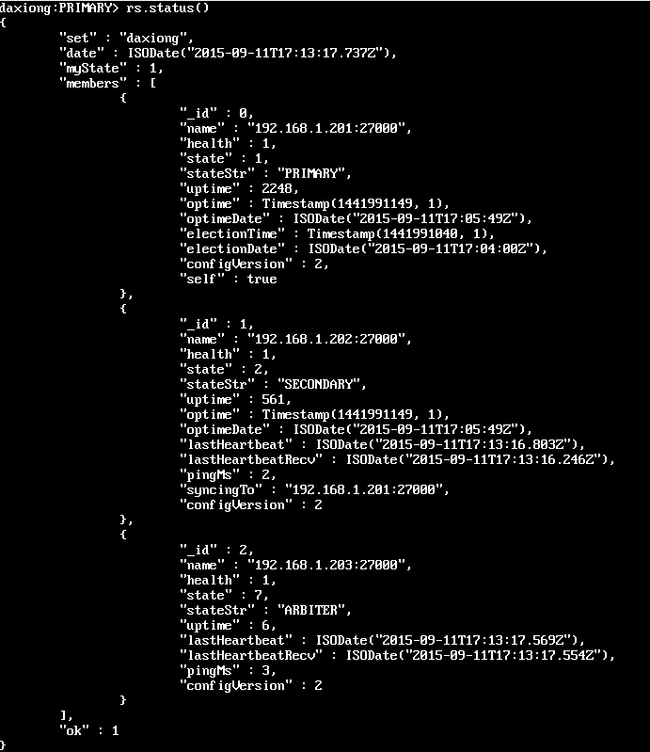
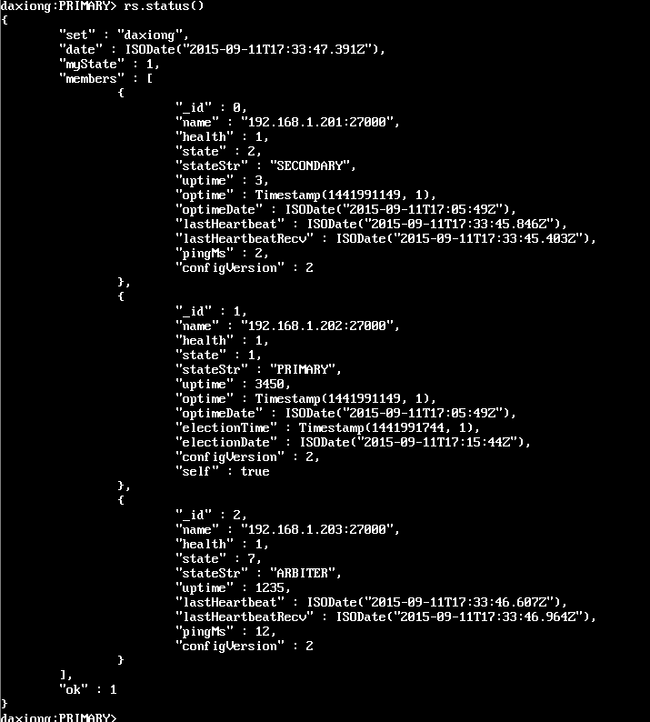
- github上的python代码怎么运行_使用 Python 在 GitHub 上运行你的博客 -Fun言
weixin_39946300
使用Pelican创建博客,这是一个基于Python的平台,与GitHub配合的不错。GitHub是一个非常流行的用于源代码控制的Web服务,它使用Git同步本地文件和GitHub服务器上保留的副本,这样你就可以轻松地共享和备份你的工作。除了为代码仓库提供用户界面之外,GitHub还运允许用户直接从仓库发布网页。GitHub推荐的网站生成软件包是Jekll,是使用Ruby编写的。因为我是Pytho
- Linux 如何使用dd命令来复制和转换数据?
我是唐青枫
Linuxlinux服务器运维
简介Linux中的dd命令是一个功能强大的数据复制和转换实用程序。它以较低级别运行,通常用于创建可启动的USB驱动器、克隆磁盘和生成随机数据等任务。dd全称可以为:dataduplicator、diskdestroyer和DataDefinition功能和能力磁盘映像:创建整个磁盘或分区的精确、逐位副本数据擦除:使用零或随机数据安全地覆盖驱动器文件转换:ASCII和EBCDIC之间的转换、字节顺序
- 分布式架构
linzheda
什么是分布式架构分布式系统(distributedsystem)是建立在网络之上的软件系统。内聚性是指每一个数据库分布节点高度自治,有本地的数据库管理系统。透明性是指每一个数据库分布节点对用户的应用来说都是透明的,看不出是本地还是远程。在分布式数据库系统中,用户感觉不到数据是分布的,即用户不须知道关系是否分割、有无副本、数据存于哪个站点以及事务在哪个站点上执行等。简单来讲:在一个分布式系统中,一组
- 2024 年最新基于 Spring Cloud 的微服务架构分析
2401_83916326
程序员架构springcloud微服务
SpringCloud的核心组件==================1.Eureka(注册中心)================Eureka是SpringCloud微服务架构中的注册中心,专门负责服务的注册与发现,里面有一个注册表,保存了各个服务器的机器和端口。Eureka服务端:也称服务注册中心,同其他服务注册中心一样,支持高可用配置。如果Eureka以集群模式部署,当集群中有分片出现故障时,那
- 如何使用 Flask-Caching 提高性能?
Channing Lewis
Pythonflaskpython后端
在Flask中,使用Flask-Caching可以显著提高应用的性能,尤其是对于计算密集型操作、数据库查询或外部API调用。Flask-Caching通过存储数据的副本减少重复计算,从而加快响应速度。1.安装Flask-Caching首先,安装Flask-Caching:pipinstallFlask-Caching2.配置Flask-Caching在Flask应用中,配置缓存类型和参数,例如使用
- 如何部署 Flask 应用程序到生产环境?
Channing Lewis
Pythonflaskpython后端
在生产环境中部署Flask应用程序需要考虑稳定性、安全性、可扩展性和性能。以下是Flask应用的常见生产部署方法及最佳实践:1.选择部署方式常见的Flask生产环境部署方式包括:部署方式适用场景说明Gunicorn+Nginx适合中小型项目轻量级,性能稳定uWSGI+Nginx高性能并发、生产环境推荐生产级别,支持异步工作Docker+Kubernetes容器化部署,微服务架构适合大规模微服务集群
- CDH日志清理
只是甲
#CDH大数据平台大数据和数据仓库Cloudera日志清理hadoop
备注:CDH版本:6.3.1背景CDH集群运行了2个多月了,根目录磁盘使用率接近80%了,需要清理CDH日志。一.查看问题CDH的日志文件一般在如下几个目录,可以通过如下代码进行查看。代码:cd/var/log/du-s./*|sort-nrcd/var/lib/cloudera-service-monitordu-s./*|sort-nrcd/var/lib/cloudera-host-moni
- TiDB架构分析
梦江河
大数据tidb数据库
TiDB有三部分组成:存储层:TiKV计算层:TiDB调度层:PD(PlaceDriver)存储元数据存储层TiKV1)通过range分区算法将数据分成一个个region;2)每个region默认有3个副本,一个leader副本和两个follower副本,这些副本分布在不同节点上,通过raft协议保证数据一致性;3)如果副本数量发生了变化,pd会及时感知,做出应对措施;计算层TiDB将SQL请求映
- Spark运行模式及Spark on Yarn两种运行模式的区别
DataCrafter
Spark大数据计算框架spark大数据
如果觉得这篇文章对您有帮助,别忘了点赞、分享或关注哦!您的一点小小支持,不仅能帮助更多人找到有价值的内容,还能鼓励我持续分享更多精彩的技术文章。感谢您的支持,让我们一起在技术的世界中不断进步!Spark运行模式1.Standalone模式描述:Standalone模式是Spark的独立集群模式,Spark自己管理资源和调度任务。适合小型集群或个人开发环境。特点:简单易用,适合开发和测试。不依赖外部
- TiKV - 读写与Coprocessor
m0_75231205
tidb
数据的写入日志持久化在rocksdbraft中,kv持久化在rocksdbkv中,Raft保证了数据的多副本一致性。raftstorepool:线程池,收到写请求,将写请求转化为raft日志,持久化日志,将日志发送给其他日志所在节点,其他的raftstorepool负责接收,将日志持久化到rocksdbraft中,当副本大多数TiKV节点返回append成功了,就认为Raft日志做的修改,它com
- Kubernetes入门
I~Lucky
kubernetes容器云原生
什么是Kubernetes?Kubernetes(简称K8s)是一个开源的容器编排平台,主要用于自动化应用的部署、扩展和管理。它可以帮助开发者和运维人员管理容器化的应用,使得服务能够在不同的主机之间进行调度,从而实现负载均衡、高可用和自动伸缩。Kubernetes的工作原理Kubernetes通过将应用打包到容器中,并在集群中运行这些容器来实现应用的部署和管理。容器是轻量级的、可移植的、自包含的软
- 【大数据入门核心技术-Hive】(十六)hive表加载csv格式数据或者json格式数据
forest_long
大数据技术入门到21天通关大数据hivehadoop开发语言后端数据仓库
一、环境准备hive安装部署参考:【大数据入门核心技术-Hive】(三)Hive3.1.2非高可用集群搭建【大数据入门核心技术-Hive】(四)Hive3.1.2高可用集群搭建二、hive加载Json格式数据1、数据准备vistu.json[{"id":111,"name":"name111"},{"id":222,"name":"name22"}]上传到hdfshadoopfs-putstu.j
- 分布式微服务技术,模拟面试与解答。RabbitMQ(五)
zxb11c
rabbitmq分布式
分布式微服务技术,模拟面试与解答。Consul(一)分布式微服务技术,模拟面试与解答。Ocelot(二)分布式微服务技术,模拟面试与解答。Redis(三)分布式微服务技术,模拟面试与解答。MongoDB(四)分布式微服务技术,模拟面试与解答。RabbitMQ(五)分布式微服务技术,模拟面试与解答。Nacos(六)分布式微服务技术,模拟面试与解答。ELK(七)分布式微服务技术,模拟面试与解答。Sky
- 13 CAP理论和base理论
40岁的系统架构师
系统架构
CAP理论解释C:consistency(一致性)。指数据在多个副本之间能够保持一致的特性(强一致性)A:availability(可用性)。一个系统提供的服务必须一直处于可用的状态,每次请求都能够获取到非错误的响应(不保证获取的数据为最新的数据)P:partitiontolerance(分区容错性)。分布式系统在遇到部分网络分区故障的时候,仍能对外提供满足一致性和可用性的服务(整个网络瘫痪除外)
- Kubernetes网络
qichengzong_right
linuxkubernetes云原生linux云原生kubernetes
Kubernetes网络Kubernetes网络模型相关概念链接Kubernetes网络模型Kubernetes网络模型由多个关键部分构建而成:在Kubernetes集群中,每个Pod都会被分配一个独一无二的、在集群范围内有效的IP地址。Pod拥有自己独立的私有网络命名空间,该命名空间由Pod内的所有容器共享。这意味着,在同一Pod中运行的不同容器进程能够通过localhost进行便捷的相互通信。
- y98.第六章 微服务、服务网格及Envoy实战 -- 集群管理(九)
Raymond运维
云原生-微服务治理企业实战(已完结)microservicesenvoy运维云计算云原生
8.集群管理8.0本节话题集群管理器与服务发现机制主动健康状态检测与异常点探测负载均衡策略分布式负载均衡负载均衡算法:加权轮询、加权最少连接、环哈希、磁悬浮和随机等;区域感知路由全局负载均衡位置优先级位置权重均衡器子集熔断和连接池8.1集群管理器(ClusterManager)Envoy支持同时配置任意数量的上游集群,并基于ClusterManager管理它们;ClusterManager负责为集
- TiDB架构特性
#TiDBTiDB
文章目录TiDB整体架构TiDBServerPDServerTiKVServerTiSparkTiDBOperatorTiDB核心特性水平扩展高可用TiDB存储和计算能力存储能力-TiKV-LSM计算能力-TiDBServer总结TiDB整体架构 TiDB集群主要包括三个核心组件:TiDBServer,PDServer和TiKVServer。此外,还有用于解决用户复杂OLAP需求的TiSpark
- TiDB分布式数据库架构与核心原理
AI天才研究院
