPHTvVwoWuSck/3oRdmvKVKBASElhTiiGLQL3Szor+eTbLU76xS+ydILwbeVh/MGyDfXdXRXfRFzSsOvCsAAAAIAeCGgfT8xjAO2M+VIRTbTA51ml1TqLRHjHoBYZmg65oz1/rnYfReeM0OidMcN0yEjUcuc99iBIE5e8DUVWPsqdDdtRAne5oXK2kWVu3PYIjx9l9f9A825gNicC4GAPRg0OOL54vaOgr8LFDJ9smpqK/p7gojCiSyzXltGqfajkpg== hadoop@data01
ssh-dss AAAAB3NzaC1kc3MAAACBAOpxZmz7oWUnhAiis2TiVWrBPaEtMZoxUYf8lmKKxtP+hM/lTDQyIK10bfKekJa52wNCR6q3lVxbFK0xHP04WHeb4Z0WjqNLNiE/U7h0gYCVG2M10sEFycy782jmBDwdc0R8MEy+nLRPmU5oPqcWBARxj0obg01PAj3wkfV+28zDAAAAFQC6a4yeCNX+lzIaGTd0nnxszMHhvwAAAIAevFSuiPi8Axa2ePP+rG/VS8QWcwmGcFZoR+K9TUdFJ4ZnfdKb4lqu78f9n68up2oJtajqXYuAzD08PerjWhPcLJAs/2qdGO1Ipiw/cXN2TyfHrnMcDr3+aEf7cUGHfWhwW4+1JrijHQ4Z9UeHNeEP6nU4I38FmS7gf9/f9MOVVwAAAIBlL1NsDXZUoEUXOws7tpMFfIaL7cXs7p5R+qk0BLdfllwUIwms++rKI9Ymf35l1U000pvaI8pz8s7I8Eo/dcCbWrpIZD1FqBMIqWhdG6sFP1qr9Nn4RZ00DxCz34ft4M8g+0CIn4Bg3pp4ZZES435R40F+jlrsnbLaXI+ixCzpqw== hadoop@data02
[hadoop@name01 .ssh]$
看到authorized_keys文件中面有3行记录,分别代表了訪问name01,data01,data02的公用密钥。把这个authorized_keys公钥文件copy到data01和data02上面同一个文件夹下。
然后通过hadoop远程彼此连接name01、data01、data02就能够免password了
scp authorized_keys hadoop@data01:/home/hadoop/.ssh/
scp authorized_keys hadoop@data02:/home/hadoop/.ssh/
然后分别在name01、data01、data02以hadoop用户运行权限赋予操作
su - hadoop
chmod 600 /home/hadoop/.ssh/authorized_keys
chmod 700 -R /home/hadoop/.ssh
測试ssh免秘钥登录,首次连接的时候,须要输入yes,之后就不用输入password直接能够ssh过去了。
[hadoop@name01 .ssh]$ ssh hadoop@data01
Last login: Thu Aug 21 01:53:24 2014 from name01
[hadoop@data01 ~]$ ssh hadoop@data02
The authenticity of host 'data02 (192.168.52.130)' can't be established.
RSA key fingerprint is 5b:22:7b:dc:0c:b8:bf:5c:92:aa:ff:93:3c:59:bd:d3.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'data02,192.168.52.130' (RSA) to the list of known hosts.
[hadoop@data02 ~]$ ssh hadoop@name01
The authenticity of host 'name01 (::1)' can't be established.
RSA key fingerprint is 5b:22:7b:dc:0c:b8:bf:5c:92:aa:ff:93:3c:59:bd:d3.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'name01' (RSA) to the list of known hosts.
Last login: Thu Aug 21 01:56:12 2014 from data01
[hadoop@data02 ~]$ ssh hadoop@name01
Last login: Thu Aug 21 01:56:22 2014 from localhost.localdomain
[hadoop@data02 ~]$
看到问题所在,从data01、data02上面ssh到name01上面没有成功,问题再哪里?
2.3.5 解决ssh name01失败的问题
[hadoop@data01 ~]$ ssh name01
Last login: Thu Aug 21 02:25:28 2014 from localhost.localdomain
[hadoop@data01 ~]$
确实没有成功,退出来看看/etc/hosts的设置
[hadoop@data01 ~]$ exit
logout
[root@data01 ~]#
[root@data01 ~]# vim /etc/hosts
#127.0.0.1 localhost.localdomain localhost.localdomain localhost4 localhost4.localdomain4 localhost name01
#::1 localhost.localdomain localhost.localdomain localhost6 localhost6.localdomain6 localhost name01
localhost.localdomain=data01
192.168.52.128 name01
192.168.52.129 data01
192.168.52.130 data02
保存退出
[root@data01 ~]# su - hadoop
[hadoop@data02 ~]$ ssh name01
Warning: Permanently added the RSA host key for IP address '192.168.52.128' to the list of known hosts.
