Redis 2.8.9源码 - Redis中的字典的实现 dict
Redis使用字典的方式实现了数据库键空间,今天就记录一下字典的实现方式。
Redis 对字典的描述和实现源码在 src/dict.h src/dict.c,关于学习Redis字典如何进行测试或debug,请参考另外一篇文章:Redis 2.8.9源码 - 字典哈希表操作函数头整理,并注释作用和参数说明(附测试方法和代码以及使用方法)
字典结构:
typedef struct dict {
dictType *type; //根据存储内容的不同,自定义一组回调函数来控制比较申请内存释放空间等操作
void *privdata; //用于回调函数使用
dictht ht[2]; //存放hash表的结构 0 默认使用0,rehash的时候使用1
int rehashidx; //默认为-1,rehash开始的时候该变量设置为0,完成后重新设置为-1
int iterators; //正在进行的安全迭代的数量,释放安全迭代后会减1
} dict;
typedef struct dictType {
unsigned int (*hashFunction)(const void *key); //针对不同类型进行hash计算的函数,返回hash值
void *(*keyDup)(void *privdata, const void *key); //复制key
void *(*valDup)(void *privdata, const void *obj); //复制val
int (*keyCompare)(void *privdata, const void *key1, const void *key2); //比较key
void (*keyDestructor)(void *privdata, void *key); //释放key
void (*valDestructor)(void *privdata, void *obj); //释放val
} dictType;
哈希表结构:
typedef struct dictht {
//hash表节点的指针数组
dictEntry **table;
//指针数组长度 初始化时候为 DICT_HT_INITIAL_SIZE
unsigned long size;
//数组长度掩码,用于计算索引值 (size-1)
unsigned long sizemask;
//hash表节点数量
unsigned long used;
} dictht;
字典节点结构:
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
} v;
//当前节点指向的后继节点
struct dictEntry *next;
} dictEntry;
三个结构的关系图如下(摘自 Redis 设计与实现第一版):
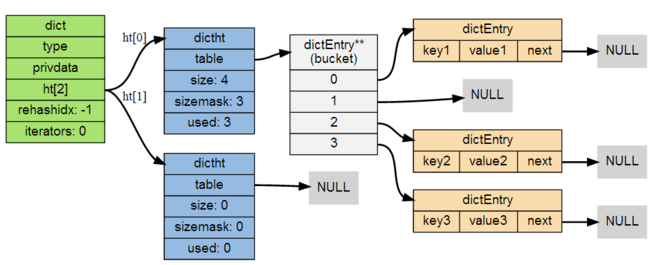
创建字典:
/**
* 创建一个新的字典
* dictType *type 字典操作函数类型(type是一个包含一组回调函数的结构)
* void *privDataPtr 设置为不同类型回调函数提供的 私有参数
* return 返回一个新的字典
*/
dict *dictCreate(dictType *type, void *privDataPtr)
{
//分配空间
dict *d = zmalloc(sizeof(*d));
//初始化字典的值
_dictInit(d,type,privDataPtr);
//返回字典
return d;
}
/**
* 对新的字典进行初始化操作 对字典中的hashtable进行重置操作,并对其他属性设置默认值 私有函数
* dict *d 需要初始化操作的字典
* dictType *type 字典操作函数类型(type是一个包含一组回调函数的结构)
* void *privDataPtr 设置为不同类型回调函数提供的 私有参数
* return 返回初始化的状态
*/
int _dictInit(dict *d, dictType *type, void *privDataPtr)
{
//将两个hash表的值设置为NULL或0进行初始化
_dictReset(&d->ht[0]);
_dictReset(&d->ht[1]);
//设置当前字典的回调函数
d->type = type;
d->privdata = privDataPtr;
//设置rehash为-1表示没有进行rehash操作
d->rehashidx = -1;
//安全迭代数量为0,表示当前没有安全迭代操作
d->iterators = 0;
return DICT_OK;
}
通过设置type属性,来决定在针对字典节点不同类型的key和val,使用不同类型的方式去处理,比如 val 如果是个字符串,在dictType中释放val空间的回调函数将会调用sdsfree函数,这样来保证,字典对任何类型的数据都可以进行操作。
每次创建字典的时候Redis会分配 dict 结构和 dictht 结构的空间,并初始化其值,创建成功后返回字典结构。
向字典中加入新的节点:
/**
* 向hashtable中加入一个新的节点
* dict *d 加入节点的字典
* void *key 节点的key
* void *val 节点的value
* return 返回 成功或失败
*/
int dictAdd(dict *d, void *key, void *val)
{
//根据key创建一个新的节点
dictEntry *entry = dictAddRaw(d,key);
if (!entry) return DICT_ERR;
//给新的节点设置val
dictSetVal(d, entry, val);
return DICT_OK;
}
/**
* 创建一个包含KEY的dictEntry对象,如果正在进行Rehash,会执行一个桶的Rehash操作(在检查key的时候会判断是否处罚rehash)
