简单标签云的实现
标签云是数据可视化的有效方法。标签云中根据标签的衡量指标,呈现时设置不同的字体大小或者颜色来表达标签的重要性,能够方便的表达博客的关注点。
下面是我自己实现一个简单标签云的过程,在我的标签云中,实现了用不同的字体大小来表达标签被引用的次数。当然其实有很多现成的工具可以用,不过自己对于实现原理比较好奇,也就想自己实现个,最后效果是有了,也不知道是不是常规手段。
在开工的时候我考虑了这么个问题:标签的被引用次数我很容易得到,我只需要几个简单的SQL就可以统计出各标签的的使用次数,但是问题在于难道我的标签’Java’被引用了100次, 标签’切糕’ 仅仅被引用1次,在显示的时候就让’Java’比 ‘切糕’大一百倍?那切糕肯定不满意了,好歹切糕也很火啊。而且更实际的问题是,我们的页面在展示标签时的空间是有大小的,不可能任由字体任意大。
那么现在缕缕思路,实现标签云,我先要做下面的工作:
1、 统计出各标签的引用次数
2、 合理的显示标签大小
哦,前面忘记说了,基于标签云的实现,我的数据模型是这样的:1张Post表, 1张Tag表,还有一张 Post 和 Tag 的关联表
统计标签的引用次数
统计很简单,一句SQL就可以实现,我使用的Django,查询的话就这样:
tag_list = Tag.objects.annotate(num_post=Count('post_tag'))
合理显示标签大小
什么叫做合理呢?起码不能太大吧,起码也不能小的看不见吧。那么就只能规定一个取值的范围。
标签的引用次数可能会差别很大,如果直接用引用次数来作为最终标签的字体大小的话,也不是不可以,只不过有的字体会特别大,有的呢又特别小。
如果直接表示大小不行,那么我就是用倍数来表示。比如我只能接受最大的字体是最小字体的3倍,那么如何将差别很大的引用次数映射到 1 ~ 3 的范围之间呢?
首先来个假设,假设现在我有一组标签的引用次数 A = [1, 3, 5, 6, 10], 接下来的过程其实也就是找到一个合适的函数来完成这个映射。思路就是讲我们的数字逐步的往 [1, 3]上靠。
先找出 A 中的最大值 maxA, 然后将 A 中的每个数值除以 maxA, 结果也就是
A’ = [0.1, 0.3, 0.5, 0.6, 1], 现在已经成功的将值域缩小到 [0, 1] 之间,继续向 [1, 3] 上靠。
现在对于 A’ 中的每个数字n, 都满足 0 <= n <= 1, 不等式两边同时乘以 2,则取值范围变为 0 <= 2n <= 2, 再将不等式两边同时加上1则等于, 1 <= 2n + 1 < = 3。
现在我数组A中原来的引用次数已经转化为 [1, 3] 之间。但是这只是个特例,我还需要更通用的公式才能满足不同区间的需求。
根据上面的步骤,可以抽象为一下步骤
A’*x + y
假设目标区间是[L, U], 那么利用两个端点值,可以得到两个方程:
A’max * x + y = U
A’min * x + y = L
解方程组的:
x = ( U – L ) / (A’max – A’min) (注意分母为 0 的情况)
y = U – x
公式有了,接下来实现就方便了。再用前面的例子 A = [1, 3, 5, 6, 10] 来总结下计算过程:
1、 A中每个元素除以 A中最大值 的A’ [0.1, 0.3, 0.5, 0.6, 1]
2、 求出A’ 中最大最小值 A’max, A’min
3、 运用公式 x = ( U – L ) / (A’max – A’min) , y = U – x 计算两个变量x, y 的值
4、 对 A’ 中每个元素运用公式 A’*x + y 计算换算后的倍数 M
通过上面步骤, A = [1, 3, 5, 6, 10] 计算结果为 M = [1.0,1.2,1.4,1.8,2.1,3.0]
有了M 在前端展示的时候就可以设置style时使用 “font-size: M em;” 来设置字体大小了
我的Python实现如下:
# coding=utf-8
from tumblelog.tumbleutils import TumbleLogUtils
class TagCloud(object):
''' 根据标签被引用次数计算标签最终的显示的字号'''
def __init__(self, tag_list):
self.tag_list = tag_list
self.MAX_FONT_RATE = 3.0
self.MIN_FONT_RATE = 1.0
def calculateTagFont(self):
maxE = self.maxElement()
minE = self.minElement()
normalizegList = self.normalize(maxE)
targetList = []
x = self.getBootFactor(maxE, minE)
y = self.getOffset(maxE, minE)
colorUtil = TumbleLogUtils() #一个工具类, 主要用于生成随机颜色
for i in range(0, len(normalizegList)):
normalizegList[i].num_post = normalizegList[i].num_post * x + y
normalizegList[i].color = colorUtil.getRandomColor()
targetList.append(normalizegList[i])
return targetList
def normalize(self, maxE):
''' 预处理标签引用次数, 将标签次数的值域缩小到[0,1]'''
# 只有最大值非零时才进行此操作
if maxE:
for i in xrange(0, len(self.tag_list)):
self.tag_list[i].num_post = self.tag_list[i].num_post / maxE
return self.tag_list
def getBootFactor(self, maxE, minE):
''' 计算公式中的系数 x, 如果最大最小值相等, 就返回0, 否则返回按公式的计算结果'''
if not maxE - minE:
return 0
return (self.MAX_FONT_RATE - self.MIN_FONT_RATE) / (maxE - minE) * maxE
def getOffset(self, maxE, minE):
''' 计算公式中的系数 y, 如果最大最小值相等, 就返回1, 否则返回按公式的计算结果'''
if not maxE - minE:
return 1
return self.MAX_FONT_RATE - self.getBootFactor(maxE, minE)
def maxElement(self):
tmpTags = self.tag_list.order_by('-num_post')
return float(tmpTags[0].num_post)
def minElement(self):
tmpTags = self.tag_list.order_by('-num_post')
return float(tmpTags[len(tmpTags) - 1].num_post) 对应的模版中的代码
{% for tag in tag_list%}
<font style="font-size: {{tag.num_post}}em;"><a href="/tag/{{ tag.slug }}" id="{{tag.slug}}" style="color:{{tag.color}}">{{ tag.title }}</a></font>
{% endfor %} 效果图
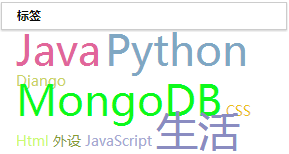
演示地址: hellofalcon.com
拓展思考:
1、除了用标签的引用次数来计算,还可以自己给标签一些权重,这样的话需要对公式进行调整。
2、复杂的标签云,类似下面这样的还不知道怎么弄。