HBase文件索引分析
基于HBase 0.94.3分析
HBase总体结构图

部分术语简介
HMaster |
负责管理HRegionServer的接入,负责Region的管理分配,负责管理Table的创建于删除修改等操作。 |
HRegion |
每个Table可以分裂成多个Region,每个Region为Table中的一个行区间。例如RowKey为0-100的Table,可以分裂成0-50以及51-100这两个Region。 |
HRegionServer |
每个HRegionServer管理着多个Region,负责对Region的读写操作等 |
HLog |
每个HRegionServer都有一个HLog用来记录所有操作,主要用于数据损坏时修复数据。物理上是Hadoop的Sequence File |
Store |
每个HRegion下管理着多个Store,每个Store对应Table中的一个Family进行数据管理 |
StoreFile |
Family的持久化数据类 |
MemStore |
每个Store中都有一个MemStore,用来缓存对Family的操作,当MemStore缓存到一点大小之后,将会转换成StoreFile Flush到HDFS中 |
HFile |
StoreFile只是HFile的轻量级封装,HDFS中保存的Table数据文件都是HFile格式 |
索引的总体结构
在HBase中,从整个大框架上来看,索引的分布分为以下几层。

A、在Zookeeper中,根据HMaster的启动,保存着分配了-ROOT- Table的RegionServer的地址。
B、在-ROOT- Table中,保存着.META Table split成多个region后所分布在的RegionServers的信息。
C、在.META中,保存着各个Table的regions所分布的RegionServers地址。
D、-ROOT-只存在一个Region,而.META是可以split成多个的。
-ROOT- 与 META的表结构是一样的,如下
Rowkey |
info |
||
Regioninfo |
server |
serverstartcode |
|
TableName StartKey TimeStamp |
Startkey Endkey family list |
address |
加载当前分片的启动时间 |
-ROOT-示例:
假设.META分裂成了两个Region,分布在了两个RegionServer上
Rowkey |
Info |
||
Regioninfo |
Server |
serverstarcode |
|
.META Table1 pk0 12345278 |
RegionServer1 |
||
.META Table1 pk1000 123451278 |
RegionServer2 |
||
.META Table2 pk0 123431278 |
RegionServer1 |
||
.META Table2 pk1000 123457278 |
RegionServer2 |

.META的示例:
Rowkey |
Info |
||
Regioninfo |
Server |
serverstarcode |
|
Table1 pk0 12345278 |
RegionServer1 |
||
Table1 pk1000 123451278 |
RegionServer2 |
||
Table1 pk2000 12345878 |
RegionServer3 |
||
…… |
…… |
…… |
…… |
Table2 pk0 12345278 |
RegionServer1 |
||
Table2 pk1000 12345478 |
RegionServer2 |
||
Table2 pk2000 12345778 |
RegionServer3 |
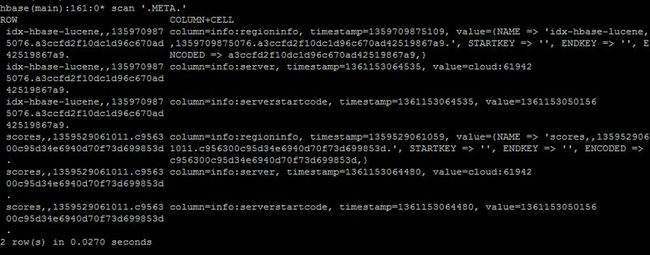
RegionServer的定位过程
当Client要对一个Table中的数据进行put、get、delete操作时,提供了TableName以及RowKey时,Client从Zookeeper中获取到-ROOT-的RegionServer信息,然后从-ROOT-中根据RowKey获取到.META的ReginoServer,从而再定位到RowKey所在的RegionServer中。由于Client在交互过程中会缓存-ROOT-、.META、Region等位置信息,在最优情况下只需要查询一次位置,在最坏情况下是需要6次[ 需要从Table Region递归回去查询 ]。
HFile的数据存储结构:
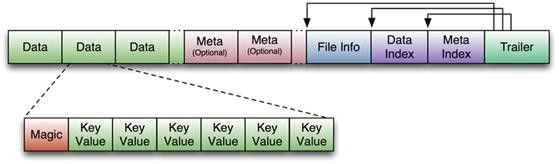
如上图,HFile的文件长度为变长,其中的File Info以及Trailer是定长,Trailer中有指向File Info\Data Index\Meta Index的起始点。Index数据块记录着Data\Meta块的起始点。在Data数据块中,Magic是用来辨别数据是否损坏的,每个Data块中保存着多个KeyValue信息。
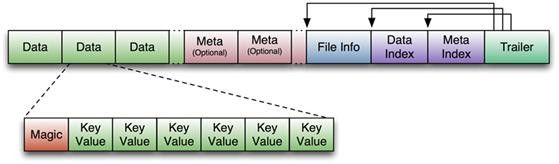
上图为KeyValue的数据结构

上图也为HFile的数据结构
整个的region文件路径就是如下形式:
/<hbase-root-dir>/<tablename>/<encoded-regionname>/<column-family>/<filename>
每个column-family下的一个个HFile数据文件,文件的名字是基于Java内建的随机数生成器产生的任意数字。代码会保证不会产生碰撞,比如当发现新生成的数字已经存在时,它会继续寻找一个未被使用的数字。
Region的操作
当定位到RowKey所在的RegionServer之后,就能根据RegionName来获取到相对应的Region,RegionName来自.META中保存的RowKey。
Get:
1、HRegion.get接口会先对Family做检测,保证Get中的Family与Table中的保持一致。
2、根据Family的信息,找出对应的Store,并获取到Store中的StoreScanner实例,并将其添加到一个scanners队列中。
3、在StoreScanner中,又有MemstoreScanner和HFileScanner两个实例,分别用来遍历MemStore与HFile中的keyValue值的。
4、因为存在多个HFile,因此会对HFileScanner会做一次过滤选择,通过HFile的DataIndex将position指向StarRow,DataIndex中是保存有当前DataBlock的firstKey信息的,如果KeyValue不在当前HFile中,将关闭HFileScanner的查找。
5、需要注意的是,在RegionServer启动之后,HFile的DataIndex是保存在内存中的。
6、当StoreScanner查询相应的keyValue时,先利用MemstoreScanner从MemStore中查找,如果没有相应数据,再利用HFileScanner从HFile的DataBlock中遍历,DataIndex能快速定位Block所在的位置。
7、由于HFile已经被持久化到HDFS中,对HFile的每次IO读取,都只是读取一个Data数据块的大小,Data的位置可以根据HFile的DataIndex信息来查询。
8、如果有配置使用Bloom Filters,将能快速确认一个RowKey或者value是否在一个HFile中。
Put:
1、HRegion.put接口中,会先对通过checkResources() 函数对资源进行检测,如果HRegion的Memstore总大小超过了blockingMemStoreSize,就会进入flush操作,当前操作将会进入阻塞状态,知道memstoresize到达合适的范围内。
2、会对put中的Family进行检查,查看是否跟Table匹配。
3、如果需要将put操作写入到HLog中,将put写入
4、将Put操作写入到memstore中
5、如果memstore超过一定值,将会把memstore转换成StoreFile并flush到 HDFS中
6、如果Store中的StoreFile文件超过一定个数,会触发Compact合并操作,将合并多个StoreFile为一个,Compact合并过程中会进行版本合并和数据删除。这里可以看出HBase在平时只有数据的增加,所有的更新和删除操作都在Compact中进行,这将使用户的写操作进入到内存就可以立即返回了。
7、当StoreFiles Compact后,会逐步形成越来越大的StoreFile,当单个StoreFile大小超过一定阈值后,会触发Split操作,同时把当前Region Split成2个Region,父Region会下线,新Split出的2个孩子Region会被HMaster分配到相应的HRegionServer上,使得原先1个Region的压力得以分流到2个Region上。
Delete:[ 与Put类似 ]