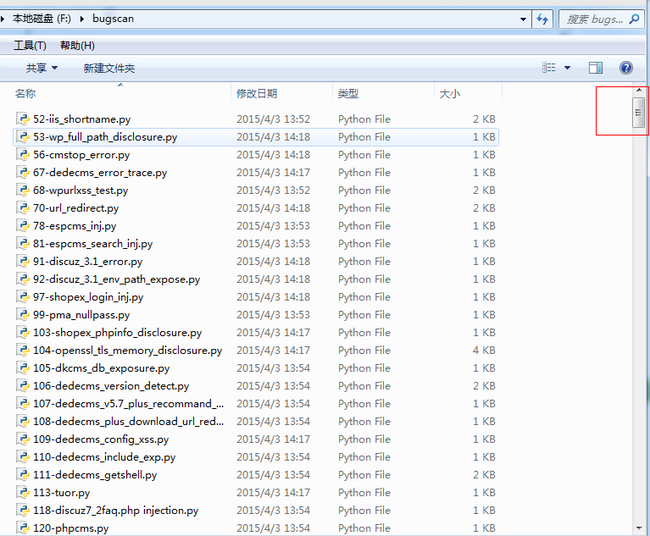
python之爬虫
最近在bugscan上提交各种插件,发现了与很多大神之间的差距。但是自己想弄一些回来慢慢的学习。就萌生了想把全部的explotit全部拖回来看看。
首先我们来抓包看看
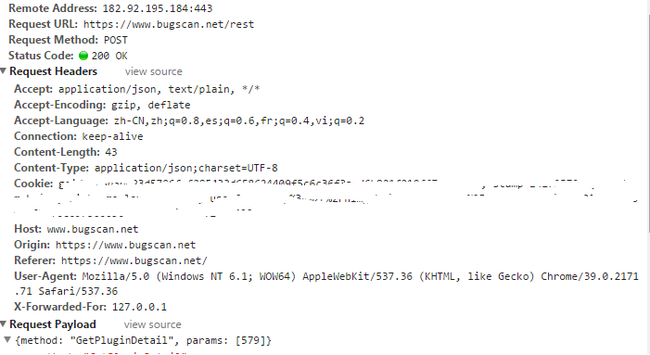
POST /rest HTTP/1.1
Host: www.bugscan.net
Connection: keep-alive
Content-Length: 45
Origin: https://www.bugscan.net
User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36
Content-Type: application/json;charset=UTF-8
Referer: https://www.bugscan.net/
Accept-Encoding: gzip, deflate
Accept: application/json, text/plain, */*
Accept-Language: zh-CN,zh;q=0.8,es;q=0.6,fr;q=0.4,vi;q=0.2
Cookie: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
{"method":"GetPluginDetail","params":[579]}
可以看出来是通过json进行提交的
然后我们用这个数据包利用burp来重放一次
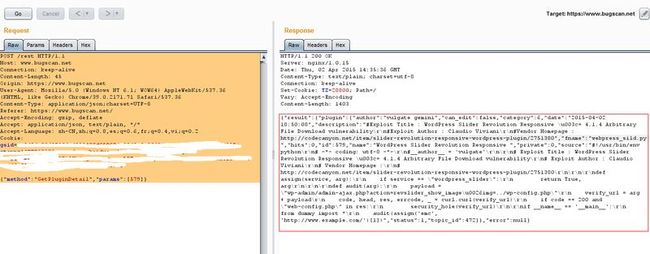
明显是可以看到成功提交的。然后各种精简到后来发现到这样也是可以提交的
POST /rest HTTP/1.1
Host: www.bugscan.net
Content-Type: application/json;charset=UTF-8
Referer: https://www.bugscan.net/
Cookie: xxxxxxxxxxxxxxxxxxxxxx
Content-Length: 45
{"method":"GetPluginDetail","params":[579]}
那么现在可以明确的肯定,我们需要提交的东西包括host url referer content-type cookie 以及 post提交的数据
首先因为要使用json,我们就加载json模块
我们使用urllib2这个组件来抓取网页。
urllib2是Python的一个获取URLs(Uniform Resource Locators)的组件。
它以urlopen函数的形式提供了一个非常简单的接口
#!/usr/bin/env python
# -*- coding: utf-8 -*-
#Author: rookie
import json
import urllib2
url = ' #接收参数的地址
headers = { 'Referer':' #模拟来路
'Content-Type': 'application/json;charset=UTF-8', #提交的方式
'cookie':'xxxxxxxxxxxxxxxxx' #自己的cookie
}
data = {"method":"GetPluginDetail","params":[579]}
postdata = json.dumps(data)
req = urllib2.Request(url, postdata, headers)
response = urllib2.urlopen(req)
the_page = response.read()
print the_page

可以看到现在成功的获取到了这个内容.
然后逐个匹配,内容,文件名字等等
#!/usr/bin/env python
# -*- coding: utf-8 -*-
#Author: rookie
import json
import urllib2
url = ' #接收参数的地址
headers = { 'Referer':'https://www.bugscan.net/',#模拟来路
'Content-Type': 'application/json;charset=UTF-8',#提交的方式
'cookie':'xxxxxxxxxxxxxxxxxxxxxxxxxxx'#自己的cookie
}
data = {"method":"GetPluginDetail","params":[579]}
postdata = json.dumps(data)
req = urllib2.Request(url, postdata, headers)
response = urllib2.urlopen(req)
html_page = response.read()
json_html = json.loads(html_page) #dedao得到原始的数据
source = json_html['result']['plugin']['source'] #获取到我们需要的源码内容
name = json_html['result']['plugin']['fname'] #获取到我们读取的文件名字
f = open('f:/bugscan/'+name,'w')
f.write(source)
f.close()
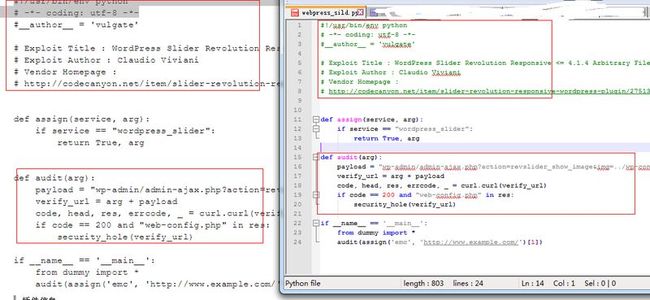
然后就是我们想要做的了..
#!/usr/bin/env python
# -*- coding: utf-8 -*-
#Author: rookie
import json
import urllib2
url = 'https://www.bugscan.net/rest'
headers = { 'Referer':'https://www.bugscan.net/',
'Content-Type': 'application/json;charset=UTF-8',
'cookie':'xxxxxxxxxxxxxxxxxxxxxxxxxxx'
}
for i in range(1, 579+1): #因为到当前为止,只有579篇
datas = {"method":"GetPluginDetail","params":[i]}
postdata = json.dumps(datas)
req = urllib2.Request(url, postdata, headers)
response = urllib2.urlopen(req)
html_page = response.read()
json_html = json.loads(html_page) #dedao得到原始的数据
source = json_html['result']['plugin']['source'] #获取到我们需要的源码内容
name = json_html['result']['plugin']['fname'] #获取到我们读取的文件名字
f = open('f:/bugscan/'+i+name,'w')#写入文件内
f.write(source)
f.close()
下一个修改的地方,因为用户Zero的是不能查看的,所以考虑获取用户的地方直接给他不写入
#!/usr/bin/env python
# -*- coding: utf-8 -*-
#Author: rookie
import json
import urllib2
url = 'https://www.bugscan.net/rest'
headers = { 'Referer':'https://www.bugscan.net/',
'Content-Type': 'application/json;charset=UTF-8',
'cookie':'xxxxxxxxxxxxxxxxxxxxxx'
}
for i in range(1, 579+1):
datas = {"method":"GetPluginDetail","params":[i]}
postdata = json.dumps(datas)
req = urllib2.Request(url, postdata, headers)
response = urllib2.urlopen(req)
html_page = response.read()
if html_page.find('未登录或者是加密插件') == -1: #未登录或者是加密插件的基本不可看
json_html = json.loads(html_page) #dedao得到原始的数据
source = json_html['result']['plugin']['source'] #获取到我们需要的源码内容
name = json_html['result']['plugin']['fname'] #获取到我们读取的文件名字
f = open('f:/bugscan/'+i+name,'w')
f.write(source)
f.close()