Juicer – 一个Javascript模板引擎的实现和优化

让我们从一段代码说起,假设有一段这样的JSON数据:
var json={
name:"流火",
blog:"ued.taobao.com"
};
我们需要根据这段JSON生成这样的HTML代码:
流火 (blog: ued.taobao.com)
传统的Javascript代码一定是这个样子:
var html; html=''+json.name+' (blog: '+json.blog+')';
不言而喻,这样的代码混杂了html结构和代码逻辑,而且代码不具可读性,不便于后期维护,于是便有了这样一个函数:
function sub(str,data) {
return str
.replace(/{(.*?)}/igm,function($,$1) {
return data[$1]?data[$1]:$;
});
}
有了这个函数,我们拼接字符串的工作就可以简化为:
var tpl='{name} (blog: {blog})';
var html=sub(tpl,json);

看到这里,不用我多说,我想通过这个例子直观的展现出前端模板引擎的好处所在,这么做能够完全剥离html和代码逻辑,便于多人协作和后期的代码维护。当然,当我们的业务逻辑需要对数据源进行循环遍历,if判断等的时候,这个简明的函数很显然并不能满足我们的需求,于是便有了如今这市面上众多的模板引擎,诸如Mustache, jQuery tmpl, Kissy template, ejs, doT, nTenjin, etc.
“如无必要,勿增实体。” 这是著名的奥卡姆剃须刀法则,简单的说就是避免重复造轮子。那么就会有童鞋质疑,既然已然有这么多现成的东西可用,为什么还要重新打造一个呢?
我个人认为一个完善的模板引擎应该兼顾这几点:
- 语法简明
- 执行效率高
- 安全性
- 错误处理机制
- 多语言通用性

而市面上现有的模板引擎没有做到兼顾以上几点,比如Mustache支持多种语言,通用性不错,不过性能稍差,而且语法不支持高级特性,例如遍历的时候无法做if判断,也无法获得index索引值,jQuery tmpl依赖jQuery,缺乏可移植性,Kissy template虽然依赖Kissy, 不过性能和语法都值得推荐,doT/nTenjin 性能和灵活性都很不错,但是语法需要用原生的js来写,写好的模板代码可读性稍差。
鱼和熊掌不可兼得,语法的处理,安全性的输出过滤和错误处理机制的引入在一定程度上都会或多或少降低模板引擎的性能,因此就需要我们权衡。Juicer 在实现上首先将性能看做第一个重要的指标,毕竟性能好坏直接影响用户的感知,同时兼顾了安全性和错误处理机制(即便这样会导致性能的略微下降)。
首先来看下jsperf上同几个主流模板引擎的性能对比。

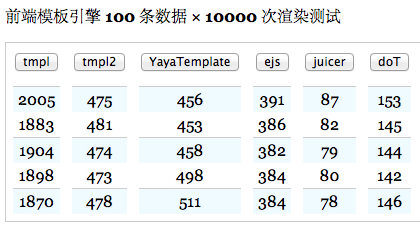
可以看到,性能上比传统模板引擎均有提升,下边的介绍主要从语法、安全性和错误处理,以及如何使用这几个方面介绍下Juicer.
a. 语法
- 循环 {@each}…{@/each}
- 判断 {@if}…{@else if}…{@else}…{@/if}
- 变量(支持函数)${varname|function}
- 注释 {# comment here}
详细的语法请参考 Juicer Docs.
b. 安全性
安全性,简单地说就是对输出数据在输出前进行一次转义过滤,避免XSS这样的脚本注入攻击,简单扫下盲,举个XSS的例子。
var json={
output:'alert("XSS");'
};
如果JSON数据是第三方接口返回或者含有用户输入(像BBS、评价)的内容,我们如果赤裸裸的将output写到页面上就会执行恶意的js代码,所以Juicer默认是对数据输出做了安全转义的,当然如果不想被转义,可以使用$${varname}。
juicer.to_html('${output}',json);
//输出:<script>alert("XSS");</script>
juicer.to_html('$${output}',json);
//输出:<script>alert("XSS");</script>
c. 错误处理
如果没有错误处理,当模板引擎编译(Compile)或者渲染(Render)出错时候就会引起后续js代码停止执行,可想而知,如果因为一个逗号或者JSON数据的偶发错误导致整个页面挂掉,是我们不能接受的。但是Juicer在遇到这些错误的时候不会影响后续代码的执行,只会在控制台打出一句警告(Warn)告知开发者模板解析出现错误。
juicer.to_html('${varname,,,,,,,}',json);
alert('hello, juicer!');
执行上边的代码就会看到控制台打出的“Juicer Compile Exception: Unexpected token ,”,但是不会因为错误导致后续的alert被阻塞掉。
实现原理

Juicer对一个模板的编译和渲染的过程主要有以下几个步骤:
- 1、对模板代码进行语法分析
- 2、分析后生成原生的Javascript代码字符串
- 3、将生成的代码转为可重用的Function (Compiled Template)
var json={
list:[
{name:"benben"},
{name:"liuhuo"}
]
};
var tpl='{@each data.list as value,key}$${value.name}{@/each}';
var compiled_tpl=juicer.compile(tpl,{errorhandling:false});
我们通过compiled_tpl.render.toString()看下编译后的代码:
function anonymous(data) {
var data = data || {};
var out = '';
out += '';
for (var i0 = 0, l = data.list.length; i0 < l; i0++) {
var value = data.list[i0];
var key = i0;
out += '';
out += ((value.name));
out += '';
}
out += '';
return out;
}
是不是已经明白了Juicer的原理?这个编译后的函数就会每次帮我们完成从数据到html代码的拼装操作。
这里有几点优化的地方值得分享下:
- 1、using += instead of array.push
- 2、avoid using with {}
- 3、cache the compiled template (function)
这几点优化在大数据量循环渲染时候性能提升显著,不过正因为放弃了with{}语句,所以JSON数据外层必须指定“data.”前缀,如果你觉得这点性能的提升不重要,也可以在options中指定loose:true(松散模式),这样就可以省去data. 前缀。
最后介绍下Options配置项,左侧为参数默认值。
{
cache:true/false,
loose:false/true,
errorhandling:true/false
}
cache默认为true,即同一个模板编译后是否被juicer缓存,也就是说如果缓存开启的情况下,同一个模板第一次编译后,为了缩短耗时提升性能,后续不会再次执行编译的操作而是直接从缓存中去取编译好的模板函数。
Juicer的API. Juicer有两种使用方法,一种是通过
juicer.to_html(tpl,data,options);
直接根据提供的数据将模板转为html代码,另一种是通过compile方法先将模板编译好,在需要的时候再对模板进行数据的Render操作:
var compiled_tpl=juicer.compile(tpl,options); compiled_tpl.render(data);
最后附上Juicer的项目地址,上边有详细的文档和Demo代码。
http://juicer.name