朴素贝页斯分类法
朴素贝页斯分类法
朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设的分类方法。对于搞机器学习的同学们来说,这是相对简单但效果较好的模型。
朴素贝叶斯方法的理论
设输入为n维特征向量X={x1,x2,...,xn},输出为类标记集合Y={c1,c2,...ck}。朴素贝叶斯法通过训练数据集学习联合概率分布P(X,Y),其中X是n维,Y是分类标记。有了模型P(X,Y),要预测一个特征向量的分类标记,则分别计算P(X,Y=c1),P(X,Y=c2),...P(X,Y=ck),选择取最大值的p(X,Y=cm),将cm作为X的分类标记。但对于模型P(X,Y)中的X是n维随机变量,若每一维特征取值最少有两个值,那么模型P(X,Y)参数量将是指数级的,这在特征维度较大的时候是不可行的。朴素贝叶斯法是引入条件独立性假设,由条件概率可得:
P(X=x,Y=ck)
=P(X(1)=x(1),X(2)=x(2),...X(n)=x(n)|Y=ck)*P(Y=ck)
(应用条件独立性假设)=P(X(1)=x(1)|Y=ck)*P(X(2)=x(2)|Y=ck)*...*P(X(n)=x(n)|Y=ck)*P(Y=ck)
即 =P(Y=ck)*∏i=1..nP(X(i)=x(i)|Y=ck)
条件独立性假设等于说用于分类的特征在类确定的情况下都是条件独立的。通过条件独立性假设,朴素贝叶斯法是模型变得简单,参数数量大大减少,但也牺牲一定的分类准确率。
朴素贝叶斯参数估计-极大似然估计
计算先验概率P(Y=ck)
P(Y=ck)=(∑i=1..nI(yi=ck))/N , k=1,2,...,K
其中I(yi=ck)为指示函数,当yi=ck时函数值等于1,否则为0。
计算条件概率P(X(j)=ajl|Y=ck)
P(X(j)=ajl|Y=ck)=(∑i=1..nI(xi(j)=ajl,yi=ck))/∑i=1..nI(yi=ck) ,j=1,2,,,n; l=1,2,Sj ;k=1,2,K
其中Sj是第j维特征的取值数。
由于计算条件概率可能会造成某个特征的计数为零,这样在预测分类的时候就会对有该特征的类计算值为0.为了避免这种情况,可采用拉普拉斯平滑处理。
预测分类
对给定的实例x=(x(1),x(2),...x(n))T,计算
P(Y=ck)*∏i=1..nP(X(i)=x(i)|Y=ck), k=1,2,...,K
然后根据上述K个结果,确定x的分类
y=argmax P(Y=ck)*∏i=1..n P(X(i)=x(i)|Y=ck)
例:
训练数据
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | |
| x(1) | 1 | 1 | 1 | 1 | 1 | 2 | 2 | 2 | 2 | 2 | 3 | 3 | 3 | 3 | 3 |
| x(2) | S | M | M | S | S | S | M | M | L | L | L | M | M | L | L |
| Y | -1 | -1 | 1 | 1 | -1 | -1 | -1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | -1 |
数据存储在文件中,每一行存储格式为<x(1) x(2) Y>,即特征1,特征2,分类属性以空格分隔。如下
1 S -1
1 M -1
1 M 1
1 S 1
1 S -1
2 S -1
2 M -1
2 M 1
2 L 1
2 L 1
3 L 1
3 M 1
3 M 1
3 L 1
3 L -1
代码如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
|
/********************************************************************/
/*
朴素贝叶斯法
*/
/************************************************************************/
#include<iostream>
#include<string>
#include<fstream>
#include<sstream>
#include<vector>
#include<map>
#include<set>
using
namespace
std;
class
naiveBayes{
public
:<br>
//载入数据并统计分量计数
void
loadData(){
ifstream fin(dataFile.c_str());
if
(!fin){
cout<<
"数据文件打开失败"
<<endl;
exit
(0);
}
while
(fin){
string line;
getline(fin,line);
if
(line.size()>1){
stringstream
sin
(line);
string s[2];
int
c;
sin
>>s[0]>>s[1]>>c;
//cout<<s1<<" "<<s2<<" "<<c<<endl;
dataSize++;
if
(ym.count(c)>0){
ym[c]++;
}
else
{
ym[c]=1;
}
for
(
int
i=0;i<2;i++){
if
(feam.count(s[i])>0){
if
(feam[s[i]].count(c)>0){
feam[s[i]][c]++;
}
else
{
feam[s[i]][c]=1;
}
}
else
{
map<
int
,
int
> mt;
mt[c]=1;
feam[s[i]]=mt;
}
}
}
}
}<br>
//显示map模型
void
dispModel(){
cout<<
"训练数据总数"
<<endl;
cout<<dataSize<<endl;
cout<<
"分类统计计数"
<<endl;
for
(map<
int
,
int
>::iterator mi=ym.begin();mi!=ym.end();mi++){
cout<<mi->first<<
" "
<<mi->second<<endl;
}
cout<<
"特征统计计数:"
<<endl;
for
(map<string, map<
int
,
int
> >::iterator mi=feam.begin();mi!=feam.end();mi++){
cout<<mi->first<<
": "
;
for
(map<
int
,
int
>::iterator ii=mi->second.begin();ii!=mi->second.end();ii++){
cout<<
"<"
<<ii->first<<
" "
<<ii->second<<
"> "
;
}
cout<<endl;
}
}<br>
//预测分类
void
predictive(){
string x1,x2;
cout<<
"请输入测试数据(包括两维特征,第一维取值<1,2,3>;第二维取值<S,M,L>)"
<<endl;
string a1[]={
"1"
,
"2"
,
"3"
};
string a2[]={
"M"
,
"S"
,
"L"
};
set<string> a1set(a1,a1+3);
set<string> a2set(a2,a2+3);
while
(cin>>x1>>x2){
if
(a1set.count(x1)>0&&a2set.count(x2)>0){
double
py1=(
double
(ym[-1])/dataSize)*(
double
(feam[x1][-1])/ym[-1])*(
double
(feam[x2][-1])/ym[-1]);
double
py2=(
double
(ym[1])/dataSize)*(
double
(feam[x1][1])/ym[1])*(
double
(feam[x2][1])/ym[1]);
cout<<
"y=-1的得分为"
<<py1<<endl;
cout<<
"y=1的得分为"
<<py2<<endl;
cout<<
"<"
<<x1<<
","
<<x2<<
">"
<<
"所属分类为:"
;
if
(py1>py2){
cout<<
"-1"
;
}
else
{
cout<<
"1"
;
}
cout<<endl;
cout<<endl;
cout<<
"继续测试(ctrl+Z结束)"
<<endl;
}
else
{
cout<<
"输入特征为:第一维取值<1,2,3>;第二维取值<S,M,L>,空格分隔。输入有误,请重新输入"
<<endl;
}
}
}
naiveBayes(string df=
"data.txt"
):dataFile(df),dataSize(0){
}
private
:
string dataFile;
int
dataSize;
//分类->计数
map<
int
,
int
> ym;
//分类->( 特征->计数 )
map<string, map<
int
,
int
> >feam;
};
int
main(){
naiveBayes nb;
nb.loadData();
nb.dispModel();
nb.predictive();
system
(
"pause"
);
return
0;
}
|
程序运行结果:
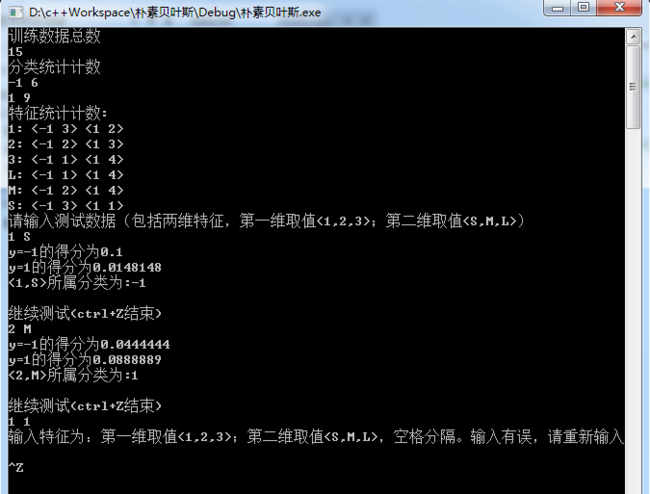
本例中,参数估计采用的是贝叶斯估计,有时间再把拉普拉斯平滑加上。
【问题帖】压缩图片大小至指定Kb以下
像PS,QQ影像等都有该功能,将图片大小压缩至指定kb以下。
我也来山寨一把,到目前为止,控制图片的大小,平时的解决方案通过分辨率和质量来控制的。