Last login: Thu Aug 21 02:32:32 2014 from data01
[hadoop@name01 ~]$
OK,ssh远程连接name01成功,解决方法vim hosts凝视掉前面两行搞定,例如以下所看到的:
[root@data01 ~]# vim /etc/hosts
#127.0.0.1 localhost.localdomain localhost.localdomain localhost4 localhost4.localdomain4 localhost name01
#::1 localhost.localdomain localhost.localdomain localhost6 localhost6.localdomain6 localhost name01
2.3.6 验证name01、data01、data02不论什么ssh免password登录
[hadoop@data02 ~]$ ssh name01
Last login: Thu Aug 21 02:38:46 2014 from data02
[hadoop@name01 ~]$ ssh data01
Last login: Thu Aug 21 02:30:35 2014 from localhost.localdomain
[hadoop@data01 ~]$ ssh data02
Last login: Thu Aug 21 02:32:57 2014 from localhost.localdomain
[hadoop@data02 ~]$ ssh data01
Last login: Thu Aug 21 02:39:55 2014 from name01
[hadoop@data01 ~]$ ssh name01
Last login: Thu Aug 21 02:39:51 2014 from data02
[hadoop@name01 ~]$ ssh data02
Last login: Thu Aug 21 02:39:58 2014 from data01
[hadoop@data02 ~]$
3,安装部署hadoop环境
3.1 java环境准备
root账户全部节点部署java环境:
安装jdk7版本号,请參考:http://blog.itpub.net/26230597/viewspace-1256321/
3.2,安装hadoop
3.2.1 版本号2.2.0安装
下载软件包:
mkdir /s
chown -R hadoop.hadoop /soft
从本地copy到linux虚拟机
su - hadoop
cd /soft/hadoop
tar zxvf hadoop-2.3.0-x64.tar.gz -C /home/hadoop/src/
配置环境变量:
使用root环境变量设置
cat <<EOF>> /etc/profile
export HADOOP_HOME=/home/hadoop/src/hadoop-2.3.0
export JAVA_HOME=/usr/lib/jvm/jdk1.7.0_60/
export PATH=/home/hadoop/src/hadoop-2.3.0/bin:/home/hadoop/src/hadoop-2.3.0/sbin:$PATH
EOF
source /etc/profile
3.3,hadoop配置文件
hadoop群集涉及配置文件:hadoop-env.sh core-site.xml hdfs-site.xml mapred-site.xml yarn-env.sh slaves yarn-site.xml
涉及到的配置文件有7个:
cp /home/hadoop/src/hadoop-2.3.0/etc/hadoop
hadoop-env.sh
yarn-env.sh
slaves
core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml
以上个别文件默认不存在的,能够复制相应的template文件获得
a.改动hadoop-env.sh配置:
vim hadoop-env.sh
添加java环境变量
export JAVA_HOME="/usr/lib/jvm/jdk1.7.0_60"
b.改动yarn-env.sh配置:
vim yarn-env.sh
改动java_home值为 export JAVA_HOME="/usr/lib/jvm/jdk1.7.0_60"
c.改动slaves配置,写入全部从节点主机名:
vim slaves
data01
data02
d.改动core-site.xml配置文件:
vim core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://name01:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop/tmp</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>hadoop.proxyuser.hduser.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hduser.groups</name>
<value>*</value>
</property>
</configuration>
e.改动hdfs-site.xml配置:
创建相关文件夹
mkdir -p /data/hadoop/name
chown -R hadoop.hadoop /data/hadoop/name
mkdir -p /data/hadoop/data
chown -R hadoop.hadoop /data/hadoop/data
vim hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>name01:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/data/hadoop/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/data/hadoop/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
<description>storage copy number</description>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
f.改动mapred-site.xml配置
#这个文件不存在,须要自己VIM创建
vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>name01:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>name01:19888</value>
</property>
# <property>
# <name>mapred.job.tracker</name>
# <value>name01:9001</value>
# <description>JobTracker visit path</description>
# </property>
</configuration>
g.改动yarn-site.xml配置:
vim yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>name01:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>name01:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>name01:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>name01:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>name01:8088</value>
</property>
</configuration>
全部节点採用相同的配置文件和安装文件夹,直接整个文件夹copy过去安装把name01上面的全部hadoop文件夹copy到data02上面去:
scp -r /home/hadoop/* hadoop@data02:/home/hadoop/
scp -r /data/hadoop/* hadoop@data02:/data/hadoop/
把name01上面的全部hadoop文件夹copy到data01上面去:
scp -r /home/hadoop/* hadoop@data01:/home/hadoop/
scp -r /data/hadoop/* hadoop@data01:/data/hadoop/
3.3,格式化文件系统
在name01主库上面运行 hadoop namenode -format操作,格式化hdfs文件系统。
su - hadoop
[hadoop@localhost ~]$ hadoop namenode -format
[hadoop@name01 bin]$ hadoop namenode -format
DEPRECATED: Use of this script to execute hdfs command is deprecated.
Instead use the hdfs command for it.
14/08/21 04:51:20 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = name01/192.168.52.128
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.3.0
STARTUP_MSG: classpath = /home/hadoop/src/hadoop-2.3.0/etc/hadoop:/home/hadoop/src/hadoop-2.3.0/share/hadoop/common/lib/commons-beanutils-core-1.8.0.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/common/lib/servlet-api-2.5.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/common/lib/slf4j-api-1.7.5.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/common/lib/commons-configuration-1.6.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/common/lib/commons-beanutils-1.7.0.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/common/lib/mockito-all-1.8.5.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/common/lib/commons-httpclient-3.1.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/common/lib/jsp-api-2.1.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/common/lib/jetty-6.1.26.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/common/lib/httpcore-4.2.5.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/common/lib/jackson-xc-1.8.8.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/common/lib/junit-4.8.2.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/common/lib/jaxb-impl-2.2.3-1.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/common/lib/jackson-core-asl-1.8.8.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/common/lib/commons-el-1.0.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/common/lib/jackson-mapper-asl-1.8.8.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/common/lib/commons-digester-1.8.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/common/lib/commons-lang-2.6.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/common/lib/httpclient-4.2.5.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/common/lib/zookeeper-3.4.5.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/common/lib/hadoop-auth-2.3.0.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/common/lib/asm-3.2.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/common/lib/log4j-1.2.17.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/common/lib/xmlenc-0.52.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/common/lib/commons-net-3.1.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/common/lib/jsr305-1.3.9.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/common/lib/guava-11.0.2.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/common/lib/jaxb-api-2.2.2.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/common/lib/jasper-compiler-5.5.23.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/common/lib/jetty-util-6.1.26.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/common/lib/commons-collections-3.2.1.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/common/lib/commons-codec-1.4.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/common/lib/jets3t-0.9.0.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/common/lib/jersey-server-1.9.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/common/lib/paranamer-2.3.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/common/lib/xz-1.0.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/common/lib/hadoop-annotations-2.3.0.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/common/lib/commons-io-2.4.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/common/lib/commons-compress-1.4.1.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/common/lib/netty-3.6.2.Final.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/common/lib/commons-cli-1.2.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/common/lib/snappy-java-1.0.4.1.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/common/lib/jasper-runtime-5.5.23.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/common/lib/avro-1.7.4.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/common/lib/protobuf-java-2.5.0.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/common/lib/commons-math3-3.1.1.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/common/lib/java-xmlbuilder-0.4.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/common/lib/jersey-json-1.9.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/common/lib/jersey-core-1.9.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/common/lib/activation-1.1.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/common/lib/stax-api-1.0-2.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/common/lib/jettison-1.1.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/common/lib/commons-logging-1.1.3.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/common/lib/jackson-jaxrs-1.8.8.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/common/lib/jsch-0.1.42.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/common/hadoop-common-2.3.0.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/common/hadoop-nfs-2.3.0.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/common/hadoop-common-2.3.0-tests.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/hdfs:/home/hadoop/src/hadoop-2.3.0/share/hadoop/hdfs/lib/servlet-api-2.5.