站内搜索(主要技术点:Luncene.Net搜索引擎核心,Log4Net:日志,定时框架:quartz.Net,Jquery,Json,AJAX)
站内搜索(主要技术点:Luncene.Net搜索引擎核心,Log4Net:日志,定时框架:quartz.Net,Jquery,Json,AJAX)
1. 和用“select*from t where body like %计算机%”的区别:
(1) 效率。Like会造成全表扫描。
(2) Like无法实现“怎样学编程”“匹配”“怎样学习编程”.
盘古分词算法使用:
具体用法参考《PanguMannual.pdf》
打 开PanGu4Lucene\WebDemo\Bin,将Dictionaries添加到项目根路径(改名为Dict),添加对PanGu.dll(同目 录下不要有Pangu.xml,那个默认的配置文件的选项对于分词结果有很多无用信息)、PanGu.Lucene.Analyzer.dll的引用
把上节代码的Analyzer用PanGuAnalyzer代替
运行报错?通用技巧:把Dict目录下的文件“复制到输出目录”设定为“如果较新则复制”。
(*)Dictionaries下几个txt文件简介
词库的编辑,使用DictManage.exe,对单词编辑的时候要先查找。工作的项目中要将行业单词添加到词库中,比如餐饮搜索、租房搜索、视频搜索等。
出现Dict路径的问题,没有找到配置文件,默认就是Dict目录,设定Pangu.xml的复制到输出设置为“如果较新则复制”即可。或者词典目录就命名为Dict,不要配置文件。
1. 和用“select*from t where body like %计算机%”的区别:
(1) 效率。Like会造成全表扫描。
(2) Like无法实现“怎样学编程”“匹配”“怎样学习编程”.
为什么不用discuz的搜索,因为discuz的就是用like实现.
蜘蛛,spider 爬网站.
百度蜘蛛工作图 详情介绍:
http://baike.baidu.com/view/1847001.htm
蜘蛛,spider 爬网站.
百度蜘蛛工作图 详情介绍:
http://baike.baidu.com/view/1847001.htm
爬网站的过程:
1,发现网站.百度把CSDN当成关键网站,顺着已知的网站链接找到新的网站或者新的页面.
SEO(搜 索引擎优化)的第一个手段:建外链(外部链接).新网站吸引蜘蛛。对于非新网站,搜索引擎考虑一个“权重”,重点考察外链数量.权重越高搜索结果越靠 前,”权重”的一个重要因素就是“外链”数量,外链质量(外链网站的PR值,PageRank,决定一个网站的质量的值,PR值越高网站越重要,原创创建 时间等等),Alexa排名(全球网站排名).
1,发现网站.百度把CSDN当成关键网站,顺着已知的网站链接找到新的网站或者新的页面.
SEO(搜 索引擎优化)的第一个手段:建外链(外部链接).新网站吸引蜘蛛。对于非新网站,搜索引擎考虑一个“权重”,重点考察外链数量.权重越高搜索结果越靠 前,”权重”的一个重要因素就是“外链”数量,外链质量(外链网站的PR值,PageRank,决定一个网站的质量的值,PR值越高网站越重要,原创创建 时间等等),Alexa排名(全球网站排名).
SEO目的:让搜索引擎更多的收录网站的页面,让被收录页面的权重更靠前,让更多的人能过通过搜索引擎进入这个网站.
2,抓取网页.蜘蛛会定时抓取网站的内容,发现网站内容变化,发现新增内容就反映到搜索引擎中.
Robots.txt是公约,搜索引擎都建议遵守,相当于一个指路牌:想让那些搜索引擎搜索,想让那些页面搜索.
2,抓取网页.蜘蛛会定时抓取网站的内容,发现网站内容变化,发现新增内容就反映到搜索引擎中.
Robots.txt是公约,搜索引擎都建议遵守,相当于一个指路牌:想让那些搜索引擎搜索,想让那些页面搜索.
关于搜索:
有一定访问量得互联网站都有站内搜索功能,比如Verycd,优酷.豆瓣.cnblogs,mop,淘宝,大众点评网等.
为什么不用数据库全文检索?
数据库全文检索很傻瓜化,和普通SQL一样。数据全文检索灵活性不强,而且需要数据库开启全文检索功能才行,对于一些数据库管理权不在自己手里的应用(比如虚拟主机)来说不方便。
有一定访问量得互联网站都有站内搜索功能,比如Verycd,优酷.豆瓣.cnblogs,mop,淘宝,大众点评网等.
为什么不用数据库全文检索?
数据库全文检索很傻瓜化,和普通SQL一样。数据全文检索灵活性不强,而且需要数据库开启全文检索功能才行,对于一些数据库管理权不在自己手里的应用(比如虚拟主机)来说不方便。
为什么不用百度,google的站内搜索(site:www.xxx.com):受限于人,会被K;索引不及时,不全面,不精准;用户体验差.
Log4Net
Log4Net 是用来记录日志的,可以将程序运行过程中的信息输出到一些地方(文件,数据库,EventLog等),日志就是程序的黑匣子,可以通过日志查看系统的运行 过程,从而发现系统的问题.日志的作用:将运行过程的步骤,成功失败记录下来,将关键性的数据记录下载分析系统问题所在.Log4J.
Log4Net 是用来记录日志的,可以将程序运行过程中的信息输出到一些地方(文件,数据库,EventLog等),日志就是程序的黑匣子,可以通过日志查看系统的运行 过程,从而发现系统的问题.日志的作用:将运行过程的步骤,成功失败记录下来,将关键性的数据记录下载分析系统问题所在.Log4J.
配置Log4Net环境
新建一个WebApplication,添加一个“应用程序配置文件”(App.config)
添加对log4net.dll的引用
在Web.Config (或App.Config)添加配置,见备注
初始化:在程序最开始加入log4net.Config.XmlConfigurator.Configure();
在 要打印日志的地方LogManager.GetLogger(typeof(Program)).Debug("信息"); 。通过LogManager.GetLogger传递要记录的日志类类名获得这个类的ILog(这样在日志文件中就能看到这条日志是哪个类输出的了),然 后调用Debug方法输出消息。因为一个类内部不止一个地方要打印日志,所以一般把ILog声明为一个static字段。
输出错误信息用ILog.Error方法,第二个参数可以传递Exception对象。log.Error("***错误"+ex),log.Error("***错误",ex)
测试代码:见附件。
新建一个WebApplication,添加一个“应用程序配置文件”(App.config)
添加对log4net.dll的引用
在Web.Config (或App.Config)添加配置,见备注
初始化:在程序最开始加入log4net.Config.XmlConfigurator.Configure();
在 要打印日志的地方LogManager.GetLogger(typeof(Program)).Debug("信息"); 。通过LogManager.GetLogger传递要记录的日志类类名获得这个类的ILog(这样在日志文件中就能看到这条日志是哪个类输出的了),然 后调用Debug方法输出消息。因为一个类内部不止一个地方要打印日志,所以一般把ILog声明为一个static字段。
输出错误信息用ILog.Error方法,第二个参数可以传递Exception对象。log.Error("***错误"+ex),log.Error("***错误",ex)
测试代码:见附件。
在VS2010中的控制台项目引用Log4Net的时候要将项目的“目标框架”改为非“Client Profile”
1、Log4Net配置
1、Log4Net配置
1
<
configuration
>
2
<
configSections
>
3
<
section name
=
"
log4net
"
type
=
"
log4net.Config.Log4NetConfigurationSectionHandler, log4net
"
/>
4
</
configSections
>
5
<
log4net
>
6
<!--
Define some output appenders
-->
7
<
appender name
=
"
RollingLogFileAppender
"
type
=
"
log4net.Appender.RollingFileAppender
"
>
8
<
file value
=
"
test.txt
"
/>
9
<
appendToFile value
=
"
true
"
/>
10
<
maxSizeRollBackups value
=
"
10
"
/>
11
<
maximumFileSize value
=
"
1024KB
"
/>
12
<
rollingStyle value
=
"
Size
"
/>
13
<
staticLogFileName value
=
"
true
"
/>
14
<
layout type
=
"
log4net.Layout.PatternLayout
"
>
15
<
conversionPattern value
=
"
%date [%thread] %-5level %logger - %message%newline
"
/>
16
</
layout
>
17
</
appender
>
18
<
root
>
19
<
level value
=
"
DEBUG
"
/>
20
<
appender
-
ref
ref
=
"
RollingLogFileAppender
"
/>
21
</
root
>
22
</
log4net
>
23
</
configuration
>
建议用法:建立一静态字段存起来:
然后就可以哪儿里用到,就调用:
logger.Debug("信息");
1
private
static
ILog logger
=
LogManager.GetLogger(
typeof
(text_Default));
logger.Debug("信息");
Log4Net相关概念
Appender:可以将日志输出到不同的地方,不用的输出目标对应不同的.
Appender:RolingFileAppender(滚动文件),AdoNetAppender(数据库),SmtpAppender(邮件)等.
Level(级别)标识这条日志信息的重要级别.
None>Fatal>Error>Warn>Debug>info>all,设定一个Level,那么低于这个Level的日志是不会被写到Appender中的.
Appender:可以将日志输出到不同的地方,不用的输出目标对应不同的.
Appender:RolingFileAppender(滚动文件),AdoNetAppender(数据库),SmtpAppender(邮件)等.
Level(级别)标识这条日志信息的重要级别.
None>Fatal>Error>Warn>Debug>info>all,设定一个Level,那么低于这个Level的日志是不会被写到Appender中的.
Lucene.Net简介
Lucene.Net是由Java版本的Luncene移植过来的,所有的类,方法都几乎和Luncene一模一样,因此使用时参考Lucene即可.
Lucene.Net 只是一个全文检索开发包,不是以个成型的搜索引擎,它的功能就是:把数据扔给Lucene.Net,查询数据的时候从Lucene.Net查询数据,可以 看做是提供了全文检索功能的一个数据库.Lucene.net不管文本数据怎么来的.用户可以基于Lucene.net开发满足自己需求的搜索引 擎.Lucene.net只能对文本信息进行检索.如果不是文本信息,要转换为文本信息.比如要检索Excel文件,就要用NPOL把Excel读取成字 符串,然后把字符串扔给Lucene.Net.Lucene.Net会把扔给它的文本切词保存,加快检索速度.
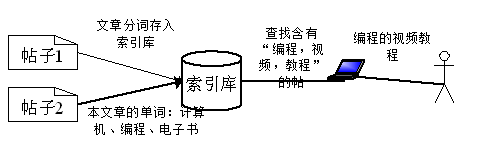
Lucene.Net是由Java版本的Luncene移植过来的,所有的类,方法都几乎和Luncene一模一样,因此使用时参考Lucene即可.
Lucene.Net 只是一个全文检索开发包,不是以个成型的搜索引擎,它的功能就是:把数据扔给Lucene.Net,查询数据的时候从Lucene.Net查询数据,可以 看做是提供了全文检索功能的一个数据库.Lucene.net不管文本数据怎么来的.用户可以基于Lucene.net开发满足自己需求的搜索引 擎.Lucene.net只能对文本信息进行检索.如果不是文本信息,要转换为文本信息.比如要检索Excel文件,就要用NPOL把Excel读取成字 符串,然后把字符串扔给Lucene.Net.Lucene.Net会把扔给它的文本切词保存,加快检索速度.
分词
分词是核心的算法,搜索引擎内部保存的就是一个个的词“(Word)”英文分词很简单,按照空格分隔就可以,中文则麻烦,把“北京,Hi欢迎你们大家”拆成“北京 Hi 欢迎 你们 大家”.
“the”,”, ”,”和”,“啊”,“的”等
参与分词的无意义的单词(noise word)。
Lucene.net中不同的分词算法就是不用的类,所有分词算法类都从Analyer类继承,不同的分词算法有不同的优缺点。
内置的StandardAnalyzer是将英文按照空格,标点符号等进行分词,将中文按照单个字进行分词,一个汉字算一个词.
演示:
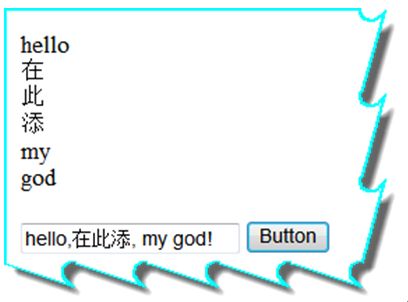
效果:
分词是核心的算法,搜索引擎内部保存的就是一个个的词“(Word)”英文分词很简单,按照空格分隔就可以,中文则麻烦,把“北京,Hi欢迎你们大家”拆成“北京 Hi 欢迎 你们 大家”.
“the”,”, ”,”和”,“啊”,“的”等
参与分词的无意义的单词(noise word)。
Lucene.net中不同的分词算法就是不用的类,所有分词算法类都从Analyer类继承,不同的分词算法有不同的优缺点。
内置的StandardAnalyzer是将英文按照空格,标点符号等进行分词,将中文按照单个字进行分词,一个汉字算一个词.
演示:
1
Analyzer analyzer
=
new
StandardAnalyzer();
2
TokenStream tokenStream
=
analyzer.TokenStream(
""
,
new
StringReader(TextBox1.Text));
3
Lucene.Net.Analysis.Token token
=
null
;
4
while
((token
=
tokenStream.Next())
!=
null
)
5
{
6
Console.WriteLine(token.TermText());
7
//
TextBox2.Text = token.TermText() + "<br/>";
8
Response.Write(token.TermText()
+
"
<br/>
"
);
二元分词算法,每两个汉字算一个单词,“欢迎你们大家”会分词为“欢迎 迎你 你们 们大 大家”,网上找到的一个二元分词算法CJKAnalyzer。面试的时候能说出不同的分词算法的差异。
基于一个词库进行分词,可以提高分词的成功率,有庖丁解牛,盘古分词等,效率低。
盘古分词算法使用:
具体用法参考《PanguMannual.pdf》
打 开PanGu4Lucene\WebDemo\Bin,将Dictionaries添加到项目根路径(改名为Dict),添加对PanGu.dll(同目 录下不要有Pangu.xml,那个默认的配置文件的选项对于分词结果有很多无用信息)、PanGu.Lucene.Analyzer.dll的引用
把上节代码的Analyzer用PanGuAnalyzer代替
运行报错?通用技巧:把Dict目录下的文件“复制到输出目录”设定为“如果较新则复制”。
(*)Dictionaries下几个txt文件简介
词库的编辑,使用DictManage.exe,对单词编辑的时候要先查找。工作的项目中要将行业单词添加到词库中,比如餐饮搜索、租房搜索、视频搜索等。
出现Dict路径的问题,没有找到配置文件,默认就是Dict目录,设定Pangu.xml的复制到输出设置为“如果较新则复制”即可。或者词典目录就命名为Dict,不要配置文件。