MapReduce 编程之 倒排索引
本文调试环境: ubuntu 10.04 , hadoop-1.0.2
hadoop装的是伪分布模式,就是只有一个节点,集namenode, datanode, jobtracker, tasktracker...于一体。
本文实现了简单的倒排索引,单词,文档路径,词频,重要的解释都会在代码注视中。
第一步,启动hadoop, 开发环境主要是用eclipse. 在本地文件系统中新建三个文本文档作为数据源:并且上传到HDFS文件系统上:
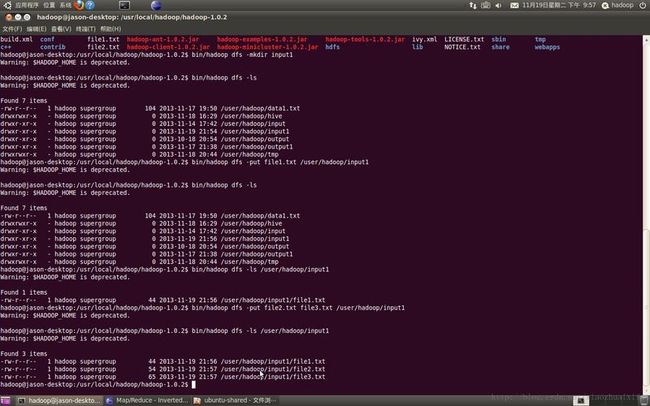
如上图,在HDFS上新建了一个输入路径文件夹:input1,此路径将会作为后面程序的输入参数;
如果你打开了eclipse,你同样会在DFSLocation中看到此目录文件信息:
好了,然后开始写代码吧,代码的详细解释,你可以在刘鹏老师的hadoop实战中第三章找到:
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class InvertedIndex {
// Map过程
public static class InvertedIndexMapper extends
Mapper<Object, Text, Text, Text>{
private Text keyInfo = new Text();
private Text valueInfo = new Text();
private FileSplit split;
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException{
//获得<key,value>对所属的FileSplit对象
split = (FileSplit)context.getInputSplit();
StringTokenizer itr = new StringTokenizer(value.toString());
while(itr.hasMoreTokens()){
//key值由单词和文档URL组成,如:word:filename.txt
//至于为什么采用这样的格式,因为可以利用MapRedeuce框架自带的Map端排序
keyInfo.set(itr.nextToken() + ":" + split.getPath().toString());
//初始词频为1
valueInfo.set("1");
context.write(keyInfo, valueInfo);
}
}
}
//Combine 过程
public static class InvertedIndexCombiner extends
Reducer<Text, Text, Text, Text>{
private Text info= new Text();
public void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException{
int sum = 0;
for(Text value : values){
sum += Integer.parseInt(value.toString());
}
int splitIndex = key.toString().indexOf(":");
//现在value由如下格式组成:文档URL:词频,为保证在Shuffle过程的key 值相同,这样才能
//哈希到同一个reducer.
info.set(key.toString().substring(splitIndex + 1) + ":" + sum);
//key由单词组成
key.set(key.toString().substring(0, splitIndex));
context.write(key, info);
}
}
//Reducer过程
public static class InvertedIndexReducer extends
Reducer<Text, Text, Text, Text>{
private Text result = new Text();
// 输入端键值 value格式是一个列表,进入Reducer的key是经过排序的,因为相同的key则产生了一个列表{values}
public void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException{
String fileList = new String();
for(Text value : values){
fileList += value.toString() + ";";
}
//合并每个单词的所有values
result.set(fileList);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception{
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if(otherArgs.length != 2){
System.err.println("args is wrong!");
System.exit(2);
}
Job job = new Job(conf, "InvertedIndex");
job.setJarByClass(InvertedIndex.class);
job.setMapperClass(InvertedIndexMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setCombinerClass(InvertedIndexCombiner.class);
job.setReducerClass(InvertedIndexReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//程序添加的两个参数指定输入输出文件路径
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
注意新建的不是JAVA工程哦,是M-P工程,还要注意输入目录路径在程序运行之前不应该存在,此处我指定为output1
在运行配置里,输入两个参数,即输入路径和输出路径。
运行时你将会看到如此信息:

运行结束后你将在你的HDFS文件系统上的output1 文件夹下看到程序的执行结果:

这就是正确的结果了,统计出每个单词出现的文档路径及词频数。一个简单的M-P编程是列就是这样子了的。
笔者刚开始学习hadoop,欢迎交流,如有错误,恳请指出。
作者:xiaozhuaixifu 发表于2013-11-19 22:23:12 原文链接
阅读:102 评论:0 查看评论