干净虚拟机(centos 6.4)上从头到尾安装并调试Mdrill(三)
新建表
9.1建表SQL
CREATE TABLE st( c2 tdouble, cnt tlong ) |
注意:
列名只能小写(系统限制)。
有一列必须是thedate。
2执行建表命令
将建表SQL存储成名称为create.sql的文本文件到“/home/mdrill/alimama/adhoc-core/bin/”目录下,执行
cd /home/mdrill/alimama/adhoc-core/bin/ chmod 777 ./bluewhale ./bluewhale mdrill create ./create.sql |
使用hadoop fs –ls 在hdfs 上查看新建的表文件夹
9.3设置表文件夹访问权限
将数据表再hdfs之上的文件夹权限设置为任何用户均可访问,方便测试:
hadoop fs -chmod -R 777 /mdrill/tablelist |
10、导入数据
数据导入方式分为在线倒入和离线,数据格式 分为seq和txt方式。我们进行离线的txt 倒入,数据列之间使用“\001”分割,就是ascii码的第一个字符。导入的数据按天进行分区,只进行2天的数据模拟倒入,导入程序如下,替换191.168.3.149为实际IP:
import java.io.BufferedWriter; import java.io.IOException; import java.io.OutputStreamWriter; import java.text.SimpleDateFormat; import java.util.Calendar; import java.util.Date; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FSDataOutputStream; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path;
public class ImportData { static Configuration conf = null; static FileSystem fs = null; public static void main(String[] args) throws IOException { conf = new Configuration(); //虚拟机IP String host = "191.168.3.149"; conf.set("fs.default.name", "hdfs://" + host + ":9000"); // conf.set("mapred.job.tracker", "localhost:9001"); fs = FileSystem.get(conf); // 数据表在 hdfs之上的路径 String pathStirng = "/mdrill/tablelist/st"; // 生成一年的文件夹(365个),并将数据写入到文件夹中 文件夹名称:dt=20140201 Calendar calendar = Calendar.getInstance(); // 创建一个日历对象 calendar.setTime(new Date()); calendar.set(2014, 0, 1); SimpleDateFormat sf = new SimpleDateFormat("yyyyMMdd"); int daycount = 0;// 只模拟导入两天的数据 while (calendar.get(Calendar.YEAR) <= 2014 && daycount < 2) { System.out.println(sf.format(calendar.getTime())); String dateStr = sf.format(calendar.getTime()); String path = pathStirng + "/dt=" + dateStr; mkdir(path); writeSTData(path, dateStr); calendar.add(Calendar.DAY_OF_YEAR, 1); daycount++; } fs.close(); } /** * @param dir * @throws IOException */ public static void writeSTData(String dir, String dateStr) throws IOException { FSDataOutputStream fos = null; OutputStreamWriter osw = null; BufferedWriter bw; fos = fs.create(new Path(dir + "/data.txt"), false); osw = new OutputStreamWriter(fos); bw = new BufferedWriter(osw); // 只生成10条模拟数据 for (int i = 0; i < 10; i++) { StringBuilder strBuffer = new StringBuilder(); strBuffer.append(dateStr); strBuffer.append((char) 1); // 第2列数据 ,string strBuffer.append("c1_" + i); // 第3列数据 tdouble strBuffer.append((char) 1); strBuffer.append(2.30d); // 第4列数据 tlong strBuffer.append((char) 1); strBuffer.append(123456789L); strBuffer.append("\n"); bw.write(strBuffer.toString()); } bw.close(); osw.close(); fos.close(); }
public static void mkdir(String dir) throws IOException { Path p = new Path(dir); if (!fs.exists(p)) { fs.mkdirs(p); } } } |
运行以上程序需要的jar包列表,在jdk1.6下运行:
httpclient-4.1.1.jar, httpcore-4.1.jar, guava-r09-jarjar.jar, hadoop-core-0.20.2-cdh3u3.jar, commons-logging-1.1.1.jar,adhoc-core-0.18-beta.jar,adhoc-public-0.18-beta.jar,adhoc-jdbc-0.18-beta.jar |
在 /home/mdrill/alimama/adhoc-core/lib, /home/mdrill/hadoop-0.20.2-cdh3u3和/home/mdrill/hadoop-0.20.2-cdh3u3/lib下可以找到。
生成后的目录结构如下:

11、生成索引
离线索引创建
cd /home/mdrill/alimama/adhoc-core/bin/ ./bluewhale mdrill index st /mdrill/tablelist/st 3650 20140101 txt |
索引的map/reduce 任务完成后在hdfs上可以看到索引文件夹index:
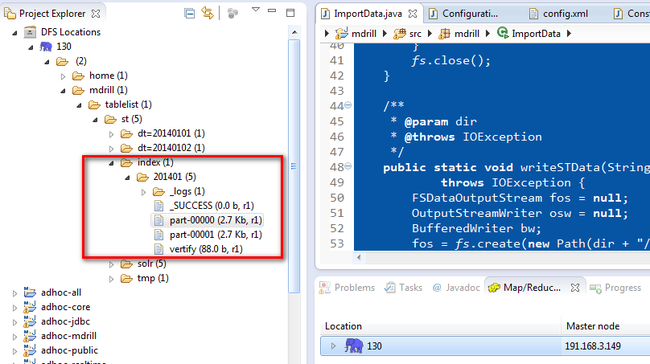
12、启动表
./bluewhale mdrill table st |
表启动后进程信息如下:
[mdrill@mdrill bin]$ jps 2913 DataNode 3196 TaskTracker 3098 JobTracker 2819 NameNode 15998 Worker 15811 Supervisor 16025 Worker 3012 SecondaryNameNode 15887 MdrillUi 15760 NimbusServer 15978 Worker 16100 Jps 9165 QuorumPeerMain |
多出3个worker。
浏览器上的显示界面:
