Manacher算法
一、问题描述
现给定一个已知的字符串str[],现在想要在O(n)的时间复杂度之内求出一个最长的回文子字符串(正着和倒着顺序读一致)。
Manacher最早发现了可以用O(n)的时间复杂度来解决该问题,所以这种方法称之为Manacher算法。
二、符号说明
回文串包括奇数长的和偶数长的,一般求的时候都要分情况讨论,Manacher的这个算法做了个简单的处理,把奇偶情况统一了,为了避免索引数超出数组边界值做字符比较,可以在处理过的字符串的第一个位置(索引为0的位置)加入一个区分字符,并在这个字符串的最后加入结束标记'\0',处理后的字符串形式如最后所举的例子。P[]存放的是回文子串的半径。现在需要计算P[i]的值,那么id代表了索引号i之前的那个使得回文子串最右面的字符的索引号最大的索引号的值,用符号表示就是:
![]()
其中,argmax求得的是索引下标的值,另外引入符号mx,j=2*id-i;
![]() 。
。
三、算法步骤
下面进入更新P[]的步骤:
第一步,先初始化P[0]=0。
第二步,当i<strlen(str)时执行第三步,否则结束
第三步,判断P[id]+id=mx>i的值,如果为假执行第四步。否则执行第五步。
第四步,初始化P[i]=0,并且执行while(str[i+P[i]+1] == str[i-P[i]-1]) ++P[i];i++,得到所求的P[i]。
第五步,如果mx-i>P[j],则执行第六步,否则执行第七步。
第六步,P[i]=P[j],这时已经求出P[i],回到第二步。
第七步,这时P[i]>=mx-i,初始化P[i]=mx-i,并执行while(str[i+P[i]+1] == str[i-P[i]-1]) ++P[i];i++,得到所求的P[i],回到第二步。
下面是根据P[]找出最长回文子串的步骤:
第一步,找到P[]中的最大值,并记录最大的P[]的值以及其索引编号。
第二步,如果回文字子串的起始位置为'#'的话,最大的回文字子串的长度减1。
第三步,得出最长回文子串的一个字符在原字符串中的索引位置。
第四步,根据最长回文子串的起始索引位置编号和最大长度得出最长回文子串。
四、算法原理
下面来解释一下更新P[]的的第三步,第六步和第七步,至于其他的步骤都是非常号理解的。
首先对第三步进行说明,当P[id]+id=mx>i时说明以i为中心点可能存在回文子串,这时就可以将P[i]初始化成该回文子串的值在进行扩展搜索回文子串的半径是否能够增大,省去了P[i]从0开始搜索的一些步骤。
对第六步说明,即对mx-i>P[j]的情形进行说明。这时的字符串可以表示成下图:
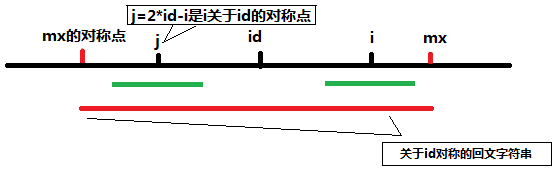
图中最下面的红色线条是之前求得的索引号i之前的那个使得回文子串最右面的字符的索引号最大的那个回文子字符串。j点是i关于id的对称点,由于红的字符串是回文字符串,所以关于j对称的回文子串和关于i对称的回文子串是完全一样的(图中两段绿色的线条),而满足mx-i>P[j]时说明此时j的回文子串半径小于j到mx关于j对称的左端点的差,此时可以初始化P[i]=P[j]。
对第七步说明,即对mx-i<=P[j]的情形进行说明。这时的字符串可以表示成下图:
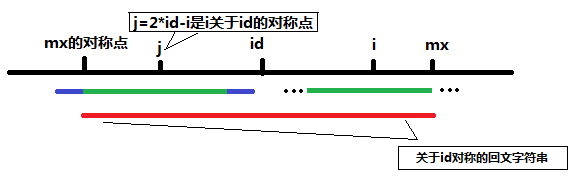
图中最下面的红色线条仍然是之前求得的索引号i之前的那个使得回文子串最右面的字符的索引号最大的那个回文子字符串。j点是i关于id的对称点,由于红的字符串是回文字符串,所以关于j对称的回文子串和关于i对称的在mx和mx的对称点之间的回文子串是完全一样的(图中两段绿色的线条),而满足mx-i<=P[j]时说明此时j的回文子串半径大于或等于j到mx关于j对称的左端点的差,此时可以初始化P[i]=mx-i,再对P[i]的回文子串半径进行进一步的增大。
根据P[]找出最长回文子串的步骤的一点说明。
如果找到转换后字符串的最长回文子串第一个字符为‘#’,则需要对最大长度减1。另外,转换后的字符串的回文子串的半径(即P[]的值)加1就是原字符串中回文子串的长度(包含的任何一个回文子串都有这个关系)。
五、算法举例
为了更好的理解算法的原理,我在这里给出一个例子。
str_s = a b a a b a; Index = 0 1 2 3 4 5 6 7 8 9 10 11 12 str[] = @ a # b # a # a # b # a '\0'; P[] = 0 0 0 2 0 1 5 1 0 2 0 0;其中最上面一行的Index是序号,str[]存的是要查找的字符串。P[]存放的是回文子串的半径。如,Index为3处的P[3]=2代表的意思是str[3]的左数2个和右数两个字符构成一个回文子串即a#b#a。下面按照算法的步骤一步一步来算这个P[]的值。
首先是初始化P[0]=0;容易得出P[1]=0;计算P[2],id=1,mx=1<2,故初始化P[2]=0,接下来匹配是否有回文字符串,即依次对P[2]向两侧展开,检查P[2]是否有相等的字符,可以得出P[2]还是为0;计算P[3],id=2,mx=2<3,初始化P[3]=0,同样检查P[3]的两侧,计算出P[3]=2;接下来计算P[4],id=3,mx=5>4,这是可以得出P[4]>=min(P[2*3-4],5-4),即这时P[4]的最小值为0,这时5-4>P[2*3-4],故P[4]=P[2*3-4]=0;计算P[5],id=3,mx=5<=5,故初始化P[5]=0,检查P[5]的两侧,这时计算出P[5]=1;计算P[6]的情况同P[5],得到P[6]=5;接下来计算P[7],id=6,mx=P[6]+6=11>7,P[7]=min(P[2*6-7],11-7)=1,即这时P[6]>=1,此时mx-i=11-7=4>=P[2*6-7],故P[7]=P[2*6-7]=1;计算P[8],id=6,mx=P[6]+6=11>8,P[8]=min(p[2*6-8],11-8)=0,初始化P[8]=0,检查P[8]的两侧,这时计算出P[8]=0;计算P[9],id=6,mx=P[6]+6=11>9,P[9]=min(P[2*6-9],11-9)=0,初始化P[9]=0,检查P[9]的两侧,这时计算出P[9]=2;后面的做相似处理可以算出所有的P[i]的值。
