网络爬虫
一、首先你要知道什么是抓包
抓包就是将网络传输发送与接收的数据包进行截获、重发、编辑、转存等操作,也用来检查网络安全,但往往被某些无耻之徒用来网游作弊。
这是我大三上学期通过抓包做的小型教务系统--La吧(喇叭),可以查成绩,查所有班级的课表,公告栏,机构通知,图书馆查询书籍,查询借书情况、意见反馈等等的功能。后台数据通过Bmob移动后端云服务进行数据存储。
下面就让我通过我做的小项目进行阐述如何抓包吧。
二、你所需要的工具
抓取数据的分析工具有很多,不同浏览器也自带很多开发人员工具,如果你的是IE内核的浏览器的话,比如360安全浏览器,你可以安装一个HttpWatch,相对web开发的人员来说对这个工具很熟悉,HttpWatch是一款强大的网页数据分析工具。集成在Internet Explorer工具栏。包括网页摘要。Cookies管理。缓存管理。消息头发送/接受。字符查询。
如果你的是Firefox火狐浏览器的话,恭喜你,它里面自带了一个比较好用的工具firebug,它的功能是和HttpWatch差不多,区别不大,我就是用Firefox自带的工具进行抓包分析的。
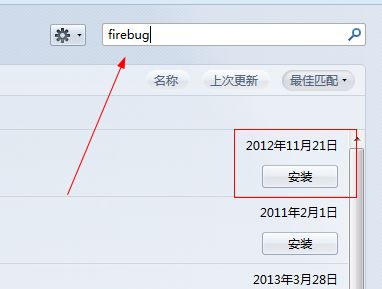
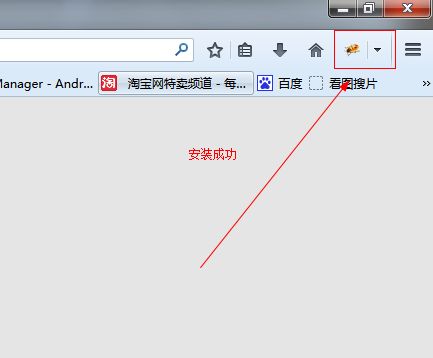
下面就让我用图片展示firebug的安装吧:

三、你最关心的代码实现。
我做的作品是通过抓取我校(广东石油化工学院)的教务系统的数据进行分析和操作的,看到图片上的我画的,诶,是不是真是你想做和抓取的呀?
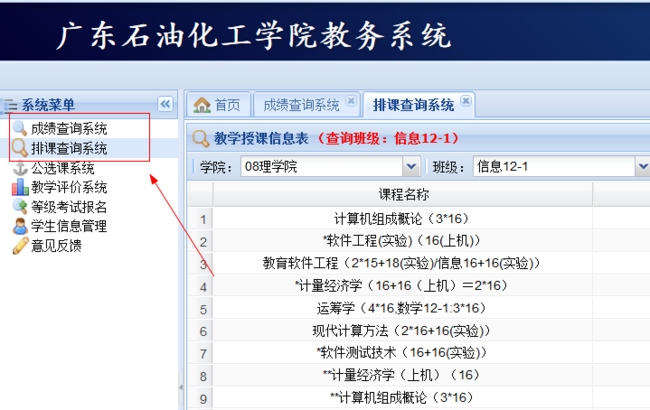
好了,现在要用的firebug终于到场了,我们点击浏览器小虫子的图标,或者直接按下F12快捷键,便出现这个页面,这个页面正是我们所需要的抓包分析页面。
有木有很激动,看到数据了没有?这些数据正是我们所需要的抓取的数据。
但是问题来了。我是先登录才能到这个页面的啊。
其实我们登陆时是通过cookie进行验证的,如果返回的cookie不为null,那么则是登陆成功
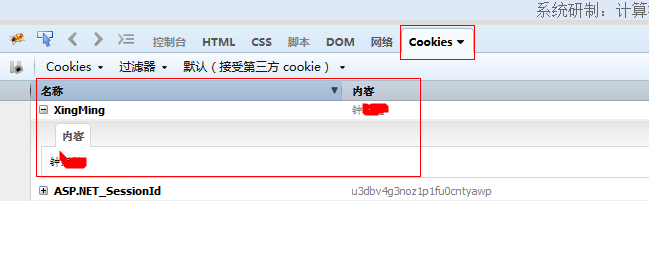
那么问题来了。我要怎么才能到到cookie了。cookie其实就相当于我们的身份证一样,里面有唯一的信息。不多说,直接上代码:
?
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
|
/**
* 登录时得到cookie
* @param xueHao 学号,即是登陆账号
* @param password 登陆密码
* @return
*/
public
List<Cookie> getCookie(String xueHao,String password) {
List<Cookie> cookies =
null
;
// 保存获取的cookie
try
{
HttpClient client =
new
DefaultHttpClient();
String uriAPI =
"http://218.15.22.136:3008/"
;
HttpPost httpPost =
new
HttpPost(uriAPI);
List<NameValuePair> params =
new
ArrayList<NameValuePair>();
params.add(
new
BasicNameValuePair(
"Window1$SimpleForm1$rdl_shenFen"
,
"学生"
));
params.add(
new
BasicNameValuePair(
"Window1$SimpleForm1$tbx_XueHao"
,
xueHao));
params.add(
new
BasicNameValuePair(
"Window1$SimpleForm1$tbx_pwd"
,
password));
params.add(
new
BasicNameValuePair(
"Window1_Collapsed"
,
"false"
));
params.add(
new
BasicNameValuePair(
"Window1_Hidden"
,
"false"
));
params.add(
new
BasicNameValuePair(
"Window1_SimpleForm1_Collapsed"
,
"false"
));
params.add(
new
BasicNameValuePair(
"X_AJAX"
,
"true"
));
params.add(
new
BasicNameValuePair(
"X_CHANGED"
,
"true"
));
params.add(
new
BasicNameValuePair(
"X_STATE"
,
"e30="
));
params.add(
new
BasicNameValuePair(
"X_TARGET"
,
"Window1_Toolbar1_btn_login"
));
params.add(
new
BasicNameValuePair(
"__EVENTARGUMENT"
,
""
));
params.add(
new
BasicNameValuePair(
"__EVENTTARGET"
,
"Window1$Toolbar1$btn_login"
));
// 发出HTTP request
httpPost.setEntity(
new
UrlEncodedFormEntity(params, HTTP.UTF_8));
// 取得HTTP response
HttpResponse httpResponse = client.execute(httpPost);
// 执行
// 若状态码为200 ok
if
(httpResponse.getStatusLine().getStatusCode() ==
200
) {
// 返回值正常
// 获取返回的cookie
cookies = ((AbstractHttpClient) client).getCookieStore()
.getCookies();
//System.out.println("cookies=" + cookies);
if
(cookies.isEmpty())
System.out.println(
"cookies empty"
);
}
else
{
}
}
catch
(Exception e) {
System.out.println(
"getCookie error:"
+ e);
}
return
cookies;
}
|
你会问params.add(new BasicNameValuePair("X_AJAX", "true")) 这些东西是什么啊?别急!再看图 
怎么样?懂了吧?其实就是post传带的参数。
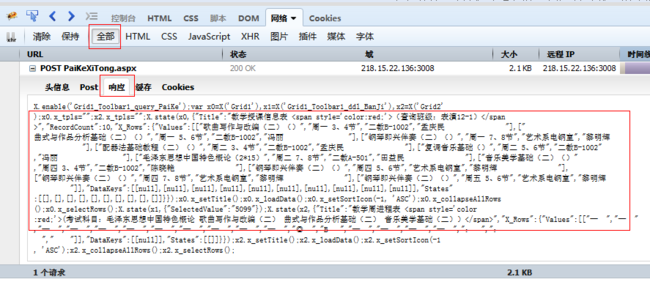
ok,进入系统之后,我们就要对自己感兴趣的数据进行抓取了,继续如图:
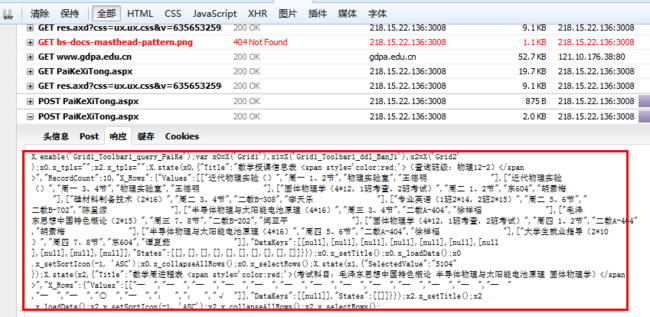
选择自己想要抓取的页面,点击cookies可以知道,我自己已经登陆,cookie不为空。点击响应可以看到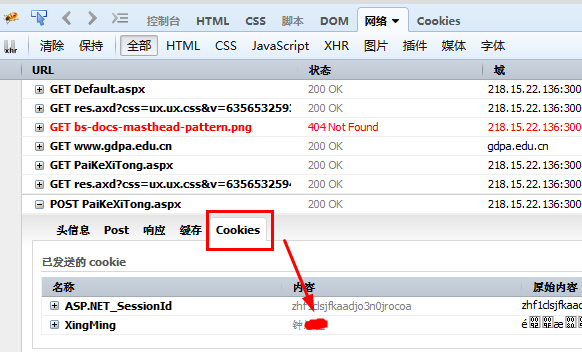
自己想要抓取的数据已经存在,不难发现自己想要数据部分是以json的形式显示出来的,现在就是得到这些数据进行分解抓取了。你会说,这个什么东西,我看不懂,看不懂没关系,你只要数据就行了,对于这响应的数据,其实是asp的格式而已,如果点击的网页时htmll的话,那么响应的便是html,同样是可以进行解析的。
那怎么得到这个页面呢,先看代码,再解释吧:
?