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/hdfs/lib/jsp-api-2.1.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/hdfs/lib/jetty-6.1.26.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/hdfs/lib/commons-daemon-1.0.13.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/hdfs/lib/jackson-core-asl-1.8.8.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/hdfs/lib/commons-el-1.0.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/hdfs/lib/jackson-mapper-asl-1.8.8.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/hdfs/lib/commons-lang-2.6.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/hdfs/lib/asm-3.2.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/hdfs/lib/log4j-1.2.17.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/hdfs/lib/xmlenc-0.52.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/hdfs/lib/jsr305-1.3.9.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/hdfs/lib/guava-11.0.2.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/hdfs/lib/jetty-util-6.1.26.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/hdfs/lib/commons-codec-1.4.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/hdfs/lib/jersey-server-1.9.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/hdfs/lib/commons-io-2.4.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/hdfs/lib/netty-3.6.2.Final.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/hdfs/lib/commons-cli-1.2.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/hdfs/lib/jasper-runtime-5.5.23.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/hdfs/lib/protobuf-java-2.5.0.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/hdfs/lib/jersey-core-1.9.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/hdfs/lib/commons-logging-1.1.3.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/hdfs/hadoop-hdfs-2.3.0-tests.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/hdfs/hadoop-hdfs-2.3.0.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/hdfs/hadoop-hdfs-nfs-2.3.0.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/yarn/lib/servlet-api-2.5.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/yarn/lib/commons-httpclient-3.1.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/yarn/lib/jetty-6.1.26.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/yarn/lib/aopalliance-1.0.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/yarn/lib/jackson-xc-1.8.8.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/yarn/lib/guice-servlet-3.0.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/yarn/lib/jaxb-impl-2.2.3-1.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/yarn/lib/jackson-core-asl-1.8.8.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/yarn/lib/jackson-mapper-asl-1.8.8.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/yarn/lib/commons-lang-2.6.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/yarn/lib/zookeeper-3.4.5.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/yarn/lib/jersey-guice-1.9.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/yarn/lib/jline-0.9.94.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/yarn/lib/guice-3.0.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/yarn/lib/asm-3.2.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/yarn/lib/log4j-1.2.17.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/yarn/lib/jsr305-1.3.9.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/yarn/lib/guava-11.0.2.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/yarn/lib/jaxb-api-2.2.2.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/yarn/lib/jetty-util-6.1.26.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/yarn/lib/commons-codec-1.4.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/yarn/lib/jersey-client-1.9.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/yarn/lib/javax.inject-1.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/yarn/lib/jersey-server-1.9.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/yarn/lib/xz-1.0.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/yarn/lib/commons-io-2.4.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/yarn/lib/commons-compress-1.4.1.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/yarn/lib/commons-cli-1.2.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/yarn/lib/protobuf-java-2.5.0.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/yarn/lib/jersey-json-1.9.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/yarn/lib/jersey-core-1.9.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/yarn/lib/activation-1.1.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/yarn/lib/stax-api-1.0-2.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/yarn/lib/jettison-1.1.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/yarn/lib/commons-logging-1.1.3.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/yarn/lib/jackson-jaxrs-1.8.8.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/yarn/hadoop-yarn-server-tests-2.3.0.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/yarn/hadoop-yarn-common-2.3.0.