对lucene 的打分公式的个人理解
内容集合了多个 博文和ppt
lucene的评分公式如下:
![]()
一 概念:
1、Token:倒排表最小单位,即分词中 词。
2、Term:query的最小单位
3、Tf:一个term在一个文档中出现的次数
4、Idf:一个term在多少个文档中出现过
二 向量空间模型的计算
1、余弦定理
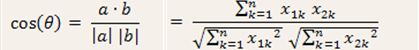
2、Vq为 query向量,Vd为document向量,经过分词之后成为 多个term,query与要搜索的document形成一个N维数量空间。
查询向量为Vq = <w(t1, q), w(t2, q), ……, w(tn, q)>
文档向量为Vd = <w(t1, d), w(t2, d), ……, w(tn, d)>
Term的权重: W=tf*idf,即表示 该Term在该 文档(query或者document)中的权重
因为,在query中,
则:
Vq*Vd = w(t1, q)*w(t1, d) + w(t2, q)*w(t2, d) + …… + w(tn ,q)*w(tn, d)
=tf(t1, q)*idf(t1, q)*tf(t1, d)*idf(t1, d) + …… + tf(tn,q)*idf(tn, q)*tf(tn, d)*idf(tn, d)
3、
因为,在 query中,不太可能分词后出现多个相同的term,假设这种情况成立,即tf(t,q)=1,
又因为 query与 要搜索的多个document相比,词量实在太少。所以, idf(t,q)约等于idf(t,d)
Vq*Vd = tf(t1, d)*idf(t1, d)^2+......+ tf(tn, d)*idf(tn, d)^2
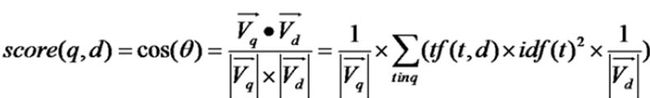
4、接着,我们就开始 计算向量模了,即 V
Lucene采用的Similarity,认为在计算文档(document)的向量长度的时候,每个Term的权重(W=tf*idf)就不再考虑在内了,而是全部为一.如果按权重去计算的话,因为
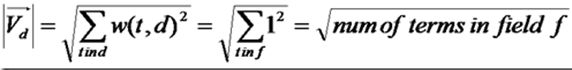
查询语句中tf都为1,idf查询语句这篇小文档 即idf(t,q) = idf(t,d),得到如下公式

代入余弦公式,即得到
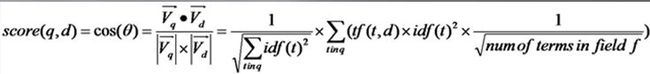
加上lucene自己的各种boost和coord
三、继续细分理解
1、协调因子 coord(q,d)

overlap(命中查询个数)
maxOverlap(总查询个数)
搜索语句为: 图书名称:”红楼梦” || 作者:”红楼梦”
doc1: 图书名称:红楼梦 作者:曹雪芹 coord(q,d) = 1/2,查询了两个域,命中了一个
doc2: 图书名称: 红楼梦 作者:红楼梦编委 coord(q,d) 2/2 (高),查询了两个域,命中了两个
queryNorm(q) = 1/(q.getBoost()^2·∑( idf(t)·t.getBoost() )^2)

3.文档词频因子 tf(t in d)
tf(t in d) = Math.sqrt(freq)

例如 搜索 图书名称:红楼梦
文档1:图书名称:红楼梦 tf=1
文档2:图书名称:红楼梦曹雪芹签名版红楼梦 tf=1.414 (高,因为它在该一个文档中,出现一次)
4、文档出现频率因子 idf(t)
idf(t) = 1.0 + log(numDocs/(docFreq+1))

numDocs(总文档数)
docFreq(有几个文档中出现了查询的词)
例如搜索语句为:图书名称:“红楼梦” || 作者:“曹雪芹” 总文档数为1000
如果图书名称中包含图书名称“红楼梦”的文档数为100 idf= 2.0
作者名称中包含作者“曹雪芹”的文档数为10 idf= 3.0 (高)
5、查询权重t.getBoost

在solr中的写法为:itemName:红楼梦^10.0 itemDesc:红楼梦
6、标准化因子 norm(t,d)
norm(t,d) = doc.getBoost()· lengthNorm· ∏ f.getBoost() (注意:4.0以后没有了 doc.getBoost())
lengthNorm = 1.0 / Math.sqrt(numTerms)

doc.getBoost() (在每个文档上设置的权重)
f.getBoost() (在每个字段上设置的权重
lengthNorm = 1.0 / Math.sqrt(numTerms)
表示字段长度对打分的影响
例如:文档1:图书名称:红楼梦 lengthNorm = 1/1.7 (高)
文档2:图书名称: 红楼梦新刊第28期 = 1/3
四、将上面1-6部分细化的部分代入上面公式得到
score(q,d) = (overlap / maxOverlap )·(1/(q.getBoost()^2·∑( idf(t)·t.getBoost() )^2) ) · ∑( tf(t in d)·idf(t)^2·t.getBoost()· doc.getBoost()· lengthNorm· ∏ f.getBoost() )