* dict *d 加入节点的字典
* void *key 节点的key
* return 返回创建成功包含key的dictEntry
*/
dictEntry *dictAddRaw(dict *d, void *key)
{
int index;
dictEntry *entry;
dictht *ht;
//如果正在进行rehash操作,那么执行1次rehash操作
if (dictIsRehashing(d)) _dictRehashStep(d);
//获取key所对应的桶的索引值,如果已经存在则返回-1
if ((index = _dictKeyIndex(d, key)) == -1)
return NULL;
//如果正在进行rehash则将心的值写入到ht[1]中
ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0];
//分配内存
entry = zmalloc(sizeof(*entry));
//将值加入到hash表每个桶的首位置,并设置其后继节点为之前桶的第一个节点
entry->next = ht->table[index];
ht->table[index] = entry;
//节点数量增加
ht->used++;
//设置key
dictSetKey(d, entry, key);
//返回节点结构
return entry;
}
在增加新节点的时候,首先会判断是否进行rehash操作,如果正在进行,则进行一次rehash操作。
之后,系统会根据 key 的值,和dictType配置的hash函数,对key进行hash计算,将hash结果与sizemask进行与运算,来判断分布到哪个桶里。
确定桶的索引后,创建节点结构,分配内存,并将其放入指定桶的首位置,这样如果hash值碰撞,将与其他产生碰撞的的节点通过next串联成一个链表。
添加节点的时候,如果正在进行rehash,则将会把新的节点放到ht[1]中。
根据key删除字典中的某个节点:
/**
* 查找并在hashtable删除某个key所对应的结构
* dict *d 加入节点的字典
* void *key 要删除的节点的key
* int nofree 如果为1 则删除的某个key的结构不进行内存释放
* return 返回 成功或失败
*/
static int dictGenericDelete(dict *d, const void *key, int nofree)
{
unsigned int h, idx;
dictEntry *he, *prevHe;
int table;
if (d->ht[0].size == 0) return DICT_ERR; /* d->ht[0].table is NULL */
//如果正在执行rehash则处理一个rehash结果
if (dictIsRehashing(d)) _dictRehashStep(d);
//根据用户在dictType中设置的hash函数,获取key的hash值
h = dictHashKey(d, key);
//遍历ht[0] 和 ht[1],rehash过程中,节点会分别分布在这两个hash表中
for (table = 0; table <= 1; table++) {
//根据hash与sizemast进行与运算(与取模作用相同但效率更高),得到hash桶的索引
idx = h & d->ht[table].sizemask;
//获取桶内第一个节点
he = d->ht[table].table[idx];
prevHe = NULL;
//遍历桶内的每个节点
while(he) {
//比较桶内节点的key与要删除的key是否相同
if (dictCompareKeys(d, key, he->key)) {
//解除找到节点在桶内的关系
if (prevHe)
prevHe->next = he->next;
else
d->ht[table].table[idx] = he->next;
//如果nofree为false不需要进行释放操作,否则释放key和val的空间
if (!nofree) {
dictFreeKey(d, he);
dictFreeVal(d, he);
}
//释放节点空间
zfree(he);
//节点数量减1
d->ht[table].used--;
return DICT_OK;
}
prevHe = he;
he = he->next;
}
//如果没有进行rehash则不进行ht[1]的查找
if (!dictIsRehashing(d)) break;
}
return DICT_ERR; /* not found */
}
字典的迭代:
typedef struct dictIterator {
dict *d;
//当前的hash表结构,当前进行到的节点位置,是否是安全迭代的标记
int table, index, safe;
//当前节点和后继节点
dictEntry *entry, *nextEntry;
//字典的指纹信息
long long fingerprint;
} dictIterator;
创建迭代结构:
dictIterator *dictGetIterator(dict *d)
{
//分配内存
dictIterator *iter = zmalloc(sizeof(*iter));
//设置迭代的字典
iter->d = d;
//默认查找ht[0]
iter->table = 0;
//默认 索引为 -1
iter->index = -1;
//不进行安全迭代
iter->safe = 0;
iter->entry = NULL;
iter->nextEntry = NULL;
return iter;
}
迭代操作:
//创建字典
dict *d = dictCreate(&type, NULL);
//创建迭代器对象
dictIterator *di = dictGetIterator(d);
dictEntry *de;
//加入三个节点