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/yarn/hadoop-yarn-client-2.3.0.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/yarn/hadoop-yarn-server-resourcemanager-2.3.0.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/yarn/hadoop-yarn-applications-distributedshell-2.3.0.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/yarn/hadoop-yarn-api-2.3.0.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/yarn/hadoop-yarn-server-common-2.3.0.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/yarn/hadoop-yarn-applications-unmanaged-am-launcher-2.3.0.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/yarn/hadoop-yarn-server-web-proxy-2.3.0.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/yarn/hadoop-yarn-server-nodemanager-2.3.0.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/mapreduce/lib/aopalliance-1.0.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/mapreduce/lib/guice-servlet-3.0.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/mapreduce/lib/jackson-core-asl-1.8.8.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/mapreduce/lib/jackson-mapper-asl-1.8.8.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/mapreduce/lib/junit-4.10.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/mapreduce/lib/jersey-guice-1.9.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/mapreduce/lib/guice-3.0.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/mapreduce/lib/asm-3.2.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/mapreduce/lib/hamcrest-core-1.1.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/mapreduce/lib/log4j-1.2.17.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/mapreduce/lib/javax.inject-1.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/mapreduce/lib/jersey-server-1.9.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/mapreduce/lib/paranamer-2.3.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/mapreduce/lib/xz-1.0.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/mapreduce/lib/hadoop-annotations-2.3.0.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/mapreduce/lib/commons-io-2.4.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/mapreduce/lib/commons-compress-1.4.1.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/mapreduce/lib/netty-3.6.2.Final.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/mapreduce/lib/snappy-java-1.0.4.1.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/mapreduce/lib/avro-1.7.4.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/mapreduce/lib/protobuf-java-2.5.0.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/mapreduce/lib/jersey-core-1.9.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/mapreduce/hadoop-mapreduce-client-app-2.3.0.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.3.0-tests.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/mapreduce/hadoop-mapreduce-client-common-2.3.0.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.3.0.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/mapreduce/hadoop-mapreduce-client-hs-plugins-2.3.0.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/mapreduce/hadoop-mapreduce-client-shuffle-2.3.0.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/mapreduce/hadoop-mapreduce-client-hs-2.3.0.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/mapreduce/hadoop-mapreduce-client-core-2.3.0.jar:/home/hadoop/src/hadoop-2.3.0/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.3.0.jar:/home/hadoop/src/hadoop-2.3.0/contrib/capacity-scheduler/*.jar:/home/hadoop/src/hadoop-2.3.0/contrib/capacity-scheduler/*.jar
STARTUP_MSG: build = Unknown -r Unknown; compiled by 'root' on 2014-03-03T02:27Z
STARTUP_MSG: java = 1.7.0_60
************************************************************/
14/08/21 04:51:20 INFO namenode.NameNode: registered UNIX signal handlers for [TERM, HUP, INT]
Formatting using clusterid: CID-9a84257b-77e1-4f79-a5bb-b9564061bc52
14/08/21 04:51:24 INFO namenode.FSNamesystem: fsLock is fair:true
14/08/21 04:51:24 INFO namenode.HostFileManager: read includes:
HostSet(
)
14/08/21 04:51:24 INFO namenode.HostFileManager: read excludes:
HostSet(
)
14/08/21 04:51:24 INFO blockmanagement.DatanodeManager: dfs.block.invalidate.limit=1000
14/08/21 04:51:24 INFO blockmanagement.DatanodeManager: dfs.namenode.datanode.registration.ip-hostname-check=true
14/08/21 04:51:24 INFO util.GSet: Computing capacity for map BlocksMap
14/08/21 04:51:24 INFO util.GSet: VM type = 64-bit
14/08/21 04:51:24 INFO util.GSet: 2.0% max memory 966.7 MB = 19.3 MB
14/08/21 04:51:24 INFO util.GSet: capacity = 2^21 = 2097152 entries
14/08/21 04:51:24 INFO blockmanagement.BlockManager: dfs.block.access.token.enable=false
14/08/21 04:51:24 INFO blockmanagement.BlockManager: defaultReplication = 3
14/08/21 04:51:24 INFO blockmanagement.BlockManager: maxReplication = 512
14/08/21 04:51:24 INFO blockmanagement.BlockManager: minReplication = 1
14/08/21 04:51:24 INFO blockmanagement.BlockManager: maxReplicationStreams = 2
14/08/21 04:51:24 INFO blockmanagement.BlockManager: shouldCheckForEnoughRacks = false
