Nutch源码剖析 关于robot (HttpBase)
关于robot
author : 旱魃斗天 [email protected] 开拓者部落 ccqq 群 248087140
org.apache.nutch.fetcher.Fetcher734
Protocol protocol = this.protocolFactory.getProtocol(fit.url.toString());
BaseRobotRules rules = protocol.getRobotRules(fit.url, fit.datum);
参数说明
getRobotRules方法中FetchItem 的声明:
FetchItem fit = null;
fit = fetchQueues.getFetchItem();
HttpBase中关于robot的分析
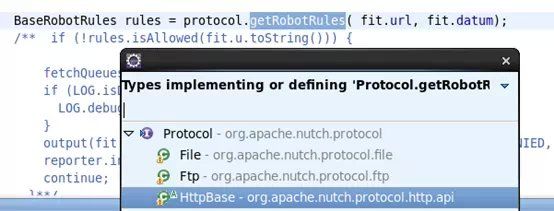
在实现类httpbase中有getRobotRules的实现
public BaseRobotRules getRobotRules(Text url, CrawlDatum datum) {
return robots.getRobotRulesSet(this, url);
}
方法中体中robots.getRobotRulesSet(this, url);中robots的声明如下
private HttpRobotRulesParser robots = null;
在构造方法中,创建了对象
public HttpBase(Logger logger) {
if (logger != null) {
this.logger = logger;
}
robots = new HttpRobotRulesParser();
}
Httpbase有两个构造方法,还有一个是无参数的构造方法。
在setConf方法中做了配置
// Inherited Javadoc
public void setConf(Configuration conf) {
this.conf = conf;
this.proxyHost = conf.get("http.proxy.host");
this.proxyPort = conf.getInt("http.proxy.port", 8080);
this.useProxy = (proxyHost != null && proxyHost.length() > 0);
this.timeout = conf.getInt("http.timeout", 10000);
this.maxContent = conf.getInt("http.content.limit", 64 * 1024);
this.userAgent = getAgentString(conf.get("http.agent.name"), conf.get("http.agent.version