Linkedin 大数据生态系统
随着hadoop及其生态系统技术的应用,海量数据挖掘和机器学习算法在实际项目中的作用不断增加。Linkedin的大数据生态系统主要基于hadoop,hive,pig等,从而帮助数据科学家和机器学习研究人员从海量数据中抽取知识,构建新的数据产品特征。实际上,主要是为了解决最后一公里,提出一套丰富的开发生态系统。它包括从在线系统输出和输入数据,管理生产流程中的工作流。这种解决方案的主要特点是,对于研究人员来说,不用关心分布式系统的问题,它们被完全抽象出来。例如,部署数据回流到在线系统,数据科学家只需要一句简单的Pig命令就可以完成。
1相关工作
Twitter: 基于Pig搭建的机器学习平台
Facebook,hive数据分析,目前关于fb的生产环境的机器学习的资料还比较少
2Linkedin大数据生态系统
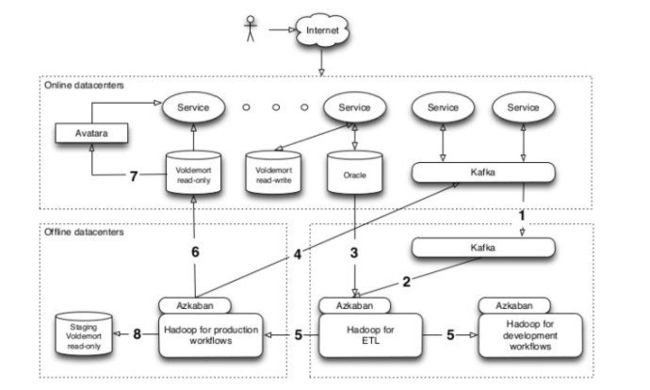
UGC数据从在线系统回流到离线系统,构建数据仓库。同时,对离线数据进行分析和挖掘,回流到在线系统。
3数据输入
数据加载到hadoop主要是两种形式:数据库和事件数据。数据库主要包括用户信息,公司信息,链接关系和其他网站数据。事件数据主要包括,实时活动数据流,譬如实时浏览,搜索等等。
3.1数据进化
数据来源较多,管理数据模式
在独立的模式注册表中,为每个主题topic维护一个数据模式
Linkedin采用apache avro作为序列化格式
3.2 hadoop加载
Kafka上的活动数据每10分钟通过hadoop map-only job回流到hadoop中。
Kafka中维护了超过100T压缩后的大约300个主题数据。每天处理15billion消息,峰值20万每秒。
3.3监控
参考K. Goodhope, J. Koshy, J. Kreps, N. Narkhede, R. Park, J. Rao, and V.Y. Ye, "Building LinkedIn's Real-time Activity Data Pipeline", ;presented at IEEE Data Eng. Bull., 2012, pp.33-45.
4工作流
Azkaban工作流平台
Linkedin维护三种Azkaban实例,每个和hadoop环境相对应。Hadoop ETL对于用户来说完全隐藏。在开发环境和生产环境中,研究人员首先将工作流部署到开发者实例中,测试算法的输出。一旦在开发环境经过测试,每个工作流进入生产环境进行测试。通过测试后,工作流就可以被部署到生产环境实例中。数据集和工具在各个环境中进行同步处理。
5数据输出
工作流的结果数据需要回流到其他存储系统,用于服务线上应用。
根据实际应用,主要有三种主要机制:
(1) kv存储
(2) 流数据
(3) OLAP在线分析平台
5.1key-value
Linkedin主要使用voldemort进行kv数据存储
Kv存储是linkedin主要数据输出系统,即将模型算法结果数据存储到voldemort中。
5.2 流数据
Kafka处理实时数据
Sessions = foreach pageviews generate sessionize(*);
Store sessions into ‘kafka://kafka-url’ using
Streams(‘topic=pageviews’);
5.3 OLAP
多维数据处理,离线计算数据,主要是ETL构建物化视图,服务前台产品。
产品:avatara
6 应用
6.1 key-value
People you may know
协同过滤
技能推荐
相关搜索
6.2流数据
新闻实时更新
Email实时处理
关系强度计算
6.3OLAP
Who has viewed my profile
Who has viewed this job
参考: http://www.slideshare.net/s_shah/the-big-data-ecosystem-at-linkedin-23512853