假定最后压缩的大小是100kb,那么在保证不大于100kb的前提下,图片质量尽可能高。图片质量越高,图片占用大小就越大。但是大小与质量的关系,没有一个固定的公式,如y= nx 之类的,而且我也试过将win7系统的图片收藏夹的图,每一张保存10次,从质量为10,递增到100,发现只能得出之前的结论,图片质量高,占用大小就大。
既然这样,那只能找到满足1ookb大小的最合适的质量参数了。这里使用了二分法来查找。
/// <summary> /// 压缩图片至n Kb以下 /// </summary> /// <param name="img">图片</param> /// <param name="format">图片格式</param> /// <param name="targetLen">压缩后大小</param> /// <param name="srcLen">原始大小</param> /// <returns>压缩后的图片内存流</returns> public static MemoryStream Zip(Image img, ImageFormat format, long targetLen, long srcLen = 0) { //设置允许大小偏差幅度 默认10kb const long nearlyLen = 10240; //返回内存流 如果参数中原图大小没有传递 则使用内存流读取 var ms = new MemoryStream(); if (0 == srcLen) { img.Save(ms, format); srcLen = ms.Length; } //单位 由Kb转为byte 若目标大小高于原图大小,则满足条件退出 targetLen *= 1024; if (targetLen >= srcLen) { ms.SetLength(0); ms.Position = 0; img.Save(ms, format); return ms; } //获取目标大小最低值 var exitLen = targetLen - nearlyLen; //初始化质量压缩参数 图像 内存流等 var quality = (long)Math.Floor(100.00 * targetLen / srcLen); var parms = new EncoderParameters(1); //获取编码器信息 ImageCodecInfo formatInfo = null; var encoders = ImageCodecInfo.GetImageEncoders(); foreach (ImageCodecInfo icf in encoders) { if (icf.FormatID == format.Guid) { formatInfo = icf; break; } } //使用二分法进行查找 最接近的质量参数 long startQuality = quality; long endQuality = 100; quality = (startQuality + endQuality) / 2; while (true) { //设置质量 parms.Param[0] = new EncoderParameter(System.Drawing.Imaging.Encoder.Quality, quality); //清空内存流 然后保存图片 ms.SetLength(0); ms.Position = 0; img.Save(ms, formatInfo, parms); //若压缩后大小低于目标大小,则满足条件退出 if (ms.Length >= exitLen && ms.Length <= targetLen) { break; } else if (startQuality >= endQuality) //区间相等无需再次计算 { break; } else if (ms.Length < exitLen) //压缩过小,起始质量右移 { startQuality = quality; } else //压缩过大 终止质量左移 { endQuality = quality; } //重新设置质量参数 如果计算出来的质量没有发生变化,则终止查找。这样是为了避免重复计算情况{start:16,end:18} 和 {start:16,endQuality:17} var newQuality = (startQuality + endQuality) / 2; if (newQuality == quality) { break; } quality = newQuality; Console.WriteLine("start:{0} end:{1} current:{2}", startQuality, endQuality, quality); } return ms; }
测试过程中发现,每张图的处理时间差不多为1s。完成需求,倒是没问题,但总觉得是不是应该有更合适的方案呢,如果有知道的朋友,欢迎提供知了一起探讨!