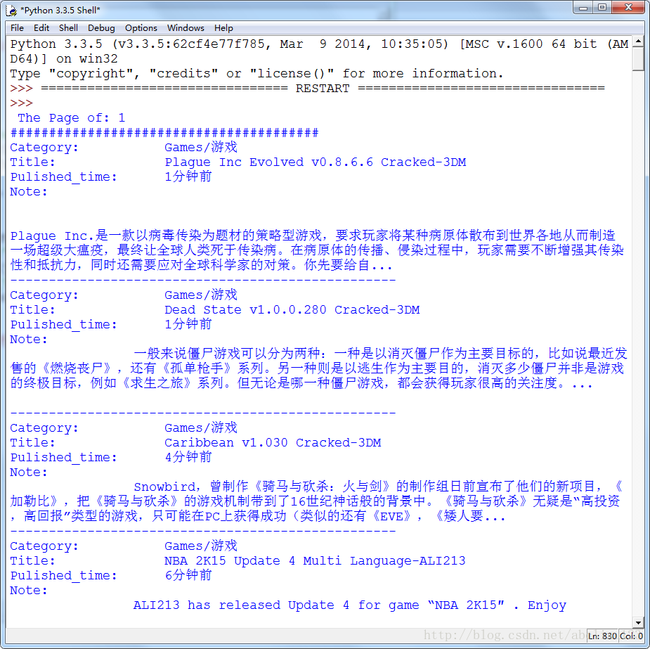
使用BeautifulSoup爬取“0daydown”网站的信息(1)
最近发现一个很好的网站,0daydown,资源真的是无时无刻的更新着。资源有哪些呢: windows,mac下的各种工具和软件。各种电子书,包含科技,小说,杂志(居然还有类似花花公子那种),可以看多国外的最新杂志。当然还有音乐,高清电影,还有各种外国最近的IT教程,但是这个百度云下载的话只有网站会员才行,不然只能使用其它链接。还有各个平台下的游戏,PC,Linux,XBOX,PS3等。资源种类真的可以用琳琅满目来形容,而且主要是更新真的很快,一天更新好多。
信息一多,慢慢翻麻烦耗时,而且不是所有信息都想关注。于是谋生了用爬虫爬取自己想要的信息。我目前想关注的信息只有资源类别(比如windows,game,Ebook等),资源标题,发布时间,资源的简介四个东西。看了下网页源码,有规律,解析不难。下面截图是网页截图和网页源码部分信息:
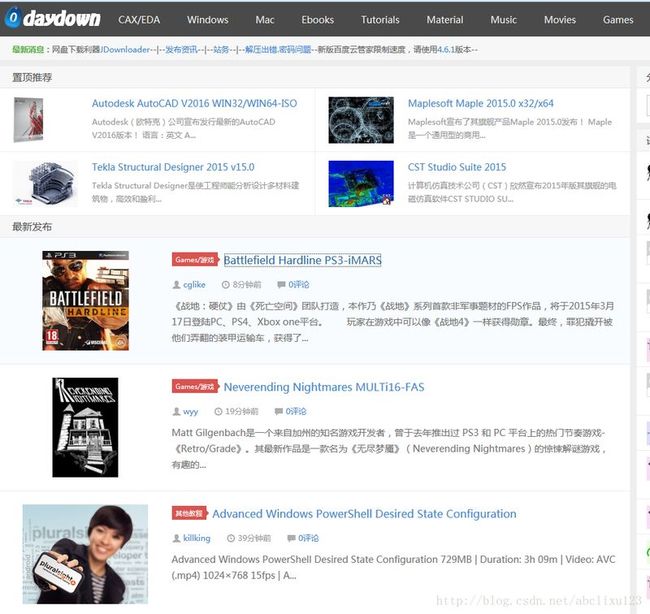
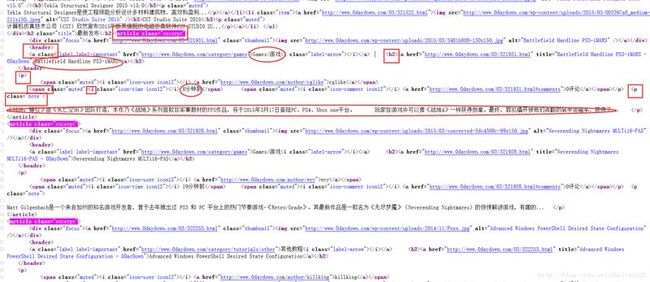
上图中
上图中椭圆圈出的是我想获得的信息,方块圈出的是一个找寻信息的逻辑。通过分析网页源码发现,所有的最新发布的每个资源都在一个article class="excerpt"段落中,我们可以使用find_all找出所有的个article class="excerpt",然后再在每个里面找寻想要的信息,比如资源类别,可以是article.header.a.next。资源标题是article.h2.string。发布时间是article.p.find('i', class_="icon-time icon12").next。资源简介是article.p.find_next_sibling().string。最后我想获取的是最新发布的10页资源信息,可以用循环实现,因为每个页面的Url很简单,只需在http://www.0daydown.com/page/后面添加页数。比如第二页就是http://www.0daydown.com/page/2.下面是源代码,用BeautifulSoup实现真的超级方便,可能以后会进行拓展,所以当前版本为0.1。
#coding:utf-8
#version: 0.1
#note:实现了查找0daydown最新发布的10页资源。
import urllib.request
from bs4 import BeautifulSoup
for i in range(1,11):
url = "http://www.0daydown.com/page/" + str(i) #每一页的Url只需在后面加上整数就行
page = urllib.request.urlopen(url)
soup_packtpage = BeautifulSoup(page)
page.close()
num = " The Page of: " + str(i) #标注当前资源属于第几页
print(num)
print("#"*40)
for article in soup_packtpage.find_all('article', class_="excerpt"): #使用find_all查找出当前页面发布的所有最新资源
print("Category:".ljust(20), end=''), print(article.header.a.next) #category
print("Title:".ljust(20), end=''), print(article.h2.string) #title
print("Pulished_time:".ljust(19), end=''), print(article.p.find('i', class_="icon-time icon12").next) #published_time
print("Note:",end=''), print(article.p.find_next_sibling().string) #note
print('-'*50)
input() #等待输入,为了不让控制台运行后立即结束。
下面是运行成功效果图: