学习笔记:The Log(我所读过的最好的一篇分布式技术文章)
前言
这是一篇学习笔记。学习的材料来自Jay Kreps的一篇讲Log的博文。原文很长,但是我坚持看完了,收获颇多,也深深为Jay哥的技术能力、架构能力和对于分布式系统的理解之深刻所折服。同时也因为某些理解和Jay哥观点吻合而略沾沾自喜。
Jay Kreps是前Linkedin的Principal Staff Engineer,现任Confluent公司的联合创始人和CEO,Kafka和Samza的主要作者。
所谓笔记,就是看了文章,提笔就记,因为Jay哥本身本章组织的太好,而其本身的科学素养及哲学素养也很高,所以私以为出彩的东西就不省略了。
一、资料来源
The Log: What every software engineer should know about real-time data’s unifying abstraction
二、笔记
2.1 Log的价值
1) Log是如下系统的核心:
- 分布式图数据库
- 分布式搜索引擎
- Hadoop
- 第一代和第二代K-V数据库
2) Log可能跟计算机的历史一样长,并且是分布式数据系统和实时计算系统的核心。
3) Log的名字很多:
- Commit log
- Transaction log
- Write-ahead log
4) 不理解Log,你就不可能充分理解
- 数据库
- NoSQL存储
- K-V存储
- 复制
- Paxos算法
- Hadoop
- Version Control
- 或者,任何软件系统
2.2 什么是Log?
2.2.1 概述

- 记录会附加到log的尾部。
- 从左到右读取记录。
- 每个entry都有唯一且有序的log entry 序号。
记录的顺序定义了这样的一个概念:时间。
因为越靠左的记录越早。
Entry的序号可以当作一种时间戳,将记录的顺序当作时间这一概念看起来很奇怪,但是很快你就会发现,这样做:可以方便地将“时间”与任一特定的物理时钟解耦。
Log和常见的文件、表(table)没有那么大的差别。
- 文件是一组字节
- 表是一组记录
- Log可以说是某种将记录按时间排序的文件或者表
这样说,可能你会觉得log如此简单,还有讨论的必要吗?
其实,log的核心意义在于:
Log记录了何时发生了什么(they record what happened and when.)。
而这一条,通常是分布式系统最最最核心的东西。
注意,这里有必要澄清几个概念:
- 本篇所讨论的Log和程序员通常接触的应用日志(application logs)不同
- 应用日志通常是一种非结构化的,记录错误信息、调试信息,用于追踪应用的运行的,给人看的日志,比如通过log4j或者 syslog来写入本地文件的日志。
- 而本篇所讨论的log是通过编程方式访问的,不是给人看的,比如“journal”、“data logs”。
- 应用日志是本篇所讨论的log的一种特化。
2.2.2 数据库中的Logs
Log的起源不得而知,就像发明二分查找的人,难以意识到这种发明是一种发明。
Log的出现和IBM的System R 一样早。
在数据库中,需要在数据库崩溃时,保持多种多样的数据结构和索引保持同步。
为保证原子性和持久性,数据库需要在对数据结构和索引进行修改提交之前,记录其要修改的内容。
所以log记录了何时发生了什么,而每一张表和索引本身,都是这种历史信息的映射。
因为log是立即持久化的,所以当crash发生时,其成为恢复其它持久化结构的可靠来源。
Log从保证ACID特性的一种实现,发展成了一种数据库之间数据复制的手段。
很显然,数据库中发生的一系列的数据变更,成为数据库之间 保持同步最需要的信息。
Oracle、MySQL、PostgreSQL,都包含了log传输协议,将log的一部分发送到用于保持复制的从数据库(Slave)。
Oracle的XStreams和GoldenState,将log当作一种通用的数据订阅机制,以提供给非Oracle的数据库订阅数据。
MySQL和PostgreSQL也提供了类似的组件,这些组件是数据系统架构的核心。
面向机器的Log,不仅仅可被用在数据库中,也可以用在:
- 消息系统
- 数据流(data flow)
- 实时计算
2.2.3 分布式系统中的logs
Log解决了两个很重要的分布式数据系统中的问题:
1) 有序的数据变化
2) 数据分布式化
所谓的状态机复制原理(State Machine Replication Principle):
