Heartbeat3.0.5+pacemaker
最近在部署openstack的双控制节点上需要切换资源,所以学习了一下heartbeat和pacemaker,本来想用heartbeat 2但是操作系统是ubuntu 12.10的,apt下来版本直接是3.0.5的,为了以后部署方便只能硬着头皮学了,网上关于3的内容不多,不过和2区别不大,个人感觉还是关于资源的设置比较麻烦一些。
两台机器:10.1.1.2(compute-1) 10.1.1.3(compute-2)
安装heartbetat
apt-get install -y heartbeat
会自动安装其他三个关键包:pacemaker、resource-agents、 cluster-agents
配置heartbeat
在/etc/heartbeat下面配置,ubuntu下自动做了一个软连接/etc/heartbeat其实是/etc/ha.d的连接。进入/etc/heartbeat
cp /usr/share/doc/heartbeat/ha.cf.gz . cp /usr/share/doc/heartbeat/authkeys . gzip -d ha.cf.gz
默认目录下并没有相关配置文件,可以自己手动建立,也可以直接修改软件包中自带的模板,因为使用pacemaker管理资源所以不需要拷贝haresources文件,如果使用了crm管理资源,而在配置文件目录含有haresources文件,日志中会提示haresources没有使用。
配置authkeys文件
auth 2 #1 crc 2 sha1 openstack #3 md5 Hello!官方不建议使用crc验证,所以我们使用sha1进行验证, authkeys文件属性必须是600,否则日志会报错。
配置ha.cf文件(10.1.1.2)
#集群中的节点不会自动加入 autojoin none #heartbeat会记录debug日志,如果启用use_logd,则此选项会被忽略 debugfile /var/log/ha-debug #记录所有non-debug消息,如果启用use_logd,则此选项会被忽略 logfile /var/log/ha-log #告诉heartbeat记录那些syslog logfacility local0 #指定两个心跳检测包的时间间隔 keepalive 1 #多久以后心跳检测决定集群中的node已经挂掉 deadtime 30 #心跳包检测的延时事件,如果延时,只是往日志中记录warning日志,并不切换服务 warntime 10 #在heartbeat启动后,在多长时间内宣布node是dead状态,因为有时候系统启动后,网络还需要一段时间才能启动 initdead 120 #如果udpport指令在bcast ucast指令的前面,则使用哪个端口进行广播,否则使用默认端口 udpport 694 #设置使用哪个网络接口发送UDP广播包,可以设置多个网络接口 #bcast eth1 eth0 #设置在哪个网络接口进行多播心跳检测 #mcast eth0 239.0.0.1 694 1 0 #设置使用哪个网络接口进行UDP单播心跳检测,在.3上为10.1.1.2 ucast eth0 10.1.1.3 #在主节点的服务恢复后,是否把从节点的服务切换回来 auto_failback off #告诉集群中有哪些节点,node名称必须是uname -n显示出来的名称,可以在一个node中设置多个节点,也可以多次设置node,每一个在集群中的node都必须被列出来 node compute-1 node compute-2 #设置ping节点,ping节点用来检测网络连接 ping 10.1.1.254 #开启Pacemaker cluster manager,因为历史原因,次选项默认是off,但是应该保持该选项值为respawn。在设置为respawn默认自动使用以下配置 pacemaker respawn #默认配置文件中下面还有很多选项,由于暂时用不到所以暂时忽略
启动heartbeat
/etc/init.d/heartbeat start
两台机器上执行相同的操作即可,注意:ucast的ip设置即可。
查看heartbeat运行状况:crm_mon -1
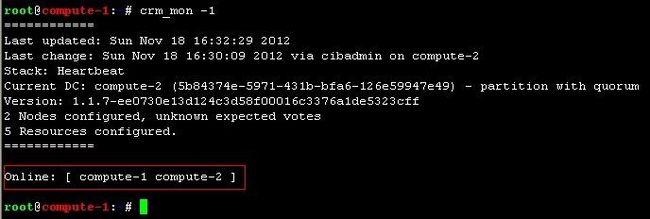
可以看到两台机器均在线,但是由于还没有配置资源所以没有资源信息。
资源管理需求:两台机器作为两台WEB服务器,使用apache软件。对用户接口为VIP(10.1.1.6)。要求不论哪台机器故障、apache服务故障都会把资源切换到正常的服务器上,不影响用户访问。
配置pacemaker,使用交互命令crm,也可以使用非交互模式
crm configure property stonith-enabled=false crm configure property no-quorum-policy=ignore crm configure property start-failure-is-fatal=false crm configure rsc_defaults migration-threshold=1 crm configure primitive vip ocf:heartbeat:IPaddr2 params ip=10.1.1.6 nic=br100 op monitor interval=3s crm configure primitive www lsb:apache2 op monitor interval="10s" crm configure group group1 vip www
再次使用crm查看资源状态

可以看到vip资源和web资源目前运行在compute-1上面,这时候不论是停止compute-1上的apache服务还是网络都会导致vip资源和web资源一起切换到compute-2上。
关键的难点在crm上,关于crm的信息在下一篇中介绍。