散列表(hash table)
基本概念
散列表根据关键码直接访问表,把关键码映射到表中的记录来访问记录,这个过程成为散列(hashing)
把关键码值映射到位置的函数成为散列函数(hash function),用h表示
存放记录的数组称为散列表(hash table),用HT表示
散列表中的一个位置被称为一个槽(slot),散列表HT中的槽的数目用变量M表示,从0到M-1编号
设计散列方法的目标是使得对于任意关键码值K和某个散列函数h,0<=h(K)<=M-1,有HT[i]=K
查找过程
在一个根据散列方法组织的数据库中,找到带有关键码值K的记录有两个过程
1、计算表的位置h(k)
2、从槽h(k)开始,使用冲突解决策略找到包含关键码值的记录
散列函数
为什么使用散列函数?记录关键码的范围很大,把记录存放在一个槽数相对较少的表中,两条记录映射到表中的同一个槽就会发生冲突。冲突不可避免。一般我们希望选择的散列函数可以把记录用相同的概率分布到散列表的所有槽中。
散列函数举例
1、将整数散列到有16个槽的表中
int h(int x) {
return(x % 16);
}
散列函数的值依赖于关键码低四位
2、平方取中法,适用于数
计算关键码值的平方,取中间R位,关键码值的大多数位或所有位都对结果有贡献
3、字符串散列函数
int h(String x, int M) {
char ch[];
ch = x.toCharArray();
int xlength = x.length();
int i, sum;
for (sum=0, i=0; i<x.length(); i++)
sum += ch[i];
return sum % M;
}
将字符串所有ASCII累加,对所有字符赋予同样的权重
冲突解决技术
冲突解决技术分为两类:开散列方法(单链方法) 闭散列方法(开地址方法)
开散列方法
开散列方法的一种简单形式把散列表的每个槽定义为一个链表的表头,散列到一个槽中的所有记录都放在该槽的链表内。
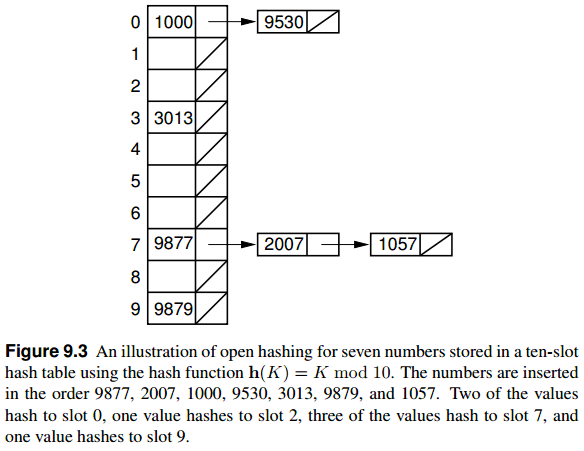
链表中的记录可以按照插入次序排列,或者按照关键码值次序排列。
按照关键码排序的情况,如果遇到一个比检索值大的关键码就应该停止检索。而按照插入次序就需要遍历链表每一个记录。
闭散列方法
闭散列方法把所有记录直接存储在散列表中,每条记录有一个基位置(home position)h(k),即由散列函数计算出来的槽。如果插入一条记录R而另外一条记录已经占据了R的基位置,就把R存储在表的其他槽,由冲突解决策略确定应该是哪一个槽。检索应该遵循同样的策略。
桶式散列
把散列表中的M个槽分为B个桶(bucket),每个桶包含M/B个槽。散列函数把每一条记录分配到桶中的第一个槽中,如果该槽已经被占用就顺序沿桶查找知道找到一个空槽。如果一个桶全部被占满了就把记录存储到表后面具有无限容量的溢出桶中。所有桶共享一个溢出桶。

线性探测
冲突解决策略:可以产生一组可能放置记录的散列表的槽,第一个位置被占用,冲突解决策略就会达到这个组的下一个槽,以此类推直到找到一个空槽。这组槽被称为探测序列。
/
**
Insert record r with key k into HT
*
/
void hashInsert(Key k, E r) {
int home; // Home position for r
int pos = home = h(k); // Initial position
for (int i=1; HT[pos] != null; i++) {
pos = (home + p(k, i)) % M; // Next pobe slot
assert HT[pos].key().compareTo(k) != 0 :
"Duplicates not allowed";
}
HT[pos] = new KVpair<Key,E>(k, r); // Insert R
}
/
**
Search in hash table HT for the record with key k
*
/
E hashSearch(Key k) {
int home; // Home position for k
int pos = home = h(k); // Initial position
for (int i = 1; (HT[pos] != null) &&
(HT[pos].key().compareTo(k) != 0); i++)
pos = (home + p(k, i)) % M; // Next probe position
if (HT[pos] == null)
return null; // Key not in hash table
else
return HT[pos].value(); // Found it
}
p(k,i)是探查函数,为关键码R的探查序列第i个槽返回从基位置开始的偏移量。
最简单的p(k,i)
p(k,i)=i mod M可能产生基本聚集
改进的探测函数
p(k, i) =(h(K) + ic) mod M,每次不是跳过1个槽而是跳过n个槽
一个简单的的hashtable的实现
定义节点
/** Container class for a key-value pair */
class KVpair<Key, E> {
private Key k;
private E e;
/** Constructors */
KVpair()
{ k = null; e = null; }
KVpair(Key kval, E eval)
{ k = kval; e = eval; }
/** Data member access functions */
public Key key() { return k; }
public E value() { return e; }
}
定义hashtable
import java.io.*;
public class HashTable<Key extends Comparable<? super Key>, E> {
private int M;
private KVpair<Key,E>[] HT;
//hash映射函数
private int h(Key key) {
return M - 1;
}
//线性探测函数
private int p(Key key, int slot) {
return slot;
}
@SuppressWarnings("unchecked") // Generic array allocation
HashTable(int m) {
M = m;
HT = (KVpair<Key,E>[])new KVpair[M];
}
/** Insert record r with key k into HT */
void hashInsert(Key k, E r) {
int home; // Home position for r
int pos = home = h(k); // Initial position
for (int i=1; HT[pos] != null; i++) {
pos = (home + p(k, i)) % M; // Next pobe slot
assert HT[pos].key().compareTo(k) != 0 :
"Duplicates not allowed";
}
HT[pos] = new KVpair<Key,E>(k, r); // Insert R
}
/** Search in hash table HT for the record with key k */
E hashSearch(Key k) {
int home; // Home position for k
int pos = home = h(k); // Initial position
for (int i = 1; (HT[pos] != null) &&
(HT[pos].key().compareTo(k) != 0); i++)
pos = (home + p(k, i)) % M; // Next probe position
if (HT[pos] == null) return null; // Key not in hash table
else return HT[pos].value(); // Found it
}
}