如果两个确定的处理过程,从相同的状态开始,按照相同的顺序,接收相同的输入,那么它们将会产生相同的输出,并以 相同的状态结束。
所谓确定的(deterministic),是指处理过程是时间无关的,其处理结果亦不受额外输入的影响。
可以通过非确定的例子来理解:
- 多线程的执行顺序不同导致不同的结果
- 执行getTimeOfDay()方法
- 其它的不能重复的处理过程
所谓状态,可以是机器上的任意数据,无论在处理结束后,是在机器的内存中还是磁盘上。
相同的输入按照相同的顺序,产生相同的结果,这一点值得引起你的注意,这也是为什么log会如此重要,这是一个直觉性的概念:如果你将同一个log输入两个确定性的程序,它们将产生相同的输出。
在分布式系统的构建中,意识到这一点,可以使得:
让所有的机器做同样的事,规约为:
构建分布式的、满足一致性的log系统,以为所有处理系统提供输入。
Log系统的作用,就是将所有的输入流之上的不确定性驱散,确保所有的处理相同输入的复制节点保持同步。
这种方法的最妙之处在于,你可以将索引日志的时间戳,作为所有复制节点的时钟来对待:
通过将复制节点所处理过的log中最大的时间戳,作为复制节点的唯一ID,这样,时间戳结合log,就可以唯一地表达此节点的整个状态。
应用这种方法的方式也很多:
- 在log中记录对一个服务的请求
- 在回复请求的前后,记录服务状态的变化
- 或者,服务所执行的一系列转换命令,等等。
理论上来讲,我们可以记录一系列的机器指令,或者所调用方法的名称及参数,只要数据处理进程的行为相同,这些进程就可以保证跨节点的一致性。
常玩儿数据库的人,会将逻辑日志和物理日志区分对待:
- 物理日志:记录了所有的行内容的变化。
- 逻辑日志:不是记录内容的变化,而是Insert , update , delete等导致行内容变化的SQL语句。
对分布式系统,通常有两种方式来处理复制和数据处理:
1) State machine model(active – active)
2) Primary-back model (active – passive)
如下图所示:
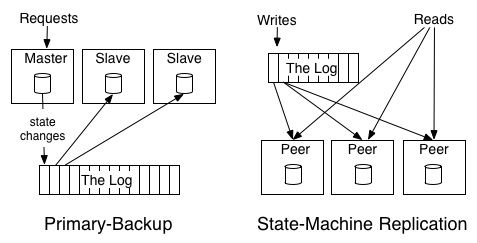
为了理解上述两种方式的不同,来看个简单的例子:
现在,集群需要提供一个简单的服务,来做加法、乘法等算术运算。初始,维护一个数字,比如0。
- Active – active :在日志记录这样的一些操作,如“+1”、“*2”等,这样,每个复制节点需要执行这些操作,以保证最后的数据状态是一致的。
- Active – passive:一个单独的master节点,执行“+1”、“*2”等操作,并且在日志中记录操作的结果,如“1”、“3”、“6”等。
上面的例子也揭示了,为什么顺序是复制节点之间保持一致性的关键因素,如果打乱了这些操作的顺序,就会得到不同的运算结果。
分布式log,可以当做某些一致性算法的数据结构:
- Paxos
- ZAB
- RAFT
- Viewstamped Replication
一条log,表征了一系列的关于下一个值是什么的决定。
2.2.4 Changelog
从数据库的角度来看,一组记录数据变化的changelog和表,是对偶和互通的。
1) 依据记录了数据变化的log,可以重构某一状态的表(也可以是非关系型存储系统中有key的记录)
2) 相反,表如果发生了变化,可以将变化计入log。
这正是你想要的准实时复制的秘籍所在!
这一点和版本控制所做的事情极为类似:管理分布式的、并发的、对状态进行的修改。
版本控制工具,维护了反映修改的补丁,这其实就是log,你和一个被签出(checked out)的分支快照进行交互,这份快照就相当于数据库中的表。你会发现,版本控制与分布式系统中,复制都是基于log的:当你更新版本时,你只是拉取了反映了版本变化的补丁,并应用于当前的分支快照。
2.3 数据集成(Data integration)
2.3.1 数据集成的含义
所谓数据集成,就是将一个组织中的所有服务和系统的数据,变得可用。
实际上,对数据进行有效利用,很符合马斯洛的层次需求理论。
金字塔的最底层,是收集数据,将其整合进应用系统中(无论是实时计算引擎,还是文本文件,还是python脚本)。
而这些数据,需要经过转换,保持一个统一、规范、整洁的格式,以易于被读取和处理。
当上面的要求被满足后,就可以开始考虑多种多样的数据处理方式,比如map – reduce 或者实时查询系统。
很显然,如果没有一个可靠的、完备的数据流,Hadoop就仅仅是一个昂贵的、难以整合的加热器(集群很费电么?)。
