Play 2.0 用户指南 - 访问SQL数据库 -- 针对Scala开发者
配置JDBC连接池
Play 2.0 提供了一个内置插件来管理连接池。你可以配置多个数据库。
为了使用数据库插件,在conf/application文件中配置连接池。依照惯例,默认的JDBC数据源命名为 default:
# Default database configuration db.default.driver=org.h2.Driver db.default.url=jdbc:h2:mem:play
配置多个数据源
# Orders database db.orders.driver=org.h2.Driver db.orders.url=jdbc:h2:mem:orders # Customers database db.customers.driver=org.h2.Driver db.customers.url=jdbc:h2:mem:customers
如果发生任何配置错误,你將会在浏览器中直接看到:
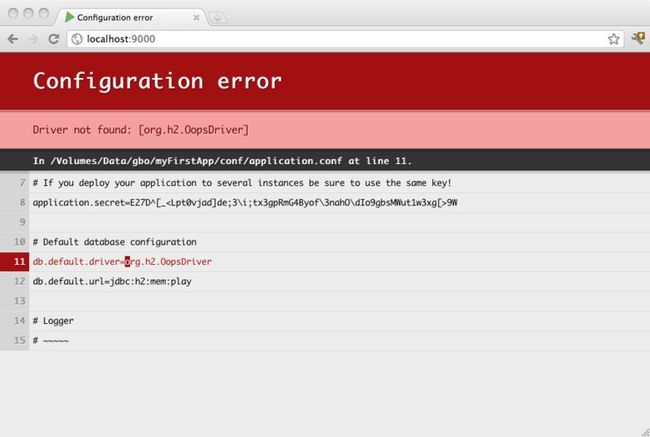
配置JDBC驱动
除了H2这种内存数据库,在开发环境下有用外,Play 2.0 不提供任何的数据库驱动。因此,部署到生产环境中,你需要加入所需的驱动依赖。
例如,你如果使用MySQL5,你需要为connector加入依赖:
val appDependencies = Seq( "mysql" % "mysql-connector -java" % "5.1.18" )
访问JDBC数据源
play.api.db 包提供了访问配置数据源的方法:
import play.api.db._ val ds = DB.getDatasource()
获取JDBC连接
有几种方式可获取JDBC连接,如第一种最常使用的:val connection = DB.getConnection()
但是,你需要在某个地方调用close方法关闭连接。另一种方式是让Play自动管理连接:
DB.withConnection { conn =>
// do whatever you need with the connection
}
该连接將会在代码块结束后自动关闭。
提示:每个被该连接创建的Statement and ResultSet也都会被关闭。
一个变种方式是將auto-commit设为false,并在代码块中管理事务:
DB.withTransaction { conn =>
// do whatever you need with the connection
}
Anorm, 简单的SQL数据访问层
Play包括了一个轻量的数据访问层,它使用旧的SQL与数据库交互,并提供了一个API解析转换数据结果集。
Anorm不是一个ORM工具
接下来的文档中,我们將使用MySQL做为示例数据库。
如果你想使用它,依照MySQL网站的介绍,并將下列代码加入conf/application.conf中:
db.default.driver= com.mysql.jdbc.Driver db.default.url="jdbc:mysql://localhost/world" db.default.user=root db.default.password=secret
概述
现如今,退回到使用纯SQL访问数据库会让人感觉很奇怪,特别是对于那些习惯使用如Hibernate这类完全隐藏底层细节的ORM工具的Java开发者。
尽管我们同意这类工具使用Java开发几乎是必须的,但我们也认为借助像Scala这类强大的高阶语言,它就不那么迫切了。相反,ORM工具可能会适得其反。
使用JDBC是痛苦的,但我们提供了更友好的API
我们同意使用纯JDBC很糟糕,特别是在Java中。你不得不四处处理异常检查,一遍又一遍的迭代ResultSet来將原始的行数据转成自定义结构。
我们提供了比JDBC更简单的API;使用Scala,你不再四处与异常为伴,函数式特性使得转换数据也异常简单。事实上,Play Scala SQL层的目标就是提供一些將JDBC数据转换成
Scala结构的API。
你不需要另一种DSL语言访问关系数据库
SQL已经是访问关系数据库的最佳DSL。我们毋需自作聪明的搞发明创造。此外,SQL的语法和特性也使得不同的数据库厂商间存在差异。
如果你试图使用某种类SQL的DSL去抽象这些差异,那么你不得不提供多个针对不同数据库的代理(如Hibernate),这会限制你充分发挥特定数据库特性的能力。
Play 有时候会提供预编译SQL statement, 但并不是想隐藏SQL的底层细节. Play 只想节约大段查询的打字时间,你完全可以返回来使用纯的SQL.
通过类型安全的DSL生成SQL是错误的
存在一些争论的观点,认为使用类型安全的DSL更好,理由是你的查询可被编译器检查。不幸的是,编译器是基于你定义的元素据检查的,你通常都会自己编写自定义数据结构到数据库
数据的“映射”。
这种元素据正确性无法保证。即使编译器告诉你代码和查询是类型正确的,运行时依然会因为实际的数据库定义不匹配而惨遭失败。
全权掌控你的SQL代码
ORM工具在有限的用例中工具得很好,但当你需要处理复杂的数据库定义或已存在的数据库时,你將花费大量时间使得ORM工具为你产生正确的SQL代码。编写SQL查询你可能会认为像开发个“Hello World“那么乏味无趣,但任何真实的应用,你终將会通过完全的掌控SQL和编写简单的代码而节省时间。
执行SQL查询
你將通过学习怎样执行SQL查询起步。
首先导入 anorm._,然后使用简单的SQL对象创建查询。你需要一个连接来运行查询,你可以通过play.api.db.DB取得连接:
import anorm._
DB.withConnection { implicit c =>
val result: Boolean = SQL("Select 1").execute()
}
execute方法返回一个Boolean值标识查询是否成功。
为了执行更新,使用executeUpdate()方法,它將返回被更新的行数。
val result: Int = SQL("delete from City where id = 99").executeUpdate()
既然Scala支持多行字符串形式,你可以自由的编写复杂的SQL块:
val sqlQuery = SQL(
"""
select * from Country c
join CountryLanguage l on l.CountryCode = c.Code
where c.code = 'FRA';
"""
)
如果你的SQL查询需要动态参数,你可以在sql串中使用形如 {name}的声明,稍后给它赋值:
SQL(
"""
select * from Country c
join CountryLanguage l on l.CountryCode = c.Code
where c.code = {countryCode};
"""
).on("countryCode" -> "FRA")
使用Stream API检索数据
访问select查询结果的第一种方式是使用 Stream API。
当你在任何SQL结果集中调用 apply() 方法时,你將会获得一个懒加载的 Stream 或 Row 实例,它的每一行能像字典一样的查看:
// Create an SQL query
val selectCountries = SQL("Select * from Country")
// Transform the resulting Stream[Row] as a List[(String,String)]
val countries = selectCountries().map(row =>
row[String]("code") -> row[String]("name")
).toList
接下来的例子,我们將计算数据库中Country实体的数量,因此结果將是单行单列的:
// First retrieve the first row
val firstRow = SQL("Select count(*) as c from Country").apply().head
// Next get the content of the 'c' column as Long
val countryCount = firstRow[Long]("c")
使用模式匹配
你也可以使用模式匹配来匹配和提取 Row 内容。这种情况下,列名已无关紧要。仅仅使用顺序和参数类型来匹配。
下面的例子將每行数据转换成正确的Scala类型:
case class SmallCountry(name:String)
case class BigCountry(name:String)
case class France
val countries = SQL("Select name,population from Country")().collect {
case Row("France", _) => France()
case Row(name:String, pop:Int) if(pop > 1000000) => BigCountry(name)
case Row(name:String, _) => SmallCountry(name)
}
注意,既然 collect(...) 会忽略未定义函数,那它就允许你的代码安全的那些你不期望的行.
处理 Nullable 列
如果在数据库定义的列中可以包含 Null 值,你需要以Option类型操纵它。
例如,Country表的indepYear列可为空,那你就需要以Option[Int]匹配它:
SQL("Select name,indepYear from Country")().collect {
case Row(name:String, Some(year:Int)) => name -> year
}
如果你试图以Int匹配该列,它將不能正解的解析 Null 的情况。假设你想直接从结果集中以Int取出列的内容:
SQL("Select name,indepYear from Country")().map { row =>
row[String]("name") -> row[Int]("indepYear")
}
如果遇到Null值,將导致一个UnexpectedNullableFound(COUNTRY.INDEPYEAR)异常,因此你需要正确的映射成Option[Int]:
SQL("Select name,indepYear from Country")().map { row =>
row[String]("name") -> row[Option[Int]]("indepYear")
}
对于parser API也是同样的情况,接下来会看到。
使用 Parser API
你可以使用 parser api来创建通用解析器,用于解析任意select查询的返回结果。
注意:大多数web应用都返回相似数据集,所以它非常有用。例如,如果你定义了一个能从结果集中解析出Country的Parser 和 另一个 Language Parser,你就通过他们的组合从连接查询中解析出Country和Language。
得首先导入 anorm.SqlParser._
首先,你需要一个RowParser,如一个能將一行数据解析成一个Scala对象的parser。例如我们可以定义將结果集中的单列解析成Scala Long类型的parser:
val rowParser = scalar[Long]
接着我们必须转成ResultSetParser。下面我们將创建parser,解析单行数据:
val rsParser = scalar[Long].single
因此,该parser將解析某结果集,并返回Long。这对于解析 select count 查询返回的结果很有用:
val count: Long = SQL("select count(*) from Country").as(scalar[Long].single)
让我们编写一个更复杂的parser:
str("name")~int("population"),將创建一个能解析包含 String name 列和Integer population列的parser。再接我们可以创建一个ResultSetParser, 它使用 * 来尽量多的解析这种类型的行:
正如你所见,该结果类型是List[String~Int] - country 名称和 population 项的集合。
val populations:List[String~Int] = {
SQL("select * from Country").as( str("name") ~ int("population") * )
}
你也可以这样重写例子:
val result:List[String~Int] = {
SQL("select * from Country").as(get[String]("name")~get[Int]("population")*)
}
那么,关于String~Int类型呢?它一个 Anorm 类型,不能在你的数据访问层外使用.
你可能想用一个简单的 tuple (String, Int) 替代。你调用RowParser的map函数將结果集转换成更通用的类型:
str("name") ~ int("population") map { case n~p => (n,p) } 注意:我们在这里创建了一个 tuple (String,Int),但没人能阻止你RowParser转成其它的类型,例如自定义case class。
现在,鉴于將 A~B~C 类型转成 (A,B,C)是个常见的任务,我们提供了一个flatten函数帮你准备的完成。因此最终版本为:
val result:List[(String,Int)] = {
SQL("select * from Country").as(
str("name") ~ int("population") map(flatten) *
)
}
接下来,让我们创建一个更复杂的例子。怎样创建下面的查询, 使得可以获取国家名和所有的国所使用的语言记录呢?
select c.name, l.language from Country c
join CountryLanguage l on l.CountryCode = c.Code
where c.code = 'FRA'
Letʼs start by parsing all rows as a List[(String,String)] (a list of name,language tuple):
让我们先开始 以一个List[(String,String)](a list of name,language tuple)解析所有的行:
var p: ResultSetParser[List[(String,String)] = {
str("name") ~ str("language") map(flatten) *
}
现在我们得到以下类型的结果:
List(
("France", "Arabic"),
("France", "French"),
("France", "Italian"),
("France", "Portuguese"),
("France", "Spanish"),
("France", "Turkish")
)
我们接下来可以用 Scala collection API,將他转成期望的结果:
case class SpokenLanguages(country:String, languages:Seq[String])
languages.headOption.map { f =>
SpokenLanguages(f._1, languages.map(_._2))
}
最后,我们得到了下面这个适用的函数:
case class SpokenLanguages(country:String, languages:Seq[String])
def spokenLanguages(countryCode: String): Option[SpokenLanguages] = {
val languages: List[(String, String)] = SQL(
"""
select c.name, l.language from Country c
join CountryLanguage l on l.CountryCode = c.Code
where c.code = {code};
"""
)
.on("code" -> countryCode)
.as(str("name") ~ str("language") map(flatten) *)
languages.headOption.map { f =>
SpokenLanguages(f._1, languages.map(_._2))
}
}
To continue, letʼs complicate our example to separate the official language from the others:
为了继续,我们复杂化我们的例子,使得可以区分官方语言:
case class SpokenLanguages(
country:String,
officialLanguage: Option[String],
otherLanguages:Seq[String]
)
def spokenLanguages(countryCode: String): Option[SpokenLanguages] = {
val languages: List[(String, String, Boolean)] = SQL(
"""
select * from Country c
join CountryLanguage l on l.CountryCode = c.Code
where c.code = {code};
"""
)
.on("code" -> countryCode)
.as {
str("name") ~ str("language") ~ str("isOfficial") map {
case n~l~"T" => (n,l,true)
case n~l~"F" => (n,l,false)
} *
}
languages.headOption.map { f =>
SpokenLanguages(
f._1,
languages.find(_._3).map(_._2),
languages.filterNot(_._3).map(_._2)
)
}
}
如果你在world sample数据库尝试该例子,你將获得:
$ spokenLanguages("FRA")
> Some(
SpokenLanguages(France,Some(French),List(
Arabic, Italian, Portuguese, Spanish, Turkish
))
)
集成其它数据库访问层
你也可以在Play中使用任何你喜欢的SQL数据库访问层,并且也可以借助 play.api.db.DB 很容易的取得连接或数据源.
与ScalaQuery集成
从这里开始,你可以集成任何的JDBC访问层,需要一个数据源。例如与ScalaQuery集成:
import play.api.db._
import play.api.Play.current
import org.scalaquery.ql._
import org.scalaquery.ql.TypeMapper._
import org.scalaquery.ql.extended.{ExtendedTable => Table}
import org.scalaquery.ql.extended.H2Driver.Implicit._
import org.scalaquery.session._
object Task extends Table[(Long, String, Date, Boolean)]("tasks") {
lazy val database = Database.forDataSource(DB.getDataSource())
def id = column[Long]("id", O PrimaryKey, O AutoInc)
def name = column[String]("name", O NotNull)
def dueDate = column[Date]("due_date")
def done = column[Boolean]("done")
def * = id ~ name ~ dueDate ~ done
def findAll = database.withSession { implicit db:Session =>
(for(t <- this) yield t.id ~ t.name).list
}
}
从JNDI查找数据源:
一些库希望从JNDI中获取数据源。通过在conf/application.conf添加以下配置,你可以让Play管理任何的JNDI数据源:
db.default.driver=org.h2.Driver db.default.url="jdbc:h2:mem:play" db.default.jndiName=DefaultDS