Python实战深度学习实战自然语言处理人工智能语言模型编程实践开发语言架构设计
作者:禅与计算机程序设计艺术1.简介TiDB是PingCAP公司2017年开源的分布式HTAP(HybridTransactional/AnalyticalProcessing)数据库产品,其目标是在强一致性、高性能和易用性之间找到平衡点。TiDB的特点是融合了传统的RDBMS和NoSQL的最佳特性,具备水平扩展能力、高可用特性、强一致性和实时HTAP查询功能等优秀特性。本文从整体架构、集群设计、
- 大数据学习(七)Python3操作livy(使用pylivy模块)
猪笨是念来过倒
大数据大数据python
Livy是一个用于与Spark交互的开源REST接口。pylivy是Livy的Python客户端,可以在Spark集群上轻松实现远程代码执行。安装$pipinstall-Ulivy请注意,pylivy需要Python3.6或更高版本。用法所述LivySession类的主界面提供由pylivy:from
- 对象的克隆 单例模式
黄亚磊11
c++
1)如何实现对象的克隆?1、为什么需要实现对象的克隆?在某些情况下,需要创建一个与现有对象完全相同的副本,这就是对象克隆。例如,在需要对对象进行备份、在不同的上下文中使用相同的类型的对象或者实现某些设计模式(如原型模式)时,克隆对象是很有用的。2、在C++中如何实现对象的克隆?浅克隆:简单的复制对象的成员变量,但如果成员变量是指针类型,只会复制指针的值,而不是指针所指向的对象。这可能会导致多个对象
- Kubectl常用命令操作
_Eden_
linux运维服务器
kubectl命令格式:kubectlcommandtypenamecommand:表示子命令,用于操作kubernetes的集群资源对象,如:createdeletedescribegetapplytype:资源对象的类型name:资源对象的名称1.创建资源对象kubectlcreate-fmy-service.yaml表示根据yaml配置文件创建service2.查看资源对象kubectlge
- Zookeeper(23)Zookeeper的选举机制是什么?
辞暮尔尔-烟火年年
微服务zookeeper分布式云原生
Zookeeper的选举机制是确保在集群中始终有一个唯一的Leader。Leader负责处理所有的写请求和协调事务的提交,而Follower负责处理读请求和转发写请求给Leader。选举机制的核心是ZookeeperAtomicBroadcast(Zab)协议,它确保在发生节点故障或网络分区时,能够快速而可靠地选出新的Leader。Zookeeper选举机制详细介绍初始选举:当Zookeeper集
- 在K8S中,如果后端NFS存储的IP发送变化如何解决?
Dusk_橙子
K8Skubernetestcp/ip容器
在Kubernetes中,如果后端NFS存储的IP地址发生了变化,您需要更新与之相关的PeristentVolume(PV)或PersistentVolumeClaim(PVC)以及StorageClass中关于NFS服务器IP的配置信息,确保K8S集群内的Pod能够正确连接到新的NFS存储位置。解决方案如下:更新PersistentVolume(PV):如果你直接在PV中指定了NFS服务器的IP
- cascading 入门 (一)
zhumin726
1cascading是什么cascading是一个架构在Hadoop上的API,用来创建复杂和容错数据处理工作流。它抽象了集群拓扑结构和配置来快速开发复杂分布式的应用,而不用考虑背后的MapReduce。Cascading目前依赖于Hadoop提供存储和执行架构,但是CascadingAPI为开发者隔离了Hadoop的技术细节,提供了不需要改变初始流程工作流定义就可以在不同的计算框架内运行的能力。
- 滚雪球学Redis[4.1讲]:Redis的高可用性与集群架构
bug菌¹
#滚雪球学Redisredis架构数据库
全文目录:前言1.Redis主从复制主从复制的概念与原理设置主从复制的步骤主从复制中的常见问题与解决方法2.RedisSentinelSentinel的工作原理Sentinel的配置与使用高可用架构下的故障转移3.RedisClusterCluster模式的架构与原理Cluster的配置与使用分片与槽位的管理集群管理中的常见问题与优化小结下期预告前言在上一期内容【第三章:Redis的持久化机制】中
- GPU 集群和分布式计算
AI天才研究院
计算AI大模型企业级应用开发实战大数据AI人工智能javapythonjavascriptkotlingolang架构人工智能大厂程序员硅基计算碳基计算认知计算生物计算深度学习神经网络大数据AIGCAGILLM系统架构设计软件哲学Agent程序员实现财富自由