相反,如果能保证数据流可靠、可用且完备,就可以考虑更高级的玩法、更好的数据模型和一致的、更易被理解的语义。
接着,注意力就可以转移到可视化、报表、算法和预测上来(挖啊机啊深度啊)。
2.3.2 数据集成的两个复杂性
事件
事件数据,记录了事件是怎么发生的,而不仅仅是发生了什么,这一类log通常被当做应用日志,因为一般是由应用系统写入的。但这一点,其实混淆了log的功能。
Google的财富,其实,是由一个建立在(用户)点击流和好恶印象(体验)之上的相关性pipeline产生的,而点击流和印象,就是事件。
各种各样的专业数据系统的爆发
这些系统存在的原因:
- 联机分析(OLAP)
- 搜索
- 简单的在线存储
- 批处理
- 图谱分析
- 等等(如spark)
显然,要将数据整合进这样的系统中,对于数据集成来讲,极为困难。
2.3.3 基于日志结构的数据流
每种逻辑意义上的数据源,都可以依据log进行建模。
数据源可以是记录了事件(点击和PV)的应用程序,可以是接受更改的数据库表。
每个订阅者,都尽可能快地从这些数据源产生的log中获取新的记录,应用于本地的存储系统,并且提升其在log中的读取偏移(offset)。订阅者可以是任何数据系统,比如缓存、Hadoop、另一个站点的数据库,或者搜索引擎。
Log,实际上提供了一种逻辑时钟,针对数据变化,可以测量不同的订阅者所处的状态,因为这些订阅者在log中的读取偏移不同且相互独立,这种偏移就像一个时间意义上的“时刻”一样。
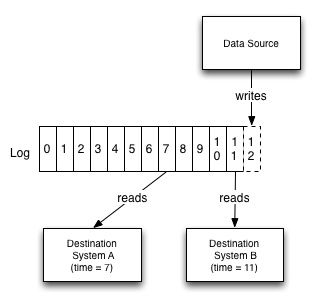
考虑这样一个例子,一个数据库,和一些缓存服务器:
Log提供了这样一种能力,可以使得所有的缓存服务器得到同步,并推出它们所处的“时刻”。
假设我们写入了一个编号为X的log,要从某个缓存服务器读取数据,为了不读到老数据,只需要保证:在缓存服务器将数据(同步)复制到X这个位置前,我们不从这个缓存中读取任何东西即可。
此外,log还提供了作为缓冲区的能力,以支持生产者和消费者的行为以异步的方式进行。
最关键的一个支持异步的原因,是订阅系统可能会发生崩溃、因维护而下线,接着恢复上线,而在这种情况下,每个订阅者都以自己的步调消费数据。
一个批处理系统,比如Hadoop,或者一个数据仓库,是以小时或天为单位消费数据,而一个实时系统,通常在秒级消费数据。
而数据源或者log,对消费数据的订阅者一无所知,所以,需要在pipeline中做到无缝的添加订阅者和移除订阅者。
更重要的是,订阅者,只需要知道log,而不需要对其所消费的数据的来源有任何了解,无论这个数据源是RDBMS、Hadoop,还是一个最新流行的K-V数据库,等等。
之所以讨论log,而不是消息系统,是因为不同的消息系统所保证的特性不同,并且用消息系统这个词,难以全面和精确表达某种语义,因为消息系统,更重要的在于重定向消息。
但是,可以将log理解为这样一种消息系统,其提供了持久性保证及强有序的语义,在通讯系统中,这称作原子广播。
2.4 在Linkedin
Linkedin目前的主要系统包括(注:2013年):
- Search
- Social Graph
- Voldemort (K-V存储)
- Espresso (文档存储)
- Recommendation engine
- OLAP query engine
- Hadoop
- Terradata
- Ingraphs (监控图谱及metrics服务)
每个系统,都在其专业的领域提供专门的高级功能。
(这一段太长太长了,Jay兄十分能侃啊,所以挑重点的来记吧!)
1) 之所以引入数据流这个概念,是因为要在oracle数据库的表之上,建立一个抽象的缓存层,为搜索引擎的索引构建和社交图谱更新,提供拓展能力。
2) 为了更好的处理linkedin的一些推荐算法,开始搭Hadoop集群,但团队在此块的经验尚浅,所以走了很多弯路。
3) 开始时,简单粗暴地认为只要将数据从oracle数据仓库中拉出来,丢进hadoop就可以了。结果发现:第一,将数据从oracle数据仓库快速导出是个噩梦;第二,也是更糟糕的一点,数据仓库中某些数据的处理不对,导致了hadoop的批处理任务不能按预期输出结果,且通过hadoop批处理执行任务,通常不可逆,特别是在出了报表之后。
4) 最后,团队抛弃了从数据仓库中出数据的方式,直接以数据库和logs为数据源。接着,造出了一个轮子:K-V 存储(Voldemort)。
5) 即使是数据拷贝这样不高大上的活儿,也占据了团队大量的时间去处理,更糟的是,一旦数据处理的pipeline中有个点出错,hadoop立马变得废柴,因为再牛逼的算法跑在错误的数据上,只有一个后果,就是产生更多的错误数据。
