RabbitMQ erlang "work queues"
参考文章:http://www.rabbitmq.com/tutorials/tutorial-two-python.html
前面我们写了一个发送和接收消息的队列。 这次我们将创建一个工作队列,这个队列被用于在多个worker之间分发耗时任务。

The main idea behind Work Queues (aka: Task Queues) is to avoid doing a resource-intensive task immediately and having to wait for it to complete. Instead we schedule the task to be done later. We encapsulate atask as a message and send it to the queue. A worker process running in the background will pop the tasks and eventually execute the job. When you run many workers the tasks will be shared between them.
支持 work Queues的 原因是为了避免立即处理资源密集型任务并且需要等待它处理结束。(理解:有些队列里的消息特别的多,而某些消息需要很长的处理时间,而且处理这些消息的等待时间比较长)。取而代之我们把任务在后面处理。我们把任务包装成一个消息,并且把它发送到队列里面,后台运行的工作者进程将消费这些消息并且最终执行这些任务,如果运行了多个工作者进程(如上图:c1,c2),这些任务就可以在这些进程之间共享(即:可以使用c1,c2来处理这些任务)。
这种思想在web应用程序里面特别有用,因为不可能在一个短暂的HTTP请求里面处理复杂的任务。
准备工作
我们将发送一个字符串用来代表复杂的任务。我们没有一个实际的复杂任务比如重新定位一张图片或者渲染一个pdf文件,所有我们通过time.sleep()来假定我们很忙。我们将计算字符串里面的".",每个点将消耗一秒的工作时间。比如字符串"hello ..."将消耗3秒。
Round-robin dispatching (循环分发)
使用 Task Queue其中一个好处是它可以容易的实现并行工作。如果我们正在构建一个存储任务,我们只需要增加多个工作者。并且这种方式很容易扩展。
默认情况下, RabbitMQ会把每一个消息按顺序发送给下一个消费者。平均每个消费者都可以获取相同数量的消息。这种分发消息的方式成为循环分发。

Message acknowledgment(消息确认)
完成一个任务会花费一些时间。 你可能问,当一个消费者在执行一个耗时很长的任务,但做到一半的时候,这个消费者崩溃了,会发生什么事情呢?在我们这个例子中,当把消费者投递给一个消费者后,RabbitMQ会把这条消息从内存中立刻删除。在这种情况下,如果你把消费者kill 掉,那么消费者当前正在处理的消息就丢掉了。所有已经发送给这个消费者并且还没处理的消费也都会丢掉。
但是我们并不想失去任何任务,如果一个消费者崩溃了,我们希望把任务投递给其他的消费者去处理。
为了确保消息永远不会丢失,RabbitMQ支持消息确认。消费者会回发一个ack消息给RabbitMQ, 告诉RabbitMQ特定的消息已经接受和处理,RabbitMQ可以把它删除了。
如果消费者没有发回ack消息并崩溃了,RabbitMQ就知道这条消息并没有被完全处理,它会把这条消息投递给另外的消费者处理。这就保证了消息永远不会丢失。
没有任何消息超时机制,只有当消费者连接断了以后,RabbitMQ才会重新发送消息。所以相关消息处理多长的时间都没关系。
消息确认机制默认是开启的。
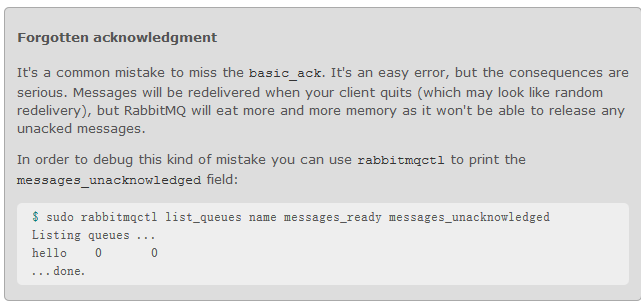
Message durability (消息持久化)
虽然现在我们已经能保证消费者崩溃之后,消息不丢失,但是当RabbitMQ崩溃时,消息还是会丢失。
当RabbitMQ 退出或者崩溃时,所有的队列和消息都会丢失,除非你告诉它不要丢失。在这种情况下,为了确保不丢失消息,我们必须做两件事情:我们必须把队列和消息都标记为持久化的。
首先,我们必须确保RabbitMQ不丢失我们的消息队列,为了达到这个目的,我们把队列声明为持久化的。
amqp_channel:call(Channel, #'queue.declare'{queue = <<"task_queue">>,
durable = true}),
注意: 如果已经把一个队列声明为非持久化了,则不能再次把同一个队列声明为持久化。RabbitMQ不允许你使用不同的参数重新定义一个已经存在的消息队列,如果你这么做,RabbitMQ就会返回一个错误。但是你可以声明一个新的队列。
现在我们需要把消息标志位持久化: 通过提供参数delivery_mode 赋值为2来实现这个目的:
amqp_channel:cast(Channel,
#'basic.publish'{
exchange = <<"">>,
routing_key = <<"task_queue">>},
#amqp_msg{props = #'P_basic'{delivery_mode = 2},

Fair dispatch (公平分发)
默认情况下, RabbitMQ是给消费者平均地分配消息,并不关心每个消费者还有多少消息没有回发确认消息(表示它已经处理完成)。
这就存在一个问题,可能有的消费者分配到的任务都是耗时很短的,而另外一些消费者分配到的任务都是耗时很长的,这就导致有的消费者处于空闲状态,而有的消费者则一直处于忙碌状态。

为了避免这个问题,我们可以使用 prefetch_count=1 这个配置项。这个配置项告诉RabbitMQ每次只给消费者分配一个消息,直到收到这个消息的确认,再给这个消费者分配下一个消息:
amqp_channel:call(Channel, #'basic.qos'{prefetch_count = 1}),
完整代码:
new_task.erl
-module(new_task).
-export([test/1]).
-include_lib("amqp_client/include/amqp_client.hrl").
test(Argv) ->
{ok, Connection} =
amqp_connection:start(#amqp_params_network{host = "localhost"}),
{ok, Channel} = amqp_connection:open_channel(Connection),
%% durable=ture : 把队列声明为持久化
amqp_channel:call(Channel, #'queue.declare'{queue = <<"task_queue">>,
durable = true}),
Message = case Argv of
[] -> <<"Hello World!">>;
Msg -> list_to_binary(string:join(Msg, " "))
end,
%% delivery_mode=2: 把消息声明为持久化
amqp_channel:cast(Channel,
#'basic.publish'{
exchange = <<"">>,
routing_key = <<"task_queue">>},
#amqp_msg{props = #'P_basic'{delivery_mode = 2},
payload = Message}),
io:format(" [x] Sent ~p~n", [Message]),
ok = amqp_channel:close(Channel),
ok = amqp_connection:close(Connection),
ok.
worker.erl
-module(worker).
-compile([export_all]).
-include_lib("amqp_client/include/amqp_client.hrl").
test(_) ->
{ok, Connection} =
amqp_connection:start(#amqp_params_network{host = "localhost"}),
{ok, Channel} = amqp_connection:open_channel(Connection),
amqp_channel:call(Channel, #'queue.declare'{queue = <<"task_queue">>,
durable = true}),
io:format(" [*] Waiting for messages. To exit press CTRL+C~n"),
%% prefetch_count=1:告诉RabbitMQ每次只给消费者分配一个消息,直到
%% 收到这个消息的确认,再给这个消费者分配下一个消息
amqp_channel:call(Channel, #'basic.qos'{prefetch_count = 1}),
amqp_channel:subscribe(Channel, #'basic.consume'{queue = <<"task_queue">>},
self()),
receive
#'basic.consume_ok'{} -> ok
end,
loop(Channel).
loop(Channel) ->
receive
{#'basic.deliver'{delivery_tag = Tag}, #amqp_msg{payload = Body}} ->
Dots = length([C || C <- binary_to_list(Body), C == $.]),
io:format(" [x] Received ~p~n", [Body]),
receive
after
Dots*1000 -> ok
end,
io:format(" [x] Done~n"),
amqp_channel:cast(Channel, #'basic.ack'{delivery_tag = Tag}),
loop(Channel)
end.