14/08/21 04:51:24 INFO blockmanagement.BlockManager: replicationRecheckInterval = 3000
14/08/21 04:51:24 INFO blockmanagement.BlockManager: encryptDataTransfer = false
14/08/21 04:51:24 INFO blockmanagement.BlockManager: maxNumBlocksToLog = 1000
14/08/21 04:51:25 INFO namenode.FSNamesystem: fsOwner = hadoop (auth:SIMPLE)
14/08/21 04:51:25 INFO namenode.FSNamesystem: supergroup = supergroup
14/08/21 04:51:25 INFO namenode.FSNamesystem: isPermissionEnabled = true
14/08/21 04:51:25 INFO namenode.FSNamesystem: HA Enabled: false
14/08/21 04:51:25 INFO namenode.FSNamesystem: Append Enabled: true
14/08/21 04:51:26 INFO util.GSet: Computing capacity for map INodeMap
14/08/21 04:51:26 INFO util.GSet: VM type = 64-bit
14/08/21 04:51:26 INFO util.GSet: 1.0% max memory 966.7 MB = 9.7 MB
14/08/21 04:51:26 INFO util.GSet: capacity = 2^20 = 1048576 entries
14/08/21 04:51:26 INFO namenode.NameNode: Caching file names occuring more than 10 times
14/08/21 04:51:26 INFO util.GSet: Computing capacity for map cachedBlocks
14/08/21 04:51:26 INFO util.GSet: VM type = 64-bit
14/08/21 04:51:26 INFO util.GSet: 0.25% max memory 966.7 MB = 2.4 MB
14/08/21 04:51:26 INFO util.GSet: capacity = 2^18 = 262144 entries
14/08/21 04:51:26 INFO namenode.FSNamesystem: dfs.namenode.safemode.threshold-pct = 0.9990000128746033
14/08/21 04:51:26 INFO namenode.FSNamesystem: dfs.namenode.safemode.min.datanodes = 0
14/08/21 04:51:26 INFO namenode.FSNamesystem: dfs.namenode.safemode.extension = 30000
14/08/21 04:51:26 INFO namenode.FSNamesystem: Retry cache on namenode is enabled
14/08/21 04:51:26 INFO namenode.FSNamesystem: Retry cache will use 0.03 of total heap and retry cache entry expiry time is 600000 millis
14/08/21 04:51:26 INFO util.GSet: Computing capacity for map Namenode Retry Cache
14/08/21 04:51:26 INFO util.GSet: VM type = 64-bit
14/08/21 04:51:26 INFO util.GSet: 0.029999999329447746% max memory 966.7 MB = 297.0 KB
14/08/21 04:51:26 INFO util.GSet: capacity = 2^15 = 32768 entries
14/08/21 04:51:27 INFO common.Storage: Storage directory /data/hadoop/name has been successfully formatted.
14/08/21 04:51:27 INFO namenode.FSImage: Saving image file /data/hadoop/name/current/fsimage.ckpt_0000000000000000000 using no compression
14/08/21 04:51:27 INFO namenode.FSImage: Image file /data/hadoop/name/current/fsimage.ckpt_0000000000000000000 of size 218 bytes saved in 0 seconds.
14/08/21 04:51:27 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
14/08/21 04:51:27 INFO util.ExitUtil: Exiting with status 0
14/08/21 04:51:27 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at name01/192.168.52.128
************************************************************/
注意:上面仅仅要出现“successfully formatted”就表示成功了,仅仅在第一次启动的时候格式化,不要每次启动都格式化。理解为我们新买了块移动硬盘,使用之前总要格式化硬盘。假设真的有必要再次格式化,请先把“$HADOOP_HOME/tmp”文件夹下的文件全部删除。
读者能够自己观察文件夹”$HADOOP_HOME/tmp”在格式化前后的变化情况。格式化操作非常少有出现失败的情况。假设真出现了,请检查配置是否正确。
3.4,hadoop管理
3.4.1 格式化完毕后,開始启动hadoop 程序启动hadoop 的命令脚本都在$HADOOP_HOME/sbin/下,以下的全部命令都不再带有完整路径名称:
distribute-exclude.sh hdfs-config.sh slaves.sh start-dfs.cmd start-yarn.sh stop-dfs.cmd stop-yarn.sh
hadoop-daemon.sh httpfs.sh start-all.cmd start-dfs.sh stop-all.cmd stop-dfs.sh yarn-daemon.sh
hadoop-daemons.sh mr-jobhistory-daemon.sh start-all.sh start-secure-dns.sh stop-all.sh stop-secure-dns.sh yarn-daemons.sh
hdfs-config.cmd refresh-namenodes.sh start-balancer.sh start-yarn.cmd stop-balancer.sh stop-yarn.cmd
讲述hadoop 启动的三种方式:
3.4.2,第一种,一次性全部启动:
运行start-all.sh 启动hadoop,观察控制台的输出,能够看到正在启动进程,各自是namenode、datanode、secondarynamenode、jobtracker、tasktracker,一共5 个,待运行完毕后,并不意味着这5 个进程成功启动,上面仅仅表示系统正在启动进程而已。我们使用jdk 的命令jps 查看进程是否已经正确启动。运行以下jps,假设看到了这5 个进程,说明hadoop 真的启动成功了。假设缺少一个或者多个,那就进入到“Hadoop的常见启动错误”章节寻找原因了。
停止应用:
/home/hadoop/src/hadoop-2.3.0/sbin/stop-all.sh
启动应用:
/home/hadoop/src/hadoop-2.3.0/sbin/start-all.sh
[hadoop@name01 hadoop]$ /home/hadoop/src/hadoop-2.3.0/sbin/start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
Starting namenodes on [name01]
name01: starting namenode, logging to /home/hadoop/src/hadoop-2.3.0/logs/hadoop-hadoop-namenode-name01.out
data01: starting datanode, logging to /home/hadoop/src/hadoop-2.3.0/logs/hadoop-hadoop-datanode-name01.out
data02: starting datanode, logging to /home/hadoop/src/hadoop-2.3.0/logs/hadoop-hadoop-datanode-name01.out
Starting secondary namenodes [name01]
name01: starting secondarynamenode, logging to /home/hadoop/src/hadoop-2.3.0/logs/hadoop-hadoop-secondarynamenode-name01.out
starting yarn daemons
starting resourcemanager, logging to /home/hadoop/src/hadoop-2.3.0/logs/yarn-hadoop-resourcemanager-name01.out
data02: starting nodemanager, logging to /home/hadoop/src/hadoop-2.3.0/logs/yarn-hadoop-nodemanager-name01.out
data01: starting nodemanager, logging to /home/hadoop/src/hadoop-2.3.0/logs/yarn-hadoop-nodemanager-name01.out
[hadoop@name01 bin]$
3.4.2.1,检查后台各个节点运行的hadoop进程
[hadoop@name01 hadoop]$ jps
8862 Jps
8601 ResourceManager
8458 SecondaryNameNode
8285 NameNode
[hadoop@name01 hadoop]$
[hadoop@name01 ~]$ jps
-bash: jps: command not found
[hadoop@name01 ~]$
[hadoop@name01 ~]$ /usr/lib/jvm/jdk1.7.0_60/bin/jps
5812 NodeManager
6047 Jps
5750 DataNode
[hadoop@name01 ~]$
[root@data01 ~]# jps
5812 NodeManager
6121 Jps
5750 DataNode
[root@data01 ~]
3.4.2.2,为什么在root下能单独用jps命令,su到hadoop不行,search了下,原因是我载入jdk路径的时候用的是
vim ~/.bashrc
export JAVA_HOME=/usr/lib/jvm/jdk1.7.0_60
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
保存退出,然后输入以下的命令来使之生效
source ~/.bashrc
方式,这样的仅仅对当前用户生效,我的jdk是用root安装的,所以su到hadoop就无法生效了,怎么办?用/etc/profile,在文件最末端加入jdk路径
[root@data01 ~]# vim /etc/profile
export JAVA_HOME=/usr/lib/jvm/jdk1.7.0_60
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
#保存退出,然后输入以下的命令来使之生效:
[root@data01 ~]# source /etc/profile
su - hadoop
[hadoop@data01 ~]$ jps
6891 DataNode
7025 NodeManager
8354 Jps
[hadoop@data01 ~]$
OK,在hadoop账号下,jps也生效
3.4.2.3,再去data02节点下检查
[hadoop@data02 ~]$ jps
11528 Jps
10609 NodeManager
10540 DataNode
[hadoop@data02 ~]$
查看到2个data节点的进程都启动起来了,恭喜····
3.4.2.4,通过站点查看hadoop集群情况
在浏览器中输入:http://192.168.52.128:50030/dfshealth.html,网址为name01结点(也就是master主库节点)所相应的IP:

结果显示一片空白:
在浏览器中输入:http://192.168.1.100:50070,网址为name01结点(也就是master主库节点)所相应的IP:
进入http://192.168.52.128:50070/dfshealth.html#tab-overview,看集群基本信息,例如以下图所看到的: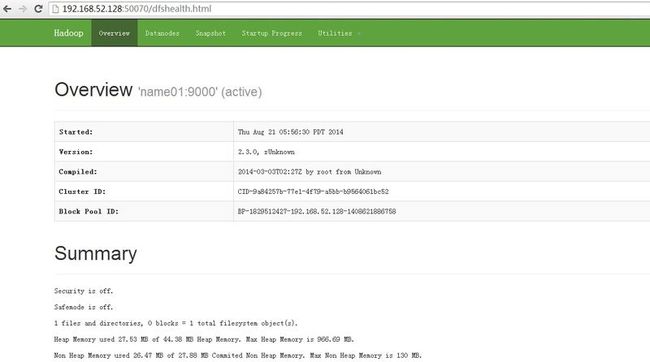
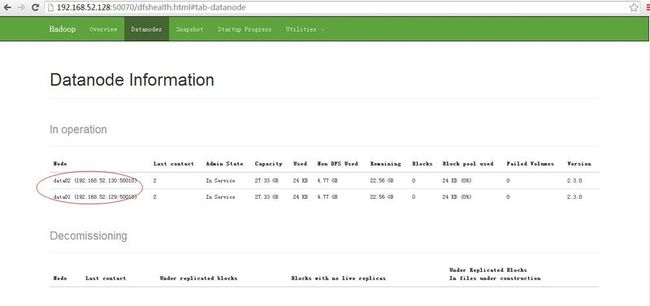
进入http://192.168.52.128:50070/dfshealth.html#tab-datanode,看datanode信息,例如以下图所看到的:
进入http://192.168.52.128:50070/logs/,查看全部日志信息,例如以下图所看到的:
至此,hadoop的全然分布式集群安装已经全部完毕,能够好好睡个觉了。~~
3.4.2.5,关闭hadoop 的命令是stop-all.sh,例如以下所看到的:
[hadoop@name01 src]$ /home/hadoop/src/hadoop-2.3.0/sbin/stop-all.sh
This script is Deprecated. Instead use stop-dfs.sh and stop-yarn.sh
Stopping namenodes on [name01]
name01: stopping namenode
data01: stopping datanode
data02: stopping datanode
Stopping secondary namenodes [name01]
name01: stopping secondarynamenode
stopping yarn daemons
stopping resourcemanager
data02: stopping nodemanager
data01: stopping nodemanager
no proxyserver to stop
[hadoop@name01 src]$
上面的命令是最简单的,能够一次性把全部节点都启动、关闭。
3.4.3,第二种,分别启动HDFS 和yarn:
运行命令start-dfs.sh,是单独启动hdfs。运行完该命令后,通过jps 能够看到NameNode、DataNode、SecondaryNameNode 三个进程启动了,该命令适合于仅仅运行hdfs
存储不使用yarn做资源管理。关闭的命令就是stop-dfs.sh 了。
3.4.3.1 先启动HDFS
[hadoop@name01 sbin]$ jps
3687 Jps
[hadoop@name01 sbin]$ pwd
/home/hadoop/src/hadoop-2.3.0/sbin
[hadoop@name01 sbin]$ start-dfs.sh
Starting namenodes on [name01]
name01: starting namenode, logging to /home/hadoop/src/hadoop-2.3.0/logs/hadoop-hadoop-namenode-name01.out
data01: starting datanode, logging to /home/hadoop/src/hadoop-2.3.0/logs/hadoop-hadoop-datanode-data01.out
data02: starting datanode, logging to /home/hadoop/src/hadoop-2.3.0/logs/hadoop-hadoop-datanode-data02.out
Starting secondary namenodes [name01]
name01: starting secondarynamenode, logging to /home/hadoop/src/hadoop-2.3.0/logs/hadoop-hadoop-secondarynamenode-name01.out
在name01节点下,查看后台的jps进程例如以下:
[hadoop@name01 sbin]$ jps
4081 Jps
3800 NameNode
3977 SecondaryNameNode
[hadoop@name01 sbin]$
[root@hadoop03 src]# jps
13894 Jps
13859 DataNode
去data01节点看下,后台的jps进程例如以下:
[hadoop@data01 ~]$ jps
3194 Jps
2863 DataNode
[hadoop@data01 ~]$
3.4.3.2 再启动yarn
运行命令start-yarn.sh,能够单独启动资源管理器的服务器端和客户端进程,关闭的命令就是stop-yarn.sh
[hadoop@name01 sbin]$ start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /home/hadoop/src/hadoop-2.3.0/logs/yarn-hadoop-resourcemanager-name01.out
data01: starting nodemanager, logging to /home/hadoop/src/hadoop-2.3.0/logs/yarn-hadoop-nodemanager-data01.out
data02: starting nodemanager, logging to /home/hadoop/src/hadoop-2.3.0/logs/yarn-hadoop-nodemanager-data02.out
在name01节点下,查看后台的jps进程,多了一个ResourceManager进程,例如以下所看到的:
[hadoop@name01 sbin]$ jps
4601 ResourceManager
3800 NameNode
4853 Jps
3977 SecondaryNameNode
[hadoop@name01 sbin]$
去data01节点看下,后台的jps进程多了一个NodeManager进程,例如以下所看到的:
[hadoop@data01 ~]$ jps
3249 NodeManager
2863 DataNode
3365 Jps
[hadoop@data01 ~]$
3.4.3.3 依次关闭,先关闭yarn再关闭HDFS
[hadoop@name01 sbin]$ stop-yarn.sh
stopping yarn daemons
stopping resourcemanager
data01: stopping nodemanager
data02: stopping nodemanager
no proxyserver to stop
[hadoop@name01 sbin]$
[hadoop@name01 sbin]$ stop-dfs.sh
Stopping namenodes on [name01]
name01: stopping namenode
data01: stopping datanode
data02: stopping datanode
Stopping secondary namenodes [name01]
name01: stopping secondarynamenode
[hadoop@name01 sbin]$
PS:当然,也能够先启动MapReduce,再启动HDFS。说明HDFS 和MapReduce的进程之间是互相独立的,没有依赖关系。
3.4.4,第三种,分别启动各个进程:
[root@book0 bin]# jps
14821 Jps
[root@book0 bin]# hadoop-daemon.sh start namenode
[root@book0 bin]# hadoop-daemon.sh start datanode
[root@book0 bin]# hadoop-daemon.sh start secondarynamenode
[root@book0 bin]# hadoop-daemon.sh start jobtracker
[root@book0 bin]# hadoop-daemon.sh start tasktracker
[root@book0 bin]# jps
14855 NameNode
14946 DataNode
15043 SecondaryNameNode
15196 TaskTracker
15115 JobTracker
15303 Jps
运行的命令是“hadoop-daemon.sh start [进程名称]”,这样的启动方式适合于单独添加、删除节点的情况,在安装集群环境的时候会看到
3.5,第二种检查状态hadoop集群的状态
:用"hadoop dfsadmin -report"来查看hadoop集群的状态
[hadoop@name01 sbin]$ "hadoop dfsadmin -report"
-bash: hadoop dfsadmin -report: command not found
[hadoop@name01 sbin]$ hadoop dfsadmin -report
DEPRECATED: Use of this script to execute hdfs command is deprecated.
Instead use the hdfs command for it.
Configured Capacity: 58695090176 (54.66 GB)
Present Capacity: 48441020416 (45.11 GB)
DFS Remaining: 48440971264 (45.11 GB)
DFS Used: 49152 (48 KB)
DFS Used%: 0.00%
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
-------------------------------------------------
Datanodes available: 2 (2 total, 0 dead)
Live datanodes:
Name: 192.168.52.130:50010 (data02)
Hostname: data02
Decommission Status : Normal
Configured Capacity: 29347545088 (27.33 GB)
DFS Used: 24576 (24 KB)
Non DFS Used: 5127024640 (4.77 GB)
DFS Remaining: 24220495872 (22.56 GB)
DFS Used%: 0.00%
DFS Remaining%: 82.53%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Last contact: Fri Aug 22 00:04:58 PDT 2014
Name: 192.168.52.129:50010 (data01)
Hostname: data01
Decommission Status : Normal
Configured Capacity: 29347545088 (27.33 GB)
DFS Used: 24576 (24 KB)
Non DFS Used: 5127045120 (4.77 GB)
DFS Remaining: 24220475392 (22.56 GB)
DFS Used%: 0.00%
DFS Remaining%: 82.53%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Last contact: Fri Aug 22 00:04:58 PDT 2014
3.5,hadoop集群測试
3.5.1 运行简单的 MapReduce 计算
在$HADOOP_HOME 下有个jar 包,叫hadoop-example-2.2.0.jar,没有的话找其它版本号的測试jar包;
运行例如以下命令,命令使用方法例如以下:hadoop jar hadoop-example-1.1.2.jar,
[root@name01 ~]# find / -name hadoop-example-1.1.2.jar
[root@name01 ~]#
jar包不存在,须要找出用来測试的jar包,用模糊*搜索find / -name hadoop-*examp*.jar,例如以下所看到的:
[root@name01 ~]# find / -name hadoop-*examp*.jar
/home/hadoop/src/hadoop-2.3.0/share/hadoop/mapreduce/sources/hadoop-mapreduce-examples-2.3.0-sources.jar
/home/hadoop/src/hadoop-2.3.0/share/hadoop/mapreduce/sources/hadoop-mapreduce-examples-2.3.0-test-sources.jar
/home/hadoop/src/hadoop-2.3.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.3.0.jar
[root@name01 ~]#
hadoop jar /home/hadoop/src/hadoop-2.3.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.3.0.jar
[root@name01 ~]# su - hadoop
[hadoop@name01 ~]$ hadoop jar /home/hadoop/src/hadoop-2.3.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.3.0.jar
An example program must be given as the first argument.
Valid program names are:
aggregatewordcount: An Aggregate based map/reduce program that counts the words in the input files.
aggregatewordhist: An Aggregate based map/reduce program that computes the histogram of the words in the input files.
bbp: A map/reduce program that uses Bailey-Borwein-Plouffe to compute exact digits of Pi.
dbcount: An example job that count the pageview counts from a database.
distbbp: A map/reduce program that uses a BBP-type formula to compute exact bits of Pi.
grep: A map/reduce program that counts the matches of a regex in the input.
join: A job that effects a join over sorted, equally partitioned datasets
multifilewc: A job that counts words from several files.
pentomino: A map/reduce tile laying program to find solutions to pentomino problems.
pi: A map/reduce program that estimates Pi using a quasi-Monte Carlo method.
randomtextwriter: A map/reduce program that writes 10GB of random textual data per node.
randomwriter: A map/reduce program that writes 10GB of random data per node.
secondarysort: An example defining a secondary sort to the reduce.
sort: A map/reduce program that sorts the data written by the random writer.
sudoku: A sudoku solver.
teragen: Generate data for the terasort
terasort: Run the terasort
teravalidate: Checking results of terasort
wordcount: A map/reduce program that counts the words in the input files.
wordmean: A map/reduce program that counts the average length of the words in the input files.
wordmedian: A map/reduce program that counts the median length of the words in the input files.
wordstandarddeviation: A map/reduce program that counts the standard deviation of the length of the words in the input files.
[hadoop@name01 ~]$
验证能否够登录:
hadoop fs -ls hdfs://192.168.52.128:9000/
hadoop fs -mkdir hdfs://192.168.1.201:9000/testfolder
測试计算文本字符数目:
hadoop jar hadoop-examples-0.20.2-cdh3u5.jar wordcount /soft/BUILDING.txt /wordcountoutput
[hadoop@hadoop01 hadoop-2.3.0]$ hadoop jar hadoop-examples-0.20.2-cdh3u5.jar wordcount /soft/hadoop-2.3.0/release-2.3.0/BUILDING.txt /wordcountoutput
查看运行结果:
[hadoop@hadoop01 hadoop-2.2.0]$ hadoop fs -ls /wordcountoutput
Found 2 items
-rw-r--r-- 3 hadoop supergroup 0 2014-04-02 11:30 /wordcountoutput/_SUCCESS
-rw-r--r-- 3 hadoop supergroup 5733 2014-04-02 11:30 /wordcountoutput/part-r-00000
[hadoop@hadoop01 hadoop-2.2.0]$ hadoop fs -text /wordcountoutput/part-r-00000
"PLATFORM" 1
"Platform", 1
"platform". 1
$ 10
& 2
'-nsu' 1
'deploy' 1
'install', 1
參考网址:
http://blog.csdn.net/hguisu/article/details/7237395
http://blog.csdn.net/ab198604/article/details/8250461
http://developer.51cto.com/art/201209/357253.htm
http://dongxicheng.org/mapreduce-nextgen/nextgen-mapreduce-introduction/