6) 即使团队构建的东西抽象层次很高,针对每种数据源还是需要特定的配置,而这也是很多错误和失败的根源。
7) 一大批程序员想跟进,每个程序员都有一大批的想法,集成这个系统,添加这个功能,整合这个特色,或者想要自定义的数据源。
8) Jay哥开始意识到:
第一, 虽然他们构建的pipelines还很糙,但是却极其有价值。即使是解决了数据在新的系统(如hadoop)中可用的问题,也解锁了一大批可能性。以前难做的计算开始变为可能。新的产品和分析,仅需要解锁其它系统中的数据,并且进行整合,就可以容易地做出来。
第二, 很明显,可靠地数据装载需要更坚实的支撑,如果能够捕获所有的结构,就可以让hadoop数据装载完全自动化,不需要加入新的数据源或人工修改数据的模式。数据会神奇地出现在HDFS中,而新的数据源加入后,Hive的表会用合适的列自动化地、自适应地生成。
第三,数据覆盖度远远不足。因为要处理很多新的数据源,很难。
9) 为了解决新数据源加入后的数据装载问题,团队开始了这样的尝试:

很快,他们发现这样搞行不通,因为发布和订阅、生产和消费,数据流通常还是双向的,这成了一个O(n^2)的问题。
所以,他们需要的是这样的模型:

需要将每个消费者从数据源隔离,理想的情况下,这些消费者只和一个data repository进行交互,而这个repository可以提供它们访问任意数据的能力。
10)消息系统 + log = Kafka,kafka横空出世。
2.5 Log和ETL、数据仓库的关系
2.5.1 数据仓库
1) 一个装有干净的、结构化的、集成的数据repository,用于分析。
2) 虽然想法很美好,但是获取数据的方式有点过时了:周期性地从数据库获取数据,将其转换为某种可读性更佳的格式。
3) 之前的数据仓库问题在于:将干净的数据和数据仓库高度耦合。
数据仓库,应该是一组查询功能的集合,这些功能服务于报表、搜索、ad hot 分析,包含了计数(counting)、聚合(aggregation)、过滤(filtering)等操作,所以更应该是一个批处理系统。
但是将干净的数据和这样的一种批处理系统高度耦合在一起,意味着这些数据不能被实时系统消费,比如搜索引擎的索引构建、实时计算和实时监控系统,等等。
2.5.2 ETL
Jay哥认为,ETL无非做两件事:
1) 对数据进行抽取和清洗,将数据从特定的系统中解锁
2) 重构数据,使其能通过数据仓库进行查询。比如将数据类型变为适配某个关系型数据库的类型,将模式转换为星型或者雪花模式,或者将其分解为某种面向列的存储格式。
但是,将这两件事耦合在一起,问题很大,因为集成后的、干净的数据,本应能被其它实时系统、索引构建系统、低延时的处理系统消费。
数据仓库团队,负责收集和清洗数据,但是,这些数据的生产者往往因为不明确数据仓库团队的数据处理需求,导致输出很难被抽取和清洗的数据。
同时,因为核心业务团队对和公司的其它团队保持步调一致这件事儿不敏感,所以真正能处理的数据覆盖度很低,数据流很脆弱,很难快速应对变化。
所以,更好的方式是:
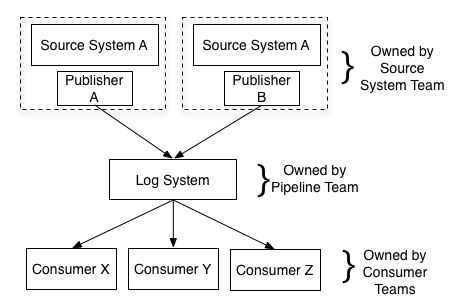
如果想在一个干净的数据集上做点搜索、实时监控趋势图、实时报警的事儿,以原有的数据仓库或者hadoop集群来作为基础设施,都是不合适的。更糟的是,ETL所构建的针对数据仓库的数据加载系统,对其它(实时)系统点儿用没有。
最好的模型,就是在数据发布者发布数据之前,就已经完成了数据的清洗过程,因为只有发布者最清楚它们的数据是什么样的。而所有在这个阶段所做的操作,都应该满足无损和可逆。
所有丰富语义、或添加值的实时转换,都应在原始的log发布后处理(post-processing),包括为事件数据建立会话,或者添加某些感兴趣的字段。原始的log依旧可被单独使用,但是此类实时应用也派生了新的参数化的log。
最后,只有对应于具体的目标系统的数据聚合操作,应作为数据装载的一部分,比如转换为星型或雪花型模式,以在数据仓库中进行分析和出报表。因为这个阶段,就像传统的ETL所做的那样,因为有了非常干净和规范的数据流,(有了log后)现在变得非常简单。
2.6 Log文件和事件
以log为核心的架构,还有个额外的好处,就是易于实现无耦合的、事件驱动的系统。
传统的 捕获用户活动和系统变化的方式,是将此类信息写入文本日志,然后抽取到数据仓库或者hadoop集群中进行聚合和处理,这个问题和前面所述的数据仓库和ETL问题类似:数据与数据仓库的高度耦合。
在Linkedin,其基于kafka构建了事件数据处理系统。为各种各样的action定义了成百上千种事件类型,从PV、用户对于广告的赶脚(ad impressions)、搜索,到服务的调用和应用的异常,等等。
为了体会上述事件驱动系统的好处,看一个简单的关于事件的例子:
在工作机会页面上,提供一个机会。这个页面应该只负责如何展示机会,而不应该过多地包含其它逻辑。但是,你会发现,在一个具有相当规模的网站中,做这件事,很容易就会让越来越多的与展示机会无关的逻辑牵扯进来。
比如,我们希望集成以下系统功能:
1) 我们需要将数据发送到hadoop和数据仓库做离线处理。
2) 我们需要统计页面浏览次数,以确保某些浏览不是为了抓取网页内容什么的。
3) 我们需要聚合对此页面的浏览信息,在机会发布者的分析页面上呈现。
4) 我们需要记录某用户对此页面的浏览记录,以确保我们对此用户提供了有价值的、体验良好的任何适宜此用户的工作机会,而不是对此用户一遍又一遍地重复展示某个机会(想想老婆不在家才能玩的游戏吧,那红绿蓝闪烁的特效,配合那劲爆的DJ风舞曲,或者那摇摆聚焦的事业峰和齐X小短裙的girls,然后点进去才发现是标题党的ad吧!)。
5) 我们的推荐系统需要记录对此页面的浏览记录,以正确地追踪此工作机会的流行度。
很快,仅仅展示机会的页面逻辑,就会变得复杂。当我们在移动端也增加了此机会的展示时,不得不把逻辑也迁移过去,这又加剧了复杂程度。还没完,纠结的东西是,负责处理此页面的工程师,需要有其它系统的知识,以确保上述的那些功能能正确的集成在一起。
这只是个极其简单的例子,在实践中,情况只会更加复杂。
事件驱动可以让这件事变得简单。
负责呈现机会的页面,只需要呈现机会并记录一些和呈现相关的因素,比如工作机会的相关属性,谁浏览了这个页面,以及其它的有用的与呈现相关的信息。页面不需要保持对其它系统的知识和了解,比如推荐系统、安全系统、机会发布者的分析系统,还有数据仓库,所有的这些系统只需要作为订阅者,订阅这个事件,然后独立地进行它们各自的处理即可,而呈现机会的页面不需要因为新的订阅者或消费者的加入而做出修改。
2.7 构建可扩展的log
分离发布者和订阅者不新鲜,但是要保证多个订阅者能够实时处理消息,并且同时保证扩展能力,对于log系统来说,是一件比较困难的事。
如果log的构建不具备快速、低开销和可扩展能力,那么建立在此log系统之上的一切美好都免谈。
很多人可能认为log系统在分布式系统中是个很慢、重型开销的活儿,并且仅用来处理一些类似于ZooKeeper更适合处理的元数据等信息。
但是Linkedin现在(注:2013年),在kafka中每天处理600亿条不同的消息写入(如果算数据中心的镜像的话,那就是几千亿条写入)。
Jay哥他们怎么做到的呢?
1) 对log进行分割(partitioning the log)
2) 通过批量读写优化吞吐量
3) 避免不必要的数据拷贝
通过将log切为多个partition来提供扩展能力:

1) 每个partition都是有序的log,但是partitions之间没有全局的顺序。
2) 将消息写入哪个partition完全由写入者控制,通过依照某种类型的key(如user_id)进行分割。
3) 分割使得log的附加操作,可以不用在分片(sharding)之间进行协调就进行,同时,保证系统的吞吐量和kafka集群的规模呈线性关系。
4) 虽然没有提供全局顺序(实际上消费者或者订阅者成千上万,讨论它们的全局顺序一般没有啥价值),但是kafka提供了这样一种保证:发送者按照什么顺序将消息发给某个partition,从这个partition递交出去的消息就是什么顺序(什么顺序进,什么顺序出)。
5) 每个partition都按照配置好的数目进行复制,如果一个leader节点挂了,其它的节点会成为新的leader。
6) 一条log,同文件系统一样,线性的读写模式可被优化,将小的读写log可以组成更大的、高吞吐量的操作。Kafka在这件事上做的很猛。批处理用在了各种场景之下,比如客户端将数据发送到服务端、将数据写入磁盘、服务器之间的数据复制、将数据传送给消费者,以及确认提交数据等场景。
7) 最后,kafka在内存log、磁盘log、网络中发送的log上,采用了很简单的二进制格式,以利于利用各种优化技术,比如零拷贝数据传输技术(zero-copy data transfer)。
诸多的优化技术,汇聚起来,可以让你即使在内存爆满的情形下,也能按照磁盘或网络能提供的最大能力进行数据读写。
2.8 Logs和实时处理
你以为Jay哥提供了这么个美丽的方法把数据复制来复制去就完了?
你!错!了!
Log是流的另一种说法,logs是流处理的核心。
2.8.1 什么是流处理
Jay哥认为:
1)流处理是连续数据处理的基础设施。
2)流处理的计算模型,就如同MapReduce或其它分布式处理框架一样,只是需要保证低延迟。
3)批处理式的收集数据模式,导致了批处理式的数据处理模式。
4)连续的收集数据模式,导致了连续的数据处理模式。
5)Jay哥讲了个美国人口普查的方式来解释批处理。
在linkedin,无论是活动数据还是数据库的变化,都是连续的。
批处理按天处理数据,和连续计算将窗口设为一天雷同。
所以,流处理是这样一种过程:
6)在处理数据时,带了一个时间的概念,不需要对数据保持一个静态的快照,所以可以在用户自定义的频率之下,输出结果,而不必等数据集到达某种“结束”的状态。
7)从这个意义上讲,流处理是批处理的一种泛化,并且考虑到实时数据的流行程度,这是一种极其重要的泛化。
8)许多商业公司无法建立流处理引擎,往往因为无法建立流数据收集引擎。
9)流处理跨越了实时响应式服务和离线批处理的基础设施之间的鸿沟。
10)Log系统,解决了很多流处理模式中的关键问题,其中最大的一个问题就是如何在实时的多个订阅者模式下,提供可用数据的问题(流数据收集)。
2.9 数据流图谱
流处理中最有趣的地方在于,其拓展了什么是数据源(feeds)这一概念。
无论是原始数据的logs、feeds,还是事件、一行一行的数据记录,都来自应用程序的活动。
但是,流处理还可以让我们处理来自其它feeds的数据,这些数据和原始数据,在消费者看来,并无二致,而这些派生的feeds可以包含任意程度的复杂性。
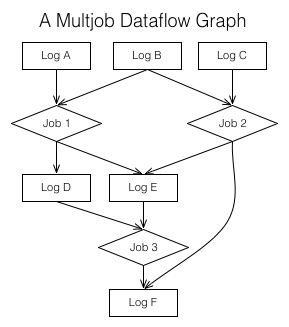
一个流处理任务,应该是这样的:从logs读取数据,将输出写入logs或者其它系统。
作为输入和输出的logs,连通这些处理本身,和其它的处理过程,构成了一个图。
事实上,以log为核心的系统,允许你将公司或机构中的数据捕获、转换以及数据流,看作是一系列的logs及在其上进行写入的处理过程的结合。
一个流处理程序,其实不必很高大上:可以是一个处理过程或者一组处理过程,但是,为了便于管理处理所用的代码,可以提供一些额外的基础设施和支持。
引入logs有两个目的:
1) 保证了数据集可以支持多个订阅者模式,及有序。
2) 可以作为应用的缓冲区。这点很重要,在非同步的数据处理进程中,如果上游的生产者出数据的速度更快,消费者的速度跟不上,这种情况下,要么使处理进程阻塞,要么引入缓冲区,要么丢弃数据。
丢弃数据似乎不是个好的选择,而阻塞处理进程,会使得所有的数据流的处理图谱中的处理进程卡住。而log,是一种很大,特大,非常大的缓冲区,它允许处理进程的重启,使得某个进程失败后,不影响流处理图谱中的其它进程。这对于一个庞大的机构去扩展数据流是非常关键的,因为不同的团队有不同的处理任务,显然不能因为某个任务发生错误,整个流处理进程都被卡住。
Storm和Samza就是这样的流处理引擎,并且都能用kafka或其它类似的系统作为它们的log系统。
(注:Jay哥相当猛,前有kafka,后有samza。)
2.10 有状态的实时处理
很多流处理引擎是无状态的、一次一记录的形式,但很多用例都需要在流处理的某个大小的时间窗口内进行复杂的counts , aggregations和joins操作。
比如,点击流中,join用户信息。
那么,这种用例,就需要状态的支持。在处理数据的地方,需要维护某个数据的状态。
问题在于,如何在处理者可能挂掉的情况下保持正确的状态?