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
/**
* 得到成绩数据
*/
public
ArrayList<HashMap<String, Object>> getMyGrade(List<Cookie> cookies) {
String result =
null
;
ArrayList<HashMap<String, Object>> list =
null
;
String uriPath =
"http://218.15.22.136:3008/ChengJiChaXun.aspx"
;
try
{
HttpPost httpPost =
new
HttpPost(uriPath);
httpPost.setHeader(
"Cookie"
,
"ASP.NET_SessionId="
+ cookies.get(
0
).getValue() +
";XingMing="
+ cookies.get(
1
).getValue());
HttpResponse httpResponse =
new
DefaultHttpClient()
.execute(httpPost);
if
(httpResponse.getStatusLine().getStatusCode() ==
200
) {
result = EntityUtils.toString(httpResponse.getEntity());
if
(result !=
null
&& !result.isEmpty()) {
list =
new
ArrayList<HashMap<String, Object>>();
list = toGradeData(result);
}
}
}
catch
(ClientProtocolException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
catch
(IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return
list;
}
|
首先呢,你的得到你想要抓取的页面的地址,如http://218.15.22.136:3008/ChengJiChaXun.aspx,但是这仅仅是不够的,因为你要告诉系统的你的身份,不然谁都可以查分数了。没错,你要把cookie的内容传到系统中, httpPost.setHeader("Cookie", "ASP.NET_SessionId=" + cookies.get(0).getValue() + ";XingMing=" + cookies.get(1).getValue());让系统知道你是否有权限查询数据。不多说,看下图:
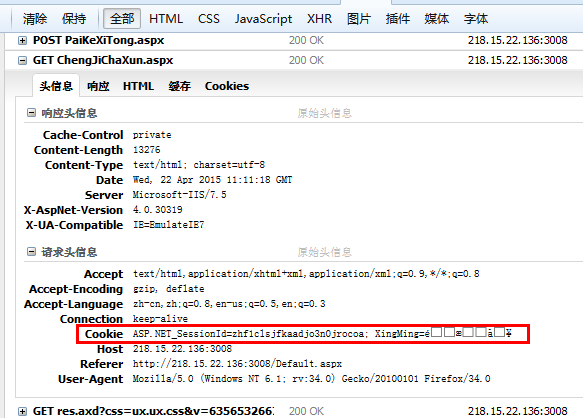
当然代码中的 list = toGradeData(result)你可能看不懂,这是我自己写的获取我需要的数据的方法,最后把数据装进ArrayList<HashMap<String,Object>>中返回,那么接下来,你应该知道怎么做了吧?和listview绑定,就可以把数据显示在手机界面了。如图:
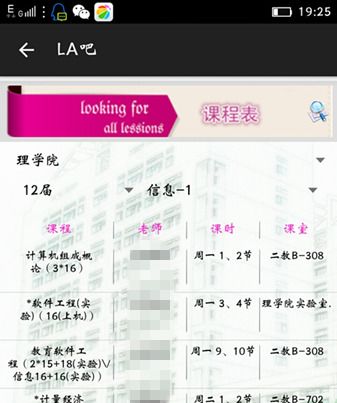
当然,我的项目做了消息通知,公告栏,机构通知,如图:

那么我是怎么做的呢?
在这里。我就得向大家介绍一个很好用的移动云服务器了。Bmob移动后端云服务,它是一个非常好用的免费的云数据库,我们做的项目如果不能联网获取数据那么这样的应用是没人用的,或者说是失败的,但是联网得到数据我们得有服务器啊,一般个人开发者是没有自己的服务器,特别是学生来说更是如此,但是,现在你不用担忧了,Bmob可以帮你搞定所有的繁琐的后台开发,而让你更有时间和精力去开发你的应用。
具体我不多说,免得以为我在打广告,如果自己感兴趣的话,可以到Bmob官网了解。
首先来看,上图的数据我并不是存在SQLite的,也不是存在文件中的,我是直接通过联网从我的云服务中得到的,一旦我的云服务器中的数据有改变,我下拉就可以得到最新消息。便可以做到类似新闻一样的消息通知了。
大家请看我后台的云端数据库

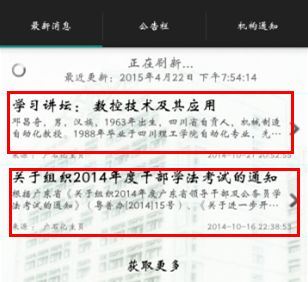
怎么样?不错吧?其实你看Bmob的文档,你会发现,其实这些都不难,代码说真的挺简单的。里面可以设置自己应用的的官网之类的一堆功能,建议都去看看吧,相信你们能做的更好更厉害。这个就是我在Bmob中下载我的应用的官网http://downloadlaba.bmob.cn
最后呢,希望我写的这些对你们有帮助吧,尊重原创,转发请写上原创地址。谢谢啦~如有疑问欢迎[email protected]