simhash算法实现--查找文件相似度
一、Simhash简介
SimHash是用来网页去重最常用的hash方法,速度很快。Google采用这种算法来解决万亿级别的网页去重任务。
SimHash算法的主要思想是降维。将高维的特征向量映射成一个低维的特征向量,通过两个向量的Hamming Distance来确定文章是否重复或者高度近似。
在simhash的发明人Charikar的论文中并没有给出具体的simhash算法和证明,“量子图灵”得出的证明simhash是由随机超平面hash算法演变而来的。
参考文献:《Detecting Near-Duplicates for Web Crawling 》
二、Simhash和传统hash的区别
传统hash函数解决的是生成唯一值,比如md5,hashmap等。Md5是用于生成唯一签名串,只要稍微多加一个字符,md5的两个数字看起来相差甚远。而我们的目的是解决文本相似度计算,要比较的是两个文章是否相似。而simhash对相似文本的哈希映射结果也相似。
传统的hash算法只负责将原始内容尽量均匀随机地映射为一个签名值,原理上相当于伪随机数产生算法。产生的两个签名,如果相等,说明原始内容在一定概率下是相等的;如果不相等,除了说明原始内容不相等外,不再提供任何信息,因为即使原始内容只相差一个字节,所产生的签名也很可能差别极大。从这个意义上来说,要设计一个hash算法,对相似的内容产生的签名也相近,是更为艰难的任务,因为它的签名值除了提供原始内容是否相等的信息外,还能额外提供不相等的原始内容的差异程度的信息。
而Google的simhash算法产生的签名,可以用来比较原始内容的相似度。
三、简单应用场景
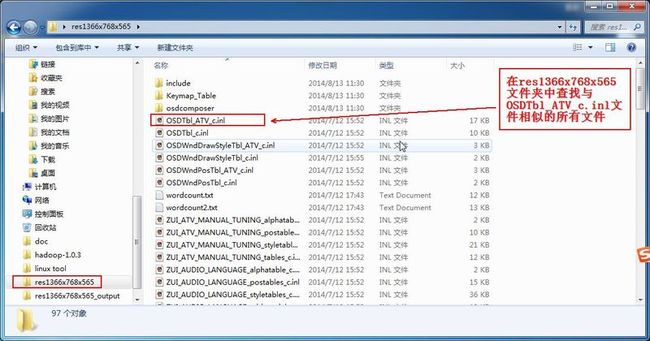
从文件夹res1366x768x565中,查找与OSDTbl_ATV_c.inl文件相似的所有文件。
四、simhash算法实现步骤
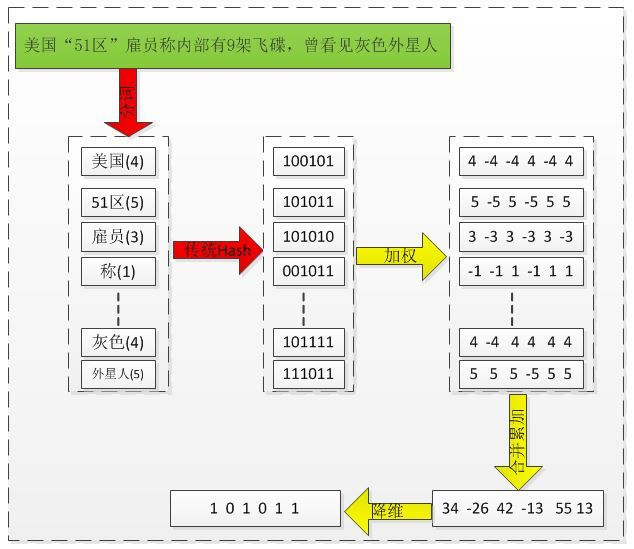
1、分词
1)、把需要判断的文本进行分词,形成这个文章的特征单词。
2)、最后形成去掉噪音词的单词序列,并为每个单词加上权重。
2、生成传统hash值
通过传统hash算法,对文章的每个特征单词产生一个f位的签名b。
3、降维过程
1)、加权
通过步骤2中生成的hash值,需要按照单词的权重形成加权数字串。
2)、合并
把步骤3中第一步各个单词算出来的序列值对应位累加,变成只有一个序列串。
3)、降维
把步骤2中第三步算出来的序列串变成0 1串,形成我们最终的simhash签名。
通过以上操作的转换,我们把库里的文本都转换为simhash代码,并转换为string类型存储,空间大大减少。接下来我们通过海明距离(Hamming distance)计算两个simhash到底相不相似。
海明距离简介
两个码字的对应比特取值不同的比特数称为这两个码字的海明距离。
举例如下: 10101 和 00110 从第一位开始依次有第一位、第四、第五位不同,则海明距离为3。
计算海明距离的普遍算法为:
对于二进制字符串的a和b,海明距离为a,b做异或操作(a XOR b)后,结果中1的个数。
异或: 只有在两个比较的位不同时其结果是1 ,否则结果为 0
到此,我们完成了simhash算法的所有步骤。
总结simhash算法的步骤:
1、生成每个文件的simhash值
2、计算两个文件的Hamming distance
五、Simhash适用情境
simhash用于比较大文本,比如500字以上效果都还蛮好,距离小于3的基本都是相似,误判率也比较低。但是如果我们处理的是微博信息,最多也就140个字,使用simhash的效果并不那么理想。看如下图,在距离为3时是一个比较折中的点,在距离为10时效果已经很差了,不过我们测试短文本很多看起来相似的距离确实为10。如果使用距离为3,短文本大量重复信息不会被过滤,如果使用距离为10,长文本的错误率也非常高,如何解决?

参考资料:《simHash 简介以及 java 实现》http://www.open-open.com/lib/view/open1375690611500.html