将状态维护在内存中可能是最简单的,但抵不住crash。
如果仅在某个时间窗口内维护状态,当挂掉或者失败发生,那么处理可以直接回退到窗口的起点来重放,但是,如果这个窗口有1小时那么长,这可能行不通。
还有个简单的办法,就是把状态存在某个远程的存储系统或数据库中,但是这会损失数据的局部性并产生很多的网络间数据往返(network round-trip)。
回忆下,上文中曾提到的数据库中的表和log的对偶性。
一个流处理组件,可以使用本地的存储或索引来维护状态:
- Bdb
- Leveldb
- Lucene
- Fastbit
通过记录关于本地索引的changelog,用于在crash后恢复状态。这种机制,其实也揭示了一种一般化的,可以存储为任意索引类型的,与输入流同时被分割(co-partitioned)的状态。
当处理进程崩溃,其可以从changelog中恢复索引,log充当了将本地状态转化为某种基于时间备份的增量记录的角色。
这种机制还提供了一种很优雅的能力:处理过程本身的状态也可以作为log被记录下来,显然,其它的处理过程可以订阅这个状态。
结合数据库中的log技术,针对数据集成这一场景,往往可以做出很强大的事:
将log从数据库中抽取出来,并在各种各样的流处理系统中进行索引,那么,与不同的事件流进行join就成为可能。
2.11 Log 合并
显然,用log记录全时全量的状态变更信息,不太可能。
Kafka使用了log合并或者log垃圾回收技术:
1) 对于事件数据,kafka只保留一个时间窗口(可在时间上配置为几天,或者按空间来配置)
2) 对于keyed update,kafka采用压缩技术。此类log,可以用来在另外的系统中通过重放技术来重建源系统的状态。
如果保持全时全量的logs,随着时间增长,数据将会变得越来越大,重放的过程也会越来越长。
Kafka不是简单地丢弃老的日志信息,而是采用合并的方式,丢弃废弃的记录,比如,某个消息的主键最近被更新了。
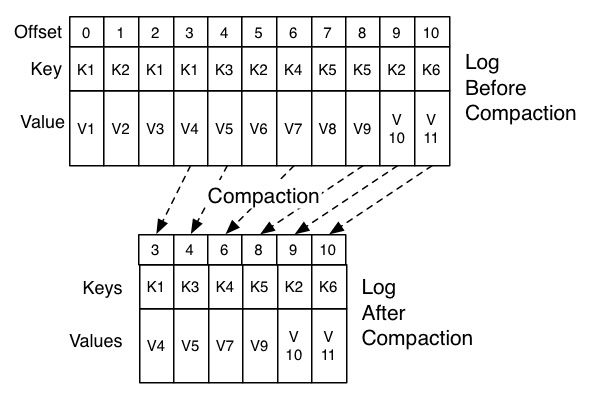
2.12 系统构建
2.12.1 分布式系统
Log,在分布式数据库的数据流系统和数据集成中所扮演的角色是一致的:
- 抽象数据流
- 保持数据一致性
- 提供数据恢复能力
你可以将整个机构中的应用系统和数据流,看作是一个单独的分布式数据库。
将面向查询的独立系统,比如Redis , SOLR , Hive tables 等等,看作是一种特别的、数据之上的索引。
将Storm、Samza等流处理系统,看做一种精心设计过的触发器或者物化视图机制。
各式各样的数据系统,爆发性的出现,其实,这种复杂性早已存在。
在关系型数据库的辉煌时期(heyday),某个公司或者机构光关系型数据库就有很多种。
显然,不可能将所有的东西都丢进一个Hadoop集群中,期望其解决所有的问题。所以,如何构建一个好的系统,可能会像下面这样:
构建一个分布式系统,每个组件都是一些很小的集群,每个集群不一定能完整提供安全性、性能隔离、或者良好的扩展性,但是,每个问题都能得到(专业地)解决。
Jay哥觉得,之所以各式各样的系统爆发性地出现,就是因为要构建一个强大的分布式系统十分困难。而如果将用例限制到一些简单的,比如查询这样的场景下,每个系统都有足够的能力去解决问题,但是要把这些系统整合起来,很难。
Jay哥觉得在未来构建系统这事儿有三种可能:
1) 保持现状。这种情况下,数据集成依然是最头大的问题,所以一个外部的log系统就很重要(kafka!)
2) 出现一个强大的(如同辉煌时期的关系型数据库)能解决所有问题的系统,这似乎有点不可能发生。
3) 新生代的系统大部分都开源,这揭示了第三种可能:数据基础设施可被离散为一组服务、以及面向应用的系统API,各类服务各司其事,每个都不完整,却能专业滴解决专门的问题,其实通过现存的java技术栈就能看出端倪:
- ZooKeeper:解决分布式系统的同步、协作问题(也可能受益于更高抽象层次的组件如helix、curator).
- Mesos、YARN:解决虚拟化和资源管理问题。
- 嵌入式的组件Lucene、LevelDB:解决索引问题。
- Netty、Jetty及更高抽象层次的Finagle、rest.li解决远程通讯问题。
- Avro、Protocol Buffers、Thrift及umpteen zlin:解决序列化问题。
- Kafka、bookeeper:提供backing log能力。
从某种角度来看,构建这样的分布式系统,就像某个版本的乐高积木一样。这显然跟更关心API的终端用户没有太大关系,但是这揭示了构建一个强大系统并保持简单性的一条道路:
显然,如果构建一个分布式系统的时间从几年降到几周,那么构建一个独立的庞大系统的复杂性就会消失,而这种情况的出现,一定是因为出现了更可靠、更灵活的“积木”。
2.12.2 Log在系统构建中的地位
如果一个系统,有了外部log系统的支持,那么每个独立的系统就可以通过共享log来降低其自身的复杂性,Jay哥认为log的作用是:
1) 处理数据一致性问题。无论是立即一致性还是最终一致性,都可以通过序列化对于节点的并发操作来达到。
2) 在节点间提供数据复制。
3) 提供“提交”的语义。比如,在你认为你的写操作不会丢失的情况下进行操作确认。
4) 提供外部系统可订阅的数据源(feeds)。
5) 当节点因失败而丢失数据时,提供恢复的能力,或者重新构建新的复制节点。
6) 处理节点间的负载均衡。
以上,大概是一个完整的分布式系统中应提供的大部分功能了(Jay哥确实爱Log!),剩下的就是客户端的API和诸如一些构建索引的事了,比如全文索引需要获取所有的partitions,而针对主键的查询,只需要在某个partition中获取数据。
(那把剩下的事情也交代下吧,Jay哥威武!)
系统可被分为两个逻辑组件(这强大的理解和功力):
1) Log层
2) 服务层
Log层,以序列化的、有序的方式捕获状态的变化,而服务层,则存储外部查询需要的索引,比如一个K-V存储可能需要B-tree、sstable索引,而一个搜索服务需要倒排索引。
写操作既可以直接入log层,也可以通过服务层做代理。写入log会产生一个逻辑上的时间戳(log的索引),比如一个数字ID,如果系统partition化了,那么,服务层和log层会拥有相同的partitions(但其各自的机器数可能不同)。
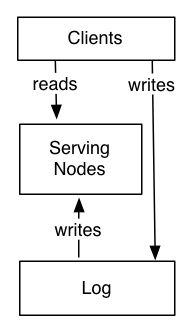
服务层订阅到log层,并且以最快的速度、按log存储的顺序追log,将数据和状态变化同步进自己的本地索引中。
客户端将会得到read-your-write的语义:
通过对任一一个节点,在查询时携带其写入时的时间戳,服务层的节点收到此查询,通过和其本地索引比较时间戳,如果必要,为了防止返回过期的老数据,推迟请求的执行,直到此服务节点的索引同步跟上了时间戳。
服务层的节点,也许需要、也许不需要知道leader的概念。在很多简单的用例中,服务层可不构建leader节点,因为log就是事实的来源。
还有一个问题,如何处理节点失败后的恢复问题。可以这样做,在log中保留一个固定大小的时间窗口,同时对数据维护快照。也可以让log保留数据的全量备份并使用log合并技术完成log自身的垃圾回收。这种方法,将服务层的众多复杂性移至log层,因为服务层是系统相关(system-specific)的,而log层确可以通用。
基于log系统,可以提供一组完备的、供开发使用的、可作为其它系统的ETL数据源、并供其它系统订阅的API。
Full Stack !:

显然,一个以log为核心的分布式系统,其本身立即成为了可对其它系统提供数据装载支持及数据流处理的角色。同样的,一个流处理系统,也可以同时消费多个数据流,并通过对这些数据流进行索引然后输出的另一个系统,来对外提供服务。
基于log层和服务层来构建系统,使得查询相关的因素与系统的可用性、一致性等因素解耦。
也许很多人认为在log中维护数据的单独备份,特别是做全量数据拷贝太浪费、太奢侈,但事实并非如此:
1) linkedin(注:2013年)的kafka生产集群维护了每数据中心75TB的数据,而应用集群需要的存储空间和存储条件(SSD+更多的内存)比kafka集群要高。
2) 全文搜索的索引,最好全部装入内存,而logs因为都是线性读写,所以可以利用廉价的大容量磁盘。
3) 因为kafka集群实际运作在多个订阅者的模式之下,多个系统消费数据,所以log集群的开销被摊还了。
4) 所有以上原因,导致基于外部log系统(kafka或者类似系统)的开销变得非常小。
2.13 结语
Jay哥在最后,不仅厚道地留下了很多学术、工程上的有价值的论文和参考链接,还很谦逊地留下了这句话:
If you made it this far you know most of what I know about logs.
终。
相关文章
- 刘星:HBase性能深度分析
- Spark:一个高效的分布式计算系统
- 你真的很熟分布式和事务吗?
- 分布式消息系统:Kafka
- 一致性hash和solr千万级数据分布式搜索引擎中的应用
- syslog:类Unix系统常用的log服务
- 王健:最佳日志实践
- 分布式系统阅读清单
- 写给开发者:记录日志的10个建议
- .NET高级工程师面试题之SQL篇
学习笔记:The Log(我所读过的最好的一篇分布式技术文章),首发于 博客 - 伯乐在线。