《GPU集群和分布式计算》关键词:GPU集群、分布式计算、CUDA、OpenACC、OpenMP、性能优化、故障处理、案例分析摘要:本文详细探讨了GPU集群和分布式计算的基本概念、架构、编程模型以及应用场景。通过剖析GPU集群在多个领域的实际应用,探讨了性能优化和故障处理的方法,并提供了若干案例以加深理解。文章旨在为读者提供一个全面而深入的GPU集群和分布式计算的知识框架。《GPU集群和分布式计算
- 360智算中心万卡GPU集群架构分析
科技互联人生
科技数码人工智能硬件架构系统架构人工智能
360智算中心:万卡GPU集群落地实践 360智算中心是一个融合了人工智能、异构计算、大数据、高性能网络、AI平台等多种技术的综合计算设施,旨在为各类复杂的AI计算任务提供高效、智能化的算力支持。360智算中心不仅具备强大的计算和数据处理能力,还结合了AI开发平台,使得计算资源的使用更加高效和智能化。360内部对于智算中心的核心诉求是性能和稳定性,本文将深入探讨3
- K8S中ingress详解
元气满满的热码式
kubernetes容器云原生
Ingress介绍Kubernetes集群中,服务(Service)是一种抽象,它定义了一种访问Pod的方式,无论这些Pod如何变化,服务都保持不变。服务可以被映射到一个静态的IP地址(ClusterIP)、一个NodePort(在集群的每个节点上的特定端口)、一个LoadBalancer(通过云服务提供商的负载均衡器)或一个外部IP。Service的两种服务暴露方式,NodePort和LoadB
- Linux 时间同步服务
不想起昵称929
linux
时间同步:多主机协作工作时,各个主机的时间同步很重要,时间不一致会造成很多重要应用的故障,如:加密协议,日志,集群等,利用NTP(NetworkTimeProtocol)协议使网络中的各个计算机时间达到同步。目前NTP协议属于运维基础架构中必备的基本服务之一时间同步实现:ntp,chrony//关闭系统同步时间服务timedatectlstopchronyd.servicentp:将系统时钟和世界
- HAProxy集群与常见的Web集群软件调度器对比
EsDeath_99
java服务器linux
一、Web集群调度器1.常见的Web集群调度器常用的Web集群调度器分为软件和硬件,负载均衡性能(硬件负载均衡器F5>LVS>Haproxy>Nginx)软件调度器(开源)1.LVS:性能最好,搭建复杂2.Nginx:性能较好,但集群节点健康检查功能不强,高并发性能较弱3.Haproxy:高并发性能好硬件调度器1.F52.梭子鱼、绿盟、F5、Array等2.常见集群调度器的优缺点(LVS、Ngin
- java杨辉三角
3213213333332132
java基础
package com.algorithm;
/**
* @Description 杨辉三角
* @author FuJianyong
* 2015-1-22上午10:10:59
*/
public class YangHui {
public static void main(String[] args) {
//初始化二维数组长度
int[][] y
- 《大话重构》之大布局的辛酸历史
白糖_
重构
《大话重构》中提到“大布局你伤不起”,如果企图重构一个陈旧的大型系统是有非常大的风险,重构不是想象中那么简单。我目前所在公司正好对产品做了一次“大布局重构”,下面我就分享这个“大布局”项目经验给大家。
背景
公司专注于企业级管理产品软件,企业有大中小之分,在2000年初公司用JSP/Servlet开发了一套针对中
- 电驴链接在线视频播放源码
dubinwei
源码电驴播放器视频ed2k
本项目是个搜索电驴(ed2k)链接的应用,借助于磁力视频播放器(官网:
http://loveandroid.duapp.com/ 开放平台),可以实现在线播放视频,也可以用迅雷或者其他下载工具下载。
项目源码:
http://git.oschina.net/svo/Emule,动态更新。也可从附件中下载。
项目源码依赖于两个库项目,库项目一链接:
http://git.oschina.
- Javascript中函数的toString()方法
周凡杨
JavaScriptjstoStringfunctionobject
简述
The toString() method returns a string representing the source code of the function.
简译之,Javascript的toString()方法返回一个代表函数源代码的字符串。
句法
function.
- struts处理自定义异常
g21121
struts
很多时候我们会用到自定义异常来表示特定的错误情况,自定义异常比较简单,只要分清是运行时异常还是非运行时异常即可,运行时异常不需要捕获,继承自RuntimeException,是由容器自己抛出,例如空指针异常。
非运行时异常继承自Exception,在抛出后需要捕获,例如文件未找到异常。
此处我们用的是非运行时异常,首先定义一个异常LoginException:
/**
* 类描述:登录相
- Linux中find常见用法示例
510888780
linux
Linux中find常见用法示例
·find path -option [ -print ] [ -exec -ok command ] {} \;
find命令的参数;
- SpringMVC的各种参数绑定方式
Harry642
springMVC绑定表单
1. 基本数据类型(以int为例,其他类似):
Controller代码:
@RequestMapping("saysth.do")
public void test(int count) {
}
表单代码:
<form action="saysth.do" method="post&q
- Java 获取Oracle ROWID
aijuans
javaoracle
A ROWID is an identification tag unique for each row of an Oracle Database table. The ROWID can be thought of as a virtual column, containing the ID for each row.
The oracle.sql.ROWID class i
- java获取方法的参数名
antlove
javajdkparametermethodreflect
reflect.ClassInformationUtil.java
package reflect;
import javassist.ClassPool;
import javassist.CtClass;
import javassist.CtMethod;
import javassist.Modifier;
import javassist.bytecode.CodeAtt
- JAVA正则表达式匹配 查找 替换 提取操作
百合不是茶
java正则表达式替换提取查找
正则表达式的查找;主要是用到String类中的split();
String str;
str.split();方法中传入按照什么规则截取,返回一个String数组
常见的截取规则:
str.split("\\.")按照.来截取
str.
- Java中equals()与hashCode()方法详解
bijian1013
javasetequals()hashCode()
一.equals()方法详解
equals()方法在object类中定义如下:
public boolean equals(Object obj) {
return (this == obj);
}
很明显是对两个对象的地址值进行的比较(即比较引用是否相同)。但是我们知道,String 、Math、I
- 精通Oracle10编程SQL(4)使用SQL语句
bijian1013
oracle数据库plsql
--工资级别表
create table SALGRADE
(
GRADE NUMBER(10),
LOSAL NUMBER(10,2),
HISAL NUMBER(10,2)
)
insert into SALGRADE values(1,0,100);
insert into SALGRADE values(2,100,200);
inser
- 【Nginx二】Nginx作为静态文件HTTP服务器
bit1129
HTTP服务器
Nginx作为静态文件HTTP服务器
在本地系统中创建/data/www目录,存放html文件(包括index.html)
创建/data/images目录,存放imags图片
在主配置文件中添加http指令
http {
server {
listen 80;
server_name
- kafka获得最新partition offset
blackproof
kafkapartitionoffset最新
kafka获得partition下标,需要用到kafka的simpleconsumer
import java.util.ArrayList;
import java.util.Collections;
import java.util.Date;
import java.util.HashMap;
import java.util.List;
import java.
- centos 7安装docker两种方式
ronin47
第一种是采用yum 方式
yum install -y docker
- java-60-在O(1)时间删除链表结点
bylijinnan
java
public class DeleteNode_O1_Time {
/**
* Q 60 在O(1)时间删除链表结点
* 给定链表的头指针和一个结点指针(!!),在O(1)时间删除该结点
*
* Assume the list is:
* head->...->nodeToDelete->mNode->nNode->..
- nginx利用proxy_cache来缓存文件
cfyme
cache
user zhangy users;
worker_processes 10;
error_log /var/vlogs/nginx_error.log crit;
pid /var/vlogs/nginx.pid;
#Specifies the value for ma
- [JWFD开源工作流]JWFD嵌入式语法分析器负号的使用问题
comsci
嵌入式
假如我们需要用JWFD的语法分析模块定义一个带负号的方程式,直接在方程式之前添加负号是不正确的,而必须这样做:
string str01 = "a=3.14;b=2.71;c=0;c-((a*a)+(b*b))"
定义一个0整数c,然后用这个整数c去
- 如何集成支付宝官方文档
dai_lm
android
官方文档下载地址
https://b.alipay.com/order/productDetail.htm?productId=2012120700377310&tabId=4#ps-tabinfo-hash
集成的必要条件
1. 需要有自己的Server接收支付宝的消息
2. 需要先制作app,然后提交支付宝审核,通过后才能集成
调试的时候估计会真的扣款,请注意
- 应该在什么时候使用Hadoop
datamachine
hadoop
原帖地址:http://blog.chinaunix.net/uid-301743-id-3925358.html
存档,某些观点与我不谋而合,过度技术化不可取,且hadoop并非万能。
--------------------------------------------万能的分割线--------------------------------
有人问我,“你在大数据和Hado
- 在GridView中对于有外键的字段使用关联模型进行搜索和排序
dcj3sjt126com
yii
在GridView中使用关联模型进行搜索和排序
首先我们有两个模型它们直接有关联:
class Author extends CActiveRecord {
...
}
class Post extends CActiveRecord {
...
function relations() {
return array(
'
- 使用NSString 的格式化大全
dcj3sjt126com
Objective-C
格式定义The format specifiers supported by the NSString formatting methods and CFString formatting functions follow the IEEE printf specification; the specifiers are summarized in Table 1. Note that you c
- 使用activeX插件对象object滚动有重影
蕃薯耀
activeX插件滚动有重影
使用activeX插件对象object滚动有重影 <object style="width:0;" id="abc" classid="CLSID:D3E3970F-2927-9680-BBB4-5D0889909DF6" codebase="activex/OAX339.CAB#
- SpringMVC4零配置
hanqunfeng
springmvc4
基于Servlet3.0规范和SpringMVC4注解式配置方式,实现零xml配置,弄了个小demo,供交流讨论。
项目说明如下:
1.db.sql是项目中用到的表,数据库使用的是oracle11g
2.该项目使用mvn进行管理,私服为自搭建nexus,项目只用到一个第三方 jar,就是oracle的驱动;
3.默认项目为零配置启动,如果需要更改启动方式,请
- 《开源框架那点事儿16》:缓存相关代码的演变
j2eetop
开源框架
问题引入
上次我参与某个大型项目的优化工作,由于系统要求有比较高的TPS,因此就免不了要使用缓冲。
该项目中用的缓冲比较多,有MemCache,有Redis,有的还需要提供二级缓冲,也就是说应用服务器这层也可以设置一些缓冲。
当然去看相关实现代代码的时候,大致是下面的样子。
[java]
view plain
copy
print
?
public vo
- AngularJS浅析
kvhur
JavaScript
概念
AngularJS is a structural framework for dynamic web apps.
了解更多详情请见原文链接:http://www.gbtags.com/gb/share/5726.htm
Directive
扩展html,给html添加声明语句,以便实现自己的需求。对于页面中html元素以ng为前缀的属性名称,ng是angular的命名空间
- 架构师之jdk的bug排查(一)---------------split的点号陷阱
nannan408
split
1.前言.
jdk1.6的lang包的split方法是有bug的,它不能有效识别A.b.c这种类型,导致截取长度始终是0.而对于其他字符,则无此问题.不知道官方有没有修复这个bug.
2.代码
String[] paths = "object.object2.prop11".split("'");
System.ou
- 如何对10亿数据量级的mongoDB作高效的全表扫描
quentinXXZ
mongodb
本文链接:
http://quentinXXZ.iteye.com/blog/2149440
一、正常情况下,不应该有这种需求
首先,大家应该有个概念,标题中的这个问题,在大多情况下是一个伪命题,不应该被提出来。要知道,对于一般较大数据量的数据库,全表查询,这种操作一般情况下是不应该出现的,在做正常查询的时候,如果是范围查询,你至少应该要加上limit。
说一下,
- C语言算法之水仙花数
qiufeihu
c算法
/**
* 水仙花数
*/
#include <stdio.h>
#define N 10
int main()
{
int x,y,z;
for(x=1;x<=N;x++)
for(y=0;y<=N;y++)
for(z=0;z<=N;z++)
if(x*100+y*10+z == x*x*x
- JSP指令
wyzuomumu
jsp
jsp指令的一般语法格式: <%@ 指令名 属性 =”值 ” %>
常用的三种指令: page,include,taglib
page指令语法形式: <%@ page 属性 1=”值 1” 属性 2=”值 2”%>
include指令语法形式: <%@include file=”relative url”%> (jsp可以通过 include