实实在在说多态(相同函数名 依据上下文 实现却不同)
实实在在说多态
(C++
篇
)
多态是C++中的一个重要的基础,可以这样说,不掌握多态就是C++的门外汉。然而长期以来,C++社群对于多态的内涵和外延一直争论不休。大有只见树木不见森林之势。多态到底是怎么回事呢?说实在的,我觉的多态这个名字起的不怎么好(或是译的不怎么好)。要是我给起名的话,我就给它定一个这样的名字--“调用’同名函数’却会因上下文不同会有不同的实现的一种机制”。这个名字长是长了点儿,可是比“多态”清楚多了。看这个长的定义,我们可以从中找出多态的三个重要的部分。一是“
相同函数名”,二是“依据上下文”,三是“实现却不同”。嘿,还是个顺口溜呢。我们且把它们叫做多态三要素吧。
多态带来两个明显的好处:一是不用记大量的函数名了,二是它会依据调用时的上下文来确定实现。确定实现的过程由C++本身完成另外还有一个不明显但却很重要的好处是:带来了面向对象的编程。
3. C++中实现多态的方式
C++中共有三种实现多态的方式。由“容易说明白”到“不容易说明白”排序分别为。第一种是函数重载;第二种是模板函数;第三种是虚函数。
函数重载是这样一种机制:允许有不同参数的函数有相同的名字。
具体一点讲就是:假如有如下三个函数:
void
test(
int
arg){}
//
函数1
void
test(
char
arg){}
//
函数2
void
test(
int
arg1,
int
arg2){}
//
函数3
如果在C中编译,将会得到一个名字冲突的错误而不能编译通过。在C++中这样做是合法的。可是当我们调用test的时候到底是会调用上面三个函数中的哪一个呢?这要依据你在调用时给的出的参数来决定。如下:
test(5);
//
调用函数1
test(
'c'
);
//
调用函数2
test(4,5);
//
调用函数3
C++是如何做到这一点的呢?原来聪明的C++编译器在编译的时候悄悄的在我们的函数名上根据函数的参数的不同做了一些不同的记号。具体说如下:
void
test(
int
arg)
//
被标记为 ‘test有一个int型参数’
void
test(
char
arg)
//
被标记为 ‘test有一个char型的参数’
void
test(
int
arg1,
int
arg2)
//
被标记为 ‘test第一个参数是int型,第二个参数为int型’
这样一来当我们进行对test的调用时,C++就可以根据调用时的参数来确定到底该用哪一个test函数了。噢,聪明的C++编译器。其实C++做标记做的比我上面所做的更聪明。我上面哪样的标记太长了。C++编译器用的标记要比我的短小的多。看看这个真正的C++的对这三个函数的标记:
?test@@YAXD@Z
?test@@YAXH@Z
?test@@YAXHH@Z
是不是短多了。但却不好看明白了。好在这是给计算机看的,人看不大明白是可以理解的。
还记得cout吧。我们用<<可以让它把任意类型的数据输出。比如可以象下面那样:
cout << 1;
//
输出int型
cout << 8.9;
//
输出double型
cout <<
'a'
;
//
输出char型
cout <<
"abc"
;
//
输出char数组型
cout << endl;
//
输出一个函数
cout之所以能够用一个函数名<<(<<是一个函数名)就能做到这些全是函数重载的功能。要是没有函数重载,我们也许会这样使用cout,如下:
cout int<< 1;
//
输出int型
cout double<< 8.9;
//
输出double型
cout char<<
'a'
;
//
输出char型
cout charArray<<
"abc"
;
//
输出char数组型
cout function(…)<< endl;
//
输出函数
为每一种要输出的类型起一个函数名,这岂不是很麻烦呀。
不过函数重载有一个美中不足之处就是不能为返回值不同的函数进行重载。那是因为人们常常不为函数调用指出返回值。并不是技术上不能通过返回值来进行重载。
所谓模板函数(也有人叫函数模板)是这样一个概念:函数的内容有了,但函数的参数类型却是待定的(注意:参数个数不是待定的)。比如说一个(准确的说是一类或一群)函数带有两个参数,它的功能是返回其中的大值。这样的函数用模板函数来实现是适合不过的了。如下。
template
<
typename
T>
T getMax(T arg1, T arg2)
{
return
arg1 > arg2 ? arg1:arg2;
//
代码段1
}
这就是基于模板的多态吗?不是。因为现在我们不论是调用getMax(1, 2)还是调用getMax(3.0, 5.0)都是走的上面的函数定义。它没有根据调用时的上下文不同而执行不同的实现。所以这充其量也就是用了一个模板函数,和多态不沾边。怎样才能和多态沾上边呢?用模板特化呀!象这样:
template
<>
char
* getMax(
char
* arg1,
char
* arg2)
{
return
(strcmp(arg1, arg2) > 0)?arg1:arg2;
//
代码段2
}
这样一来当我们调用getMax(“abc”, “efg”)的时候,就会执行代码段2,而不是代码段1。这样就是多态了。
更有意思的是如果我们再写这样一个函数:
char
getMax(
char
arg1,
char
arg2)
{
return
arg1>arg2?arg1:arg2;
//
代码段3
}
当我们调用getMax(‘a’, ‘b’)的时候,执行的会是代码段3,而不是代码段1或代码段2。C++允许对模板函数进行函数重载,就象这个模板函数是一个普通的函数一样。于是我们马上能想到写下面这样一个函数来做三个数中取大值的处理:
int
getMax(
int
arg1,
int
arg2,
int
arg3)
{
return
getMax(arg1, max(arg2, arg3) );
//
代码段4
}
同样我们还可以这样写:
template
<
typename
T>
T getMax(T arg1, T arg2, T arg3)
{
return
getMax(arg1, getMax(arg2, arg3) );
//
代码段5
}
现在看到结合了模板的多态的威力了吧。比只用函数重载厉害多了。
上面的两种多态在C++中有一个总称:静态多态。之所以叫它们静态多态是因为它们的多态是在编译期间就确定了。也就是说前面所说的函数1,2,3代码段1,2,3,4,5这些,在编译完成后,应该在什么样的上下文的调用中执行哪一些就确定了。比如:如果调用getMax(0.1, 0.2, 0.3)就会执行代码段5。如果调用test(5)就执行函数1。这些是在编译期间就能确定下来的。
静态多态还有一个特点,就是:“总和参数较劲儿”。
下面所要讲的一种多态就是必需是在程序的执行过程中才能确定要真正执行的函数。所以这种多态在C++中也被叫做动态多态。
首先来说一说虚函数,所谓虚函数是这样一个概念:基类中有这么一些函数,这些函数允许在派生类中其实现可以和基类的不一样。在C++中用关键字virtual来表示一个函数是虚函数。
C++中还有一个术语 “覆盖”与虚函数关系密切。所谓覆盖就是说,派生类中的一个函数的声明,与基类中某一个函数的声明一模一样,包括返回值,函数名,参数个数,参数类型,参数次序都不能有差异。
(注
1
)说覆盖和虚函数关系密切的原因有两个:一个原因是,只有覆盖基类的虚函数才是安全的。第二个原因是,要想实现基于虚函数的多态就必须在派生类中覆盖基类的虚函数。
接下来让我们说一说为什么要有虚函数,分析一下为什么派生类非要在某些情况下覆盖基类的虚函数。就以那个非常著名的图形绘制的例子来说吧。假设我们在为一个图形系统编程。我们可能有如下的一个类结构。
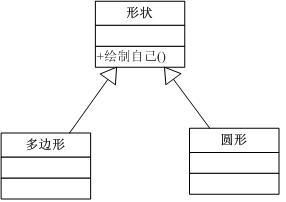
图7-1
形状对外公开一个函数来把自己绘制出来。这是合理的,形状就应该能绘制出来,对吧?由于继承的原因,多边形和圆形也有了绘制自己这个函数。
现在我们来讨论在这三个类中的绘制自己的函数都应该怎么实现。在形状中嘛,什么也不做就行了。在多边形中嘛,只要把它所有的顶点首尾相连起来就行了。在圆形中嘛,依据它的圆心和它的半径画一个360度的圆弧就行了。
可是现在的问题是:多边形和圆形的绘制自己的函数是从形状继承而来的,并不能做连接顶点和画圆弧的工作。
怎么办呢?覆盖它,覆盖形状中的绘制自己这个函数。于是我们在多边形和圆形中各做一个绘制自己的函数,覆盖形状中的绘制自己的函数。为了实现覆盖,我们需要把形状中的绘制自己这个函数用virtual修饰。而且形状中的绘制自己这个函数什么也不干,我们就把它做成一个纯虚函数。纯虚函数还有一个作用,就是让它所在的类成为抽象类。形状理应是一个抽象类,不是吗?于是我们很快写出这三个类的代码如下:
class
Shape
//
形状
{
public
:
virtual
void
DrawSelf()
//
绘制自己
{
cout <<
"
我是一个什么也绘不出的图形"
<< endl;
}
};
class
Polygo:
public
Shape
//
多边形
{
public
:
void
DrawSelf()
//
绘制自己
{
cout <<
"
连接各顶点"
<< endl;
}
};
class
Circ:
public
Shape
//
圆
{
public
:
void
DrawSelf()
//
绘制自己
{
cout <<
"
以圆心和半径为依据画弧"
<< endl;
}
};
下面,我们将以上面的这三个类为基础来说明动态多态。在进行更进一步的说明之前,我们先来说一个不得不说的两个概念:“子类型”和“向上转型”。
子类型很好理解,比如上面的多边形和圆形就是形状的子类型。关于子类型还有一个确切的定义为:
如果类型
X
扩充或实现了类型Y
,那么就说X
是Y
的子类型。
向上转型的意思是说把一个子类型转的对象换为父类型的对象。就好比把一个多边形转为一个形状。向上转型的意思就这么简单,但它的意义却很深远。向上转型中有三点需要我们特别注意。第一,向上转型是安全的。第二,向上转型可以自动完成。第三,向上转型的过程中会丢失子类型信息。这三点在整个动态多态中发挥着重要的作用。
假如我们有如下的一个函数:
void
OutputShape( Shape arg)
//
专门负责调用形状的绘制自己的函数
{
arg.DrawSelf();
}
那么现在我们可以这样使用
OutputShape这个函数:
Polygon shape1;
Circ shape2;
OutputShape(shape1);
OutputShape(shape2);
我们之所以可以这样使用OutputShape函数,正是由于向上转型是安全的(不会有任何的编译警告),是由于向上转弄是自动的(我们没有自己把shape1和shape2转为Shape类型再传给
OutputShape
函数)。可是上面这段程序运行后的输出结果是这样的:
我是一个什么也绘不出的图形
我是一个什么也绘不出的图形
明明是一个多边形和一个圆呀,应该是输出这下面这个样子才合理呀!
连接各顶点
以圆心和半径为依据画弧
造成前面的不合理的输出的罪魁祸首正是‘向上转型中的子类型信息丢失’。为了得到一个合理的输出,得想个办法来找回那些丢失的子类型信息。C++中用一种比较巧妙的办法来找回那些丢失的子类型信息。这个办法就是采用指针或引用。
对于一个对象来说无论有多少个指针指向它,这些个指针所指的都是同一个对象。(
即使你用一个void
的指针指向一个对象也是这样的,不是吗?)
同理对于引用也一样。
这究竟有多少深层次的意义呢?这里的深层的意义是这样的:子类型的信息本来就在它本身中存在,所以我们用一个基类的指针来指出它,这个子类型的信息也会被找到,同理引用也是一样的。C++
正是利用了指针的这一特性。来做到动态多态的。注2
现在让我们来改写OutputShape
函数为这样:
void
OutputShape( Shape& arg)
//
专门负责调用形状的绘制自己的函数
{
arg.DrawSelf();
}
现在我们的程序的输出为:
连接各顶点
以圆心和半径为依据画弧
这样的输出才是我们真正的想要的。我们实现的这种真正想要的输出就是动态多态的实质。
在我们上面的代码中,圆和多边形都是从形状公有继承而来的。要是我们把圆的继承改为私有或保护会怎么样呢?我们来试一试。哇,我们得到一个编译错误。这个错误的大致意思是说:“请不要用一个私有的方法”。怎么回事呢?
是这么回事。它的意思是说下面这样说不合理。
所有的形状都可以画出来,圆这种形状是不能画出来的。
这样合理吗?不合理。所以请在多态中使用公有继承吧。
多态的思想其实早在面向对象的编程出现之前就有了。比如C
语言中的+
运算符。这个运算符可以对两个int
型的变量求和,也可以对两个char
的变量求和,也可以对一个int
型一个char
型的两个变量求和。加法运算的这种特性就是典型的多态。所以说多态的本质是同样的用法在实现上却是不同的。
注1:严格地讲返回值可以不同,但这种不同是有限制的。详细情况请看有关协变的内容。
注2:C++会悄悄地在含有虚函数的类里面加一个指针。用这个指针来指向一个表格。这个表格会包含每一个虚函数的索引。用这个索引来找出相应的虚函数的入口地址。对于我们所举的形状的例子来说,C++会悄悄的做三个表,Shape一个,Polygon一个,Circ一个。它们分别记录一个DrawSelf函数的入口地址。在程序运行的过程中,C++会先通过类中的那个指针来找到这个表格。再从这个表格中查出DrawSelf的入口地址。然后现通过这个入口地址来调用正直的DrawSelf。正是由于这个查找的过程,是在运行时完成的。所以这样的多态才会被叫做动态多态(运行时多态)
Trackback: http://tb.blog.csdn.net/TrackBack.aspx?PostId=1526698