大众点评数据平台架构变迁
最近和其他公司的同学对数据平台的发展题做了一些沟通,发现各自遇到的问题都类似,架构的变迁也有一定的相似性。
以下从数据&架构&应用的角度对2012.07-2014.12期间大众点评数据平台的架构变迁做一个概括性的总结,希望对还处在数据平台发展初期的同学有一些帮助,欢迎线下沟通。
1、1.0(2012.07)
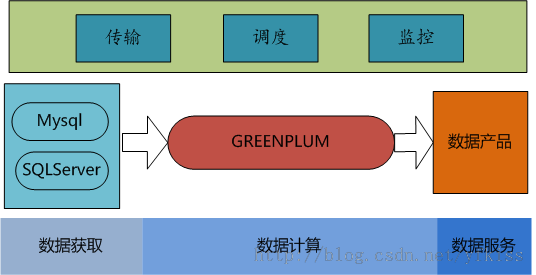
1.1 数据:
1. 以支持用户报表需求为主
2. 初步沉淀出了一些底层模型
3. 模型计算程序以python为主
1.2 架构:
1. 存储和计算都在GreenPlum
2. GreenPlum采用双集群热备,一大一小,部分关键报表数据同时在两个集群存储、计算。
3.传输:公司的DBA同学将数据从Mysql、SQLServer拉出来,落地成文件。传输程序每天凌晨解析落地的文件,然后将数据load到greenplum
4.调度:使用Quartz框架,依赖关系存放到表中,将依赖检查做成一个脚本,下游job 调用方法check上游任务是否完成
5.监控:用户程序自主判断异常,邮件、手机报警。
1.3 数据应用:
1.报表数据以邮件的形式发送给用户
2.用户可以使用自定义sql的web查询工具主动查询数据
2、2.0(2013.04)
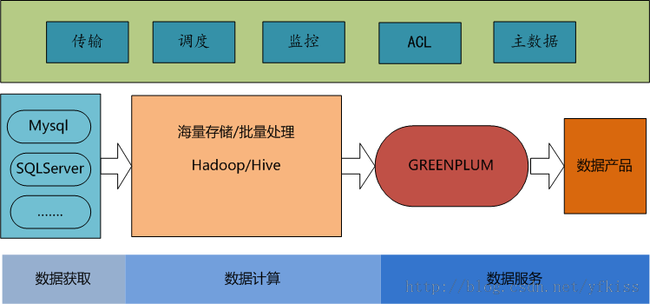
2.1 数据:
1. 有了明确的模型分层:
a) ODS:存放从原系统采集来的原始数据
b) DW:保存经过清洗,转换和重新组织的历史数据,数据将保留较长时间,满足系统最细粒度的查询需要
c) DM: 数据集市。基于部门或某一特定分析主题需要
d) RPT:直接面向用户的报表
2. 形成了流量、团购、信息三大基础模型及构建于三大基础模型之上的数据集市
3. 基于volocity开发了canaan计算框架。
4. 开发了一些自定义的UDF
2.2 架构:
1. 存储和计算都基于HIVE
2. GREENPLUM作为HIVE的“cache”存在,供用户做一些小数据的快查询,报表存储。
3. 调度:和canaan框架进行整合,支持用户快速新增任务,并自动导入任务依赖。
4. 主数据:保存了数据仓库元数据信息,供用户查询和系统内部各个模块交互。
5. ACL:构建了数据仓库数据访问权限控制,包括用户权限申请、审批者审批、数据赋权等。
6. 传输:
a)参考阿里DataX的设计,实现了点评的异构数据离线传输工具wormhole
b)可视化界面,用户通过界面操作,方便的将数据导入导出数据
c)和调度、主数据等系统打通
7. 监控:由于任务数量增长较快(2000+),运维已经是个问题此外,因此,我们花了较大精力做了可视化的工作:
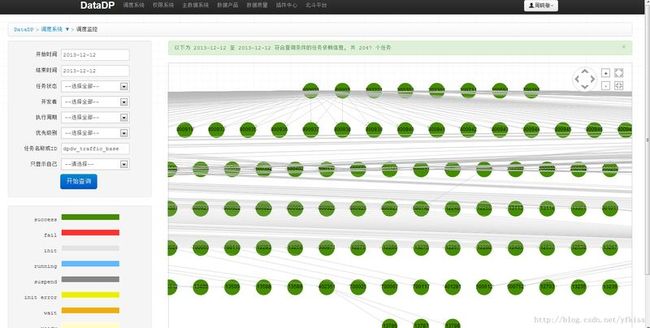
2.3 数据应用
1. 运营工具:用户自定义SQL,存储基于HIVE
2. 指标(KPI):用户自定义SQL,计算基于HIVE,结果放到GREENPLUM中,用户可以根据指标通过时间拼接成报表
3. HIVE WEB:非常便捷的HIVE WEB工具,可用性可以甩hive原生的web界面HWI几条街了
3、3.0(2013.12)
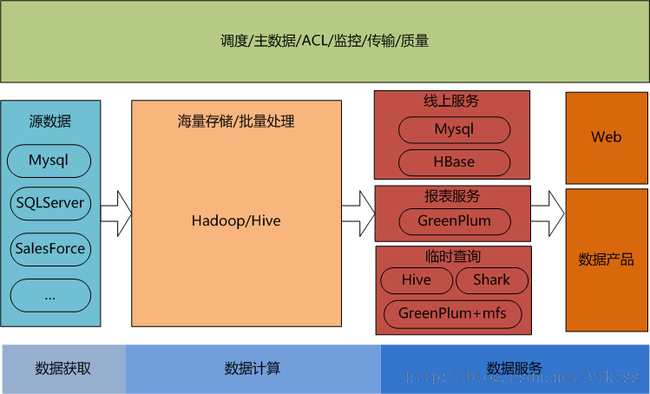
3.1 数据:
1. 有了明确的上层数据集市,各层数据集市打通,例如团购数据和流量数据打通
2. 形成了用户集市、商户集市两大主题
3. 和算法团队合作建设推荐系统
4. 提供框架和工具支持,引入外部数据开发者
3.2 架构:
1. 引入mysql、hbase,支持线上服务
2. 数据访问接口支持:API、Query Engine、RPC Service
3. 引入shark支持临时查询,出于稳定性考虑,牺牲性能,shark/spark集群和hadoop/hive集群物理隔离
4. 数据质量:用户指定以条件,对计算结果做检查
3.3 数据产品:
支持DashBoard
4、4.0(2014.12)
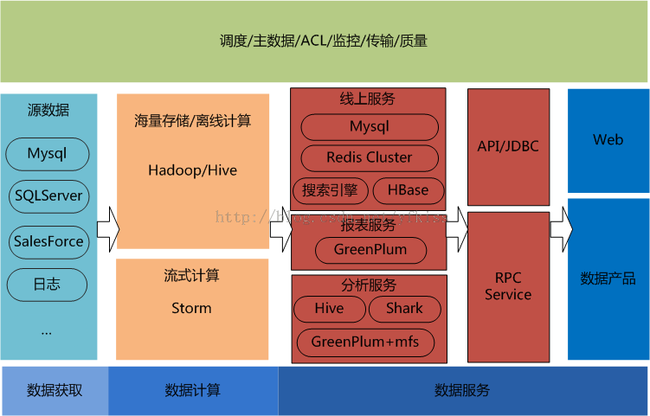
4.1 数据:
1. 持续扩充/完善数据模型
2. 数据规范化,主要包括:APP日志、渠道
3. 完善数据开发平台,其他部门数据开发者100+
4.2 架构:
1. 建设Redis Cluster,支持实时推荐、用户画像等服务
2. Hadoop升级到YARN
3. 引入Storm支持实时计算
4. 推出类Kafka的分布式消息系统,结合日志框架,支持日志数据的快速/低成本接入
5. 建设元数据中心
4.3 数据产品:
推出专有数据产品,包括:运营效果评估、流量分析产品等。
Refer:
[1] 大众点评数据平台架构变迁
http://dwz.cn/28oSBm
[2] 饿了么数据仓库治理及数据使用
http://www.infoq.com/cn/presentations/data-warehouse-management-and-data-use-of-eleme
[3] 记录一下互联网日志实时收集和实时计算的简单方案
http://dwz.cn/2gq4dp