dictAdd(d, "logbird", "123234123");
dictAdd(d, "logbird2", "23434123");
dictAdd(d, "logbird3", "123452453");
//遍历每一个桶
while ((de = dictNext(di))) {
//遍历桶内的每一个节点
do {
printf("KEY: %s VALUE: %s\n", dictGetKey(de), dictGetVal(de));
} while((de = de->next));
}
dictReleaseIterator(di);
dictRelease(d);
rehash桶的扩展和字典缩短操作:
执行扩展的条件,在进行一些操作的时候会进行rehash条件检测,代码如下:
static int _dictExpandIfNeeded(dict *d)
{
//如果正在进行rehash则退出
if (dictIsRehashing(d)) return DICT_OK;
//如果当前桶的个数为0,则扩展到 DICT_HT_INITIAL_SIZE 个
if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE);
//如果节点数大于桶的个数并且(dict_can_resize 为真或节点数与桶个数的比大于dict_force_resize_ratio)
//dict_force_resize_ratio 默认为 5 则进行rehash操作,桶个数为当前节点数的二倍
if (d->ht[0].used >= d->ht[0].size &&
(dict_can_resize ||
d->ht[0].used/d->ht[0].size > dict_force_resize_ratio))
{
return dictExpand(d, d->ht[0].used*2);
}
return DICT_OK;
}
如果发现需要进行扩展,则进行扩展操作:
int dictExpand(dict *d, unsigned long size)
{
dictht n;
//通过 节点数 计算得出需要扩展的桶的实际个数(2的n次方大于size的最小值—)
unsigned long realsize = _dictNextPower(size);
//如果扩展桶的个数小于当前节点数则返回错误
if (dictIsRehashing(d) || d->ht[0].used > size)
return DICT_ERR;
//分配ht[1]空间并赋予默认值
n.size = realsize;
n.sizemask = realsize-1;
n.table = zcalloc(realsize*sizeof(dictEntry*));
n.used = 0;
//如果ht[0]是空的,直接将扩展后的hash表设置为ht[0]
if (d->ht[0].table == NULL) {
d->ht[0] = n;
return DICT_OK;
}
//设置rehashidx为0标记rehash的开始,并将ht[1]指向新创建的hash表
d->ht[1] = n;
d->rehashidx = 0;
return DICT_OK;
}
Redis在执行一些操作的时候进行渐进式rehash,例如删除操作,添加节点操作等。
static void _dictRehashStep(dict *d) {
//如果当前没有进行安全迭代,则对一个桶进行rehash操作
if (d->iterators == 0) dictRehash(d,1);
}
int dictRehash(dict *d, int n) {
//如果没有进行rehash则退出,rehashidx 大于 -1的时候表示正在进行rehash
if (!dictIsRehashing(d)) return 0;
//n表示进行rehash的桶的个数
while(n--) {
dictEntry *de, *nextde;
//如果ht[0]里没有节点表示rehash结束
//释放ht[0]的hash表,并重置
//同时将ht[0] 指向 ht[1]
//设置rehashidx 为 -1,标志rehash结束
if (d->ht[0].used == 0) {
zfree(d->ht[0].table);
d->ht[0] = d->ht[1];
_dictReset(&d->ht[1]);
d->rehashidx = -1;
return 0;
}
assert(d->ht[0].size > (unsigned)d->rehashidx);
//过滤所有为空的桶
while(d->ht[0].table[d->rehashidx] == NULL) d->rehashidx++;
//获取当前获取到的第一个不为NULL的桶
de = d->ht[0].table[d->rehashidx];
//遍历桶里每一个节点
while(de) {
unsigned int h;
//保存下一个节点
nextde = de->next;
//根据key获得hash值,并与ht[1]的sizemask进行与运算,得到新的桶的索引
h = dictHashKey(d, de->key) & d->ht[1].sizemask;
//将节点加入到ht[1]指定桶的首位
de->next = d->ht[1].table[h];
d->ht[1].table[h] = de;
//ht[0]的节点数减一
d->ht[0].used--;
//ht[1]的节点数加一
d->ht[1].used++;
//将当前节点设置为下一个
de = nextde;
}
//将当前桶设置为NULL
d->ht[0].table[d->rehashidx] = NULL;
//遍历的rehash索引加一
d->rehashidx++;
}
return 1;
}
Redis2.8.9源码 src/dict.h src/dict.c
Redis 设计与实现(第一版)