Lucene.Net 入门---介绍篇
阅读目录
-
lucene.net是什么
-
lucene.net特征
- lucene.net类说明
-
准备工作
-
Hello World
-
初次使用总结
lucene.net是什么
Apache Lucene.net是一个高性能(high-performance)的全能的全文检索(full-featured text search engine)的搜索引擎框架库,完全(entirely)使用C#开发。它是一种技术(technology),适合于(suitable for)几乎(nearly)任何一种需要全文检索(full-text search)的应用,特别是跨平台(cross-platform)的应用。
lucene.net特征
可扩展的高性能的索引能力(Scalable, High-Performance Indexing)
√ 超过20M/分钟的处理能力(Pentium M 1.5GHz)
√ 很少的RAM内存需求,只需要1MB heap
√ 增量索引(incremental indexing)的速度与批量索引(batch indexing)的速度一样快
√ 索引的大小粗略(roughly)为被索引的文本大小的20-30%
强大的精确的高效率的检索算法(Powerful, Accurate and Efficient Search Algorithms)
√ 分级检索(ranked searching)能力,最好的结果优先推出在前面
√ 很多强大的query种类:phrase queries, wildcard queries, proximity queries, range queries等
√ 支持域检索(fielded searching),如标题、作者、正文等
√ 支持日期范围检索(date-range searching)
√ 可以按任意域排序(sorting by any field)
√ 支持多个索引的检索(multiple-index searching)并合并结果集(merged results)
√ 允许更新和检索(update and searching)并发进行(simultaneous)
lucene.net类说明
- using Lucene.Net.Documents
-
提供一个简单的Document类,一个document只不过包括一系列的命名了(named)的Fields(域),它们的内容可以是文本(strings)也可以是一个java.io.Reader的实例。
-
- using Lucene.Net.Analysis
-
定义了一个抽象的Analyser API,用于将text文本从一个Reader转换成一个TokenStream,即包括一些Tokens的枚举容器(enumeration)。一个TokenStream的组成(compose)是通过在一个Tokenizer的输出的结果上再应用TokenFilters生成的。一些少量的Analysers实现已经提供,包括StopAnalyzer和基于语法(gramar-based)分析的StandardAnalyzer。
-
- using Lucene.Net.Index;
-
提供两个主要类,一个是IndexWriter用于创建索引并添加文档(document),另一个是IndexReader用于访问索引中的数据。
-
- using Lucene.Net.QueryParsers;
-
实现一个QueryParser。
-
- using Lucene.Net.Search;
-
提供数据结构(data structures)来呈现(represent)查询(queries):TermQuery用于单个的词(individual words),PhraseQuery用于短语,BooleanQuery用于通过boolean关系组合(combinations)在一起的queries。而抽象的Searcher用于转变queries为命中的结果(hits)。IndexSearcher实现了在一个单独(single)的IndexReader上检索。
-
- using Lucene.Net.Store;
-
定义了一个抽象的类用于存储呈现的数据(storing persistent data),即Directory(目录),一个收集器(collection)包含了一些命名了的文件(named files),它们通过一个IndexOutput来写入,以及一个IndexInput来读取。提供了两个实现,FSDirectory使用一个文件系统目录来存储文件,而另一个RAMDirectory则实现了将文件当作驻留内存的数据结构(memory-resident data structures)。
-
- using Lucene.Net.Util;
- 包含了一小部分有用(handy)的数据结构,如BitVector和PriorityQueue等
准备工作
1.去 http://lucenenet.apache.org/ 下载lunece.net 文件
2.在项目添加引用Lucene.Net.dll
Hello World
下面是一段简单的代码展示如何使用Lucene.net来进行索引和检索
class Program { static void Main(string[] args) { //索引 Directory direcotry = FSDirectory.GetDirectory("LuceneIndex"); Analyzer analyzer = new StandardAnalyzer(); IndexWriter writer = new IndexWriter(direcotry,analyzer); IndexReader red = IndexReader.Open(direcotry); int totDocs = red.MaxDoc(); red.Close(); //添加文档到索引 string text = string.Empty; Console.WriteLine("输入文本你想要添加到索引:"); Console.Write(">"); int txts = totDocs; int j = 0; while((text=Console.ReadLine())!=string.Empty) { AddTextToIndex(txts++,text,writer); j++; Console.Write(">"); } writer.Optimize(); writer.Flush(); writer.Close(); Console.WriteLine(j + " lines added, " + txts + " documents total"); //搜索 IndexSearcher searcher = new IndexSearcher(direcotry); QueryParser parser = new QueryParser("postBody", analyzer); Console.WriteLine("输入搜索的文本:"); Console.Write(">"); while ((text = Console.ReadLine()) != String.Empty) { Search(text, searcher, parser); Console.Write(">"); } //关闭资源 searcher.Close(); direcotry.Close(); } //搜索 private static void Search(string text,IndexSearcher searcher,QueryParser parser) { //条件 Query query = parser.Parse(text); //搜索 Hits hits = searcher.Search(query); //显示结果 Console.WriteLine("搜索 '" + text + "'"); int results = hits.Length(); Console.WriteLine("发现 {0} 结果", results); for (int i = 0; i < results; i++) { Document doc = hits.Doc(i); float score = hits.Score(i); Console.WriteLine("--结果 num {0}, 耗时 {1}", i + 1, score); Console.WriteLine("--ID: {0}", doc.Get("id")); Console.WriteLine("--Text found: {0}" + Environment.NewLine, doc.Get("postBody")); } } //添加文档到索引中 private static void AddTextToIndex(int txts,string text,IndexWriter writer) { Document doc = new Document(); doc.Add(new Field("id",text.ToString(),Field.Store.YES,Field.Index.UN_TOKENIZED)); doc.Add(new Field("postBody",text,Field.Store.YES,Field.Index.TOKENIZED)); writer.AddDocument(doc); } }
运行结果
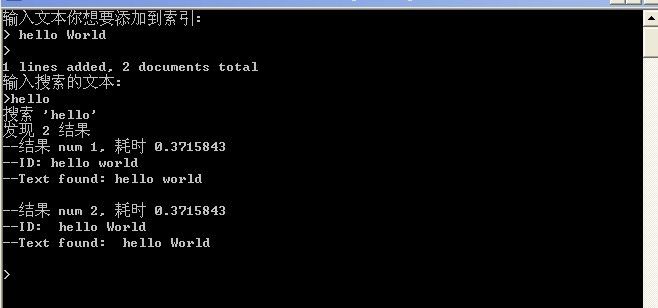
初次使用总结
列子hellowword
为了使用 lucene.net 一个应用程序需要做如下几件事。
1.通过添加一系列fileds来创建一批document对象。
2.创建一个indexWriter对象,并且调用它的addDocument()方法来添加进documents.
3.调用queryParser.parse()处理一段文本(string)来建造一个查询(querey)对象。
4.创建一个indexReader对象并将查询对象传入到他的search()方法中。