上面的例子可能不太合适,没有出现mx-i<=P[2*id-i]的情况,不过出现这种情况的话也按照算法的步骤分析一下即可。出现这个情况的例子我再找找试试。
六、程序实现
这个算法的C代码实现如下:
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#define MAX_BUF 1024
#define MIN(a, b) ((a)<(b)?(a):(b))
int main(int argc, char *argv[])
{
char ori_str[MAX_BUF];
while(NULL != gets(ori_str))
{
int i = 0;
int ori_strlen = 0;
while('\0' != ori_str[ori_strlen++]);
const int trans_strlen = 2 * (ori_strlen - 1);
char* str = (char*)malloc(trans_strlen + 1);
if(NULL == str)
continue;
//init string str[]
str[0] = '$';
str[1] = ori_str[0];
for(i = 1; i < ori_strlen; i++)
{
str[2 * i] = '#';
str[2 * i + 1] = ori_str[i];
}
str[trans_strlen] = '\0';
int* P = (int*) malloc(trans_strlen * sizeof(int));
if(NULL == P)
continue;
P[0] = 0;
int id = 0;
int mx = 0;
//update P[]
for(i = 1; i < strlen(str); i++)
{
if(i < mx)
P[i] = MIN(P[2 * id - i], mx - i);
else
P[i] = 0;
while(str[i + P[i] + 1] == str[i - P[i] - 1])
P[i]++;
if (P[i] + i > mx)
{
id = i;
mx = P[i] + id;
}
}
//find the longest palindromic string
int max_len = 0;
int max_index = 0;
for(i = 1; i < trans_strlen; i++)
{
if(P[i] > max_len)
{
max_len = P[i];
max_index = i;
}
}
char* longest_palindrome = (char*)malloc(max_len + 1);
if(NULL == longest_palindrome)
continue;
if('#' == str[max_index - max_len])
max_len--;
if(0 == max_len)
{
printf("There is no palindromic\n");
continue;
}
int longest_palindrome_pos = (max_index - max_len)/2;
for (i = 0; i < max_len + 1; i++)
longest_palindrome[i] = ori_str[longest_palindrome_pos++];
longest_palindrome[++max_len] = '\0';
printf("The length of the longest palindromic substring is: %d\n", max_len);
printf("The longest palindromic substring: %s\n", longest_palindrome);
free(str);
free(P);
free(longest_palindrome);
}
return 0;
}
上面的代码只用了一个主函数,应该分成几个功能的函数编写并用主函数调用。
七、参考资料
1. Find The Longest Palindromic Substring-Manacher Algorithm:
http://larrylisblog.net/WebContents/images/LongestPalindrom.pdf
2. 浅谈manacher算法:
http://blog.sina.com.cn/s/blog_70811e1a01014esn.html
3. Manacher's ALGORITHM: O(n)时间求字符串的最长回文子串:
http://www.felix021.com/blog/read.php?2040
说明:
如有错误还请各位指正,欢迎大家一起讨论给出指导。
上述程序完整代码的下载链接:
https://github.com/zeliliu/BlogPrograms/tree/master/%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84%26%E7%AE%97%E6%B3%95/manacher%20algorithm
最后更新时间2013-05-01