CentOS6.5 hadoop2.4.0 HA 集群自动切换模式安装教程
Hadoop 中的NameNode 好比是人的心脏,非常重要,绝对不可以停止工作。在hadoop1 时代,只有一个NameNode。如果该NameNode 数据丢失或者不能工作,那么整个集群就不能恢复了。这是hadoop1 中的单点问题,也是hadoop1 不可靠的表现。hadoop2 就解决了这个问题。
hadoop2.2.0 中HDFS 的高可靠指的是可以同时启动2 个NameNode。其中一个处于工作状态,另一个处于随时待命状态。这样,当一个NameNode所在的服务器宕机时,可以在数据不丢失的情况下,手工或者自动切换到另一个NameNode 提供服务。这些NameNode 之间通过共享数据,保证数据的状态一致。多个NameNode 之间共享数据,可以通过Nnetwork File System 或者Quorum Journal Node。前者是通过linux 共享的文件系统,属于操作系统的配置;后者是hadoop 自身的东西,属于软件的配置。我们这里讲述使用Quorum Journal Node 的配置方式,方式是自动切换。
集群启动时,可以同时启动2 个NameNode。这些NameNode 只有一个是active 的,另一个属于standby 状态。active 状态意味着提供服务,standby状态意味着处于休眠状态,只进行数据同步,时刻准备着提供服务。
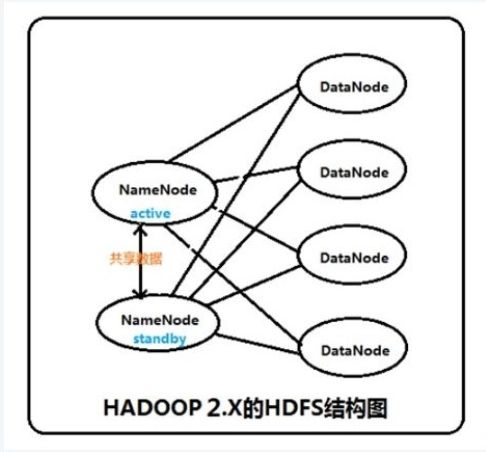
架构
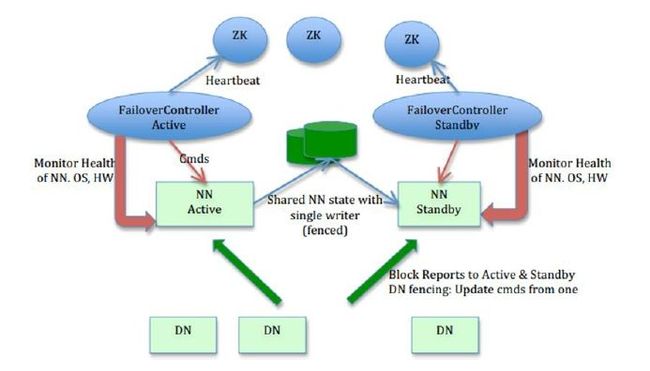
在一个典型的HA 集群中,每个NameNode 是一台独立的服务器。在任一时刻,只有一个NameNode 处于active 状态,另一个处于standby 状态。其中,active 状态的NameNode 负责所有的客户端操作,standby 状态的NameNode 处于从属地位,维护着数据状态,随时准备切换。
两个NameNode 为了数据同步,会通过一组称作JournalNodes 的独立进程进行相互通信。当active 状态的NameNode 的命名空间有任何修改时,会告知大部分的JournalNodes 进程。standby 状态的NameNode 有能力读取JNs 中的变更信息,并且一直监控edit log 的变化,把变化应用于自己的命名空间。standby 可以确保在集群出错时,命名空间状态已经完全同步了。
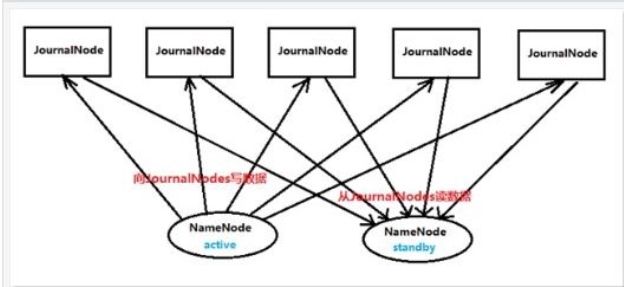
为了确保快速切换,standby 状态的NameNode 有必要知道集群中所有数据块的位置。为了做到这点,所有的datanodes 必须配置两个NameNode 的地址,发送数据块位置信息和心跳给他们两个。
对于HA 集群而言,确保同一时刻只有一NameNode 处于active 状态是至关重要的。否则,两个NameNode 的数据状态就会产生分歧,可能丢失数据,或者产生错误的结果。为了保证这点,JNs 必须确保同一时刻只有一个NameNode 可以向自己写数据。
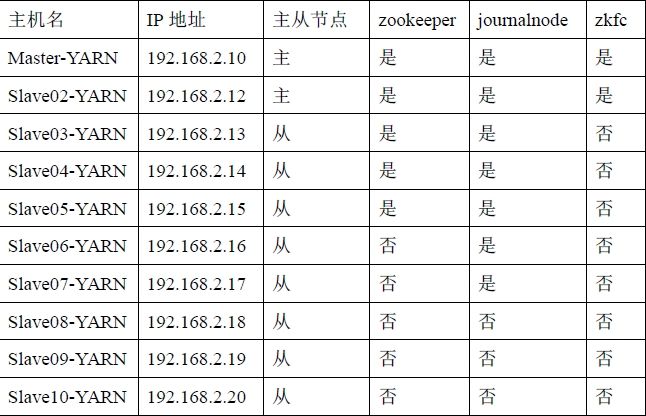
在学校服务器上配置了十台虚拟机,具体配置如下:
所用的软件: hadoop-2.4.0.tar.gz jdk-8u5-linux-i586.tar.gz、zookeeper-3.4.5.tar.gz hbase-0.16.2.hadoop2-bin.tar.gz
eclipse-standard-luna-R-linux-gtk.tar.gz 、hadoop-eclipse-plugin-2.4.0.jar
虚拟机系统采用CentOS6.5 32 位操作系统。虚拟机的安装,主机名,网络IP 地址等的设置,以及SSH 的安装、jdk 的安装
详见细细品味教程即可。
所有配置目录均在/usr 目录下,比如:/usr/java /usr/hadoop /usr/zookeeper/usr/hbase
第一步骤:jdk 的安装补充。
按照细细品味教程进行jdk 的解压,环境变量的配置后,需要修改默认的jdk 版本,我们需要把自己安装的jdk 设置为默认的jdk 版本,具体代码如下:
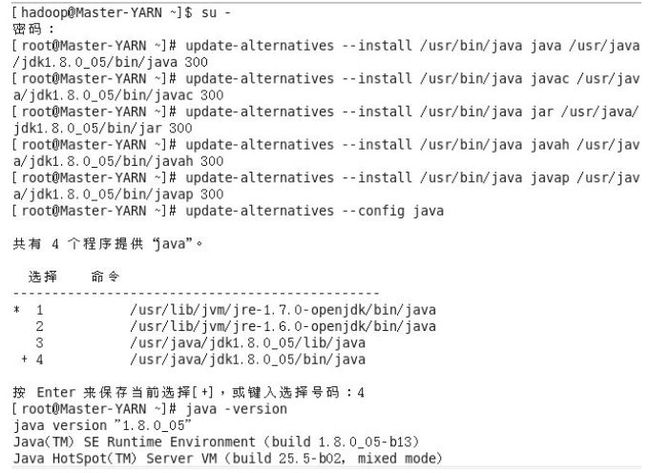
上图在输入updata-alternatives --config java 指令后,正常情况下会出现3 个可选项,上图由于第一次配置失误出现/usr/java/jdk1.8.0_05/lib/java,而我们要选择的是.../bin/java,因此输入4,自己按照自己的实际情况输入数字即可。当输入java-version 指令后出现最后3 行形式时说明配置成功。其他结点也是一样。
第二步骤:zookeeper 的配置。(奇数个节点)
将下载的软件拷入到/usr 目录下,如从桌面下复制,命令如下:(root 权限下)
cp /home/hadoop/桌面/zookeeper-3.4.5.tar.gz /usr
进入/usr 目录下,解压压缩包,重命名文件名,删除软件包:
cd /usr
tar -zxvf zookeeper-3.4.5.tar.gz
mv zookeeper-3.4.5 zookeeper
rm -rf zookeeper-3.4.5.tar.gz
修改文件所有者及用户组权限:(root 权限)
chown -R hadoop:hadoop zookeeper
注:以下hadoop 以及hbase 的解压过程如上,只需要修改文件名即可,下面不再重复。
配置环境变量:(root 权限下)
vim /etc/profile

source /etc/profile 使之生效,root 和普通用户权限下均要执行。
注:所有环境变量的设置均在此设置,设置完成后使之生效,下面涉及此文件的操作只给出配置内容,步骤不再重复。
配置zookeeper-3.4.5/conf/zoo.cfg 文件, 这个文件本身是没有的, 有个zoo_sample.cfg 模板
cd /usr/zookeeper/conf 进入conf 目录
cp zoo_sample.cfg zoo.cfg 拷贝模板
vim zoo.cfg
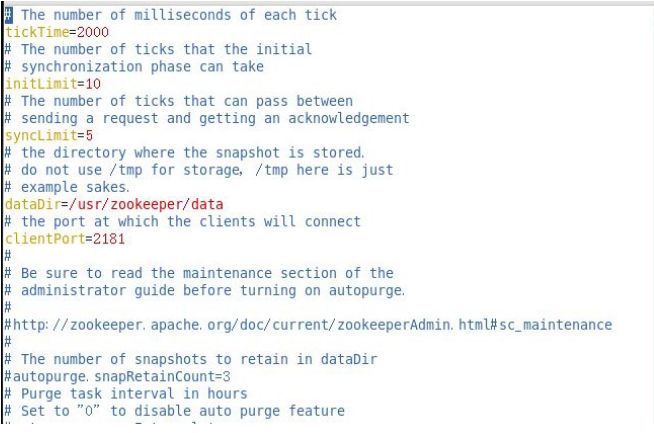
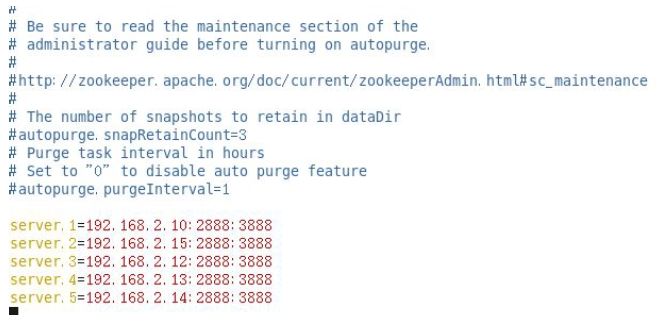
把zookeeper 集群的IP 地址以及端口号添加进来,按照自己的实际配置情况进行配置。
创建dataDir 参数指定的目录,创建data 文件夹,在这个文件夹下,还要创建一个文本myid
cd /usr/zookeeper
mkdir data 创建data
cd /usr/zookeepe/data 进入data 文件夹下
vim myid 创建文本myid , 在这个文本内写入1 , 因为
server.1=192.168.2.10:2888:3888 server 指定的是1,192.168.2.15 下面的myid 是2,192.168.2.12 下面myid 是3,192.168.2.13 下面myid 是4,192.168.2.14 下面myid
是5,这些都是根据server 来的。
通过scp -r /usr/zookeeper [email protected]:/usr 给其他节点复制过去,并进行环境变量设置,以及按照上面说的myid 号修改自身的id 号。启动zookeeper,在hadoop 启动之前启动启动命令为:zkServer.sh start 记住是每个配置zookeeper 的节点都需要执行该命令。
执行完启动命令,可执行zkServer.sh status,也是每个节点单独执行,查看选举结果,正常情况下有一个节点是leader,其余为follower


第三步骤,安装hadoop,每个节点都需要安装。
同样也需要解压等一系列准备工作,这里不再重复讲解,只给出具体配置文件配置过程。
配置之前需要新建几个文件夹:
~/dfs/name
~/dfs/data
~/tmp/journal
涉及的配置文件有7 个,分别是/usr/hadoop/etc/hadoop 文件夹下的hadoop-env.sh、yarn-env.sh、slaves core-site.xml、 hdfs-site.xml、 mapred-site.xml 、yarn-site.xml其中mapred-site.xml 不存在
cd /usr/hadoop/etc/hadoop 进入到hadoop 配置文件的目录中
cp mapred-site.xml.template mapred-site.xml 复制相应的模板文件
配置hadoop-env.sh


配置yarn-env.sh
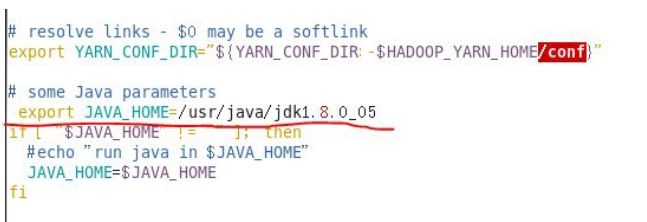
配置slaves,写入从节点信息
![]()

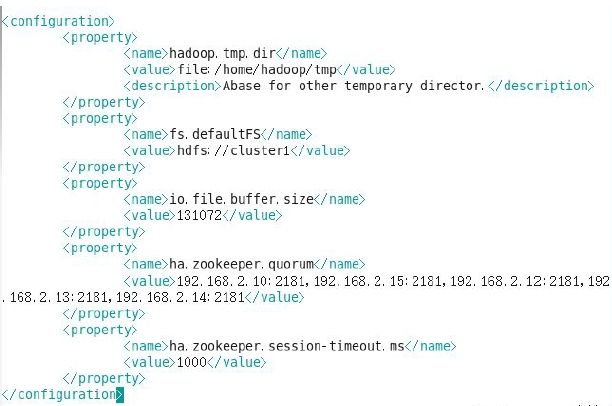
配置core-site.xml
![]()
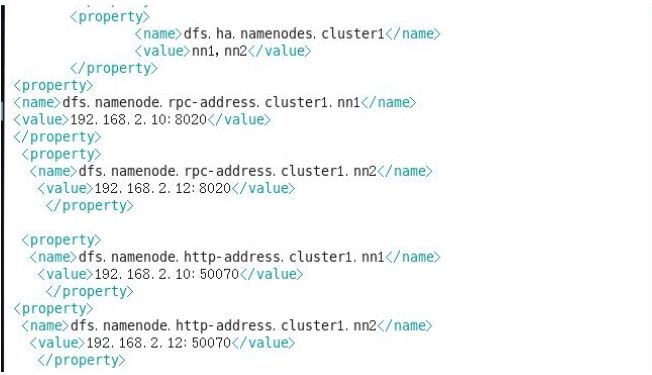
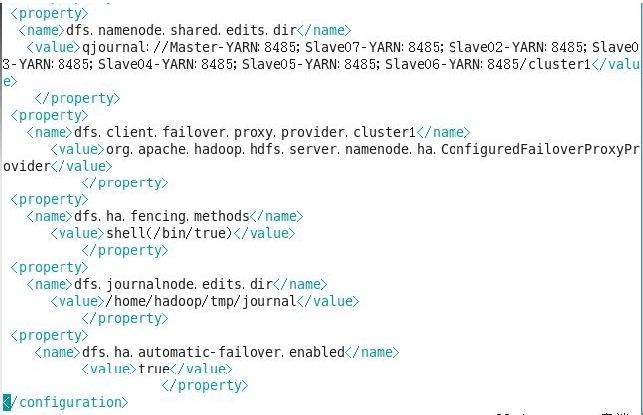
配置hdfs-site.xml
![]()

注:上图中第九行 “ty>”由于截图时格式乱了,不过大家应该看得出来应该是</property>,都是成对出现的。
配置mapred-site.xml
![]()

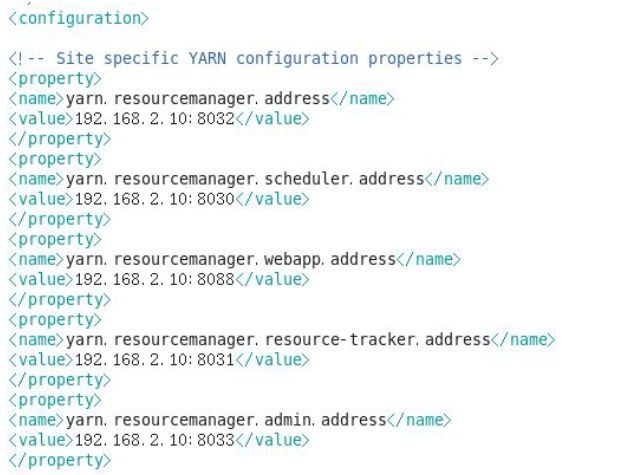
配置yarn-site.xml
![]()

配置/etc/profile 文件环境变量:

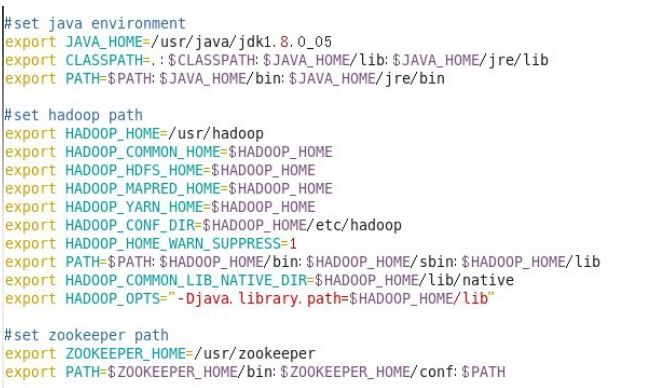
此处只需设置hadoop path 即可。别忘source /etc/profile 使之生效。通过scp 命令复制给其他节点,此处不再重复,复制结束后检查一下是否文件的用户组都是hadoop:hadoop 形式,如若不是需要用chown -R hadoop:hadoop 文件名 进行修改。
启动hadoop
0、首先把各个zookeeper 起来,如果zookeeper 集群还没有启动的话。
zkServer.sh start 记住每台机子都要启动
1、然后在某一个namenode 节点执行如下命令,创建命名空间
hdfs zkfc -formatZK
2、在每个节点用如下命令启日志程序
hadoop-daemon.sh start journalnode
3 、在主namenode 节点用./bin/hadoopnamenode -format 格式化namenode 和journalnode 目录
hadoop namenode -format mycluster
4、在主namenode 节点启动./sbin/hadoop-daemon.shstart namenode 进程
hadoop-daemon.sh start namenode
5、在备节点执行第一行命令,这个是把备namenode 节点的目录格式化并把元数据从主namenode 节点copy 过来,并且这个命令不会把journalnode 目录再格式化了!然后用第二个命令启动备namenode 进程!
hdfs namenode –bootstrapStandby
hadoop-daemon.sh start namenode
6、在两个namenode 节点都执行以下命令
hadoop-daemon.sh start zkfc
7、在所有datanode 节点都执行以下命令启动datanode
hadoop-daemon.sh start datanode
以后执行时,可以按照上述步骤进行,也可以在zookeeper 启动后通过start-all.sh全部启动。
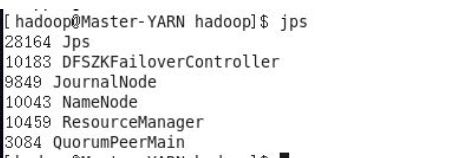
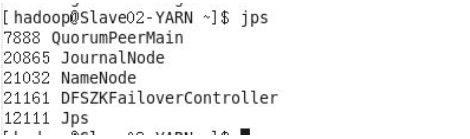

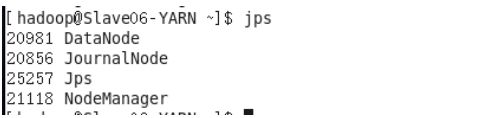

所有节点都按照文章一开始表格内容打开浏览器浏览如下:
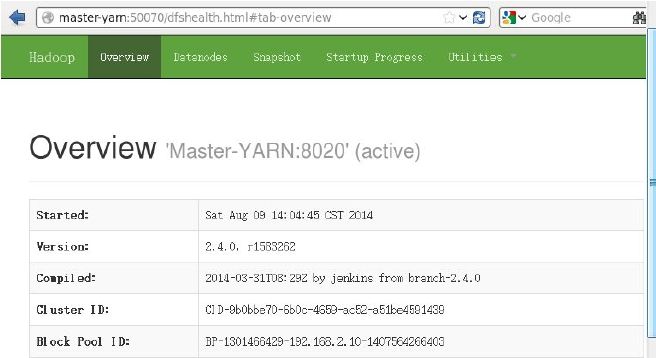
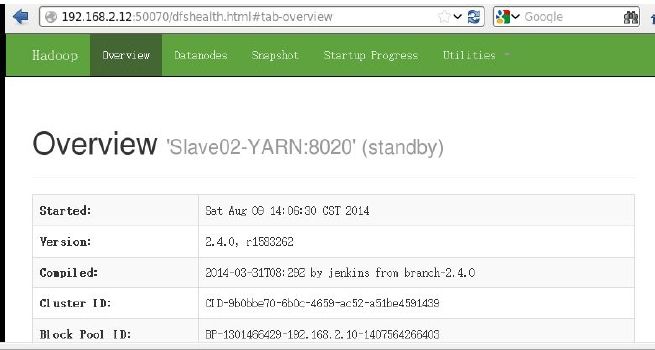
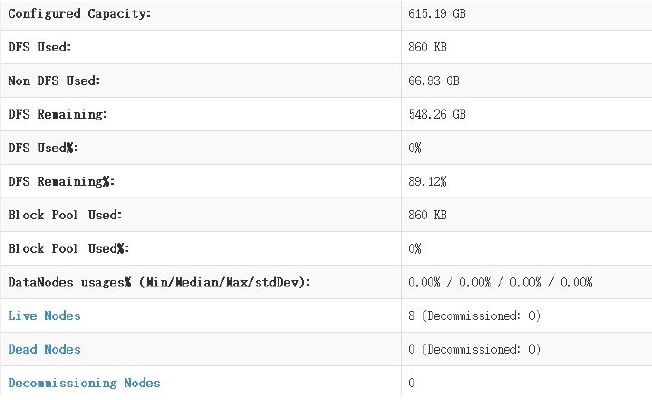
安装成功,可以关掉active状态的namenode,通过浏览器观察两个namenode间状态的切换。
我也是刚入门的小菜鸟,如安装教程与错误之处,还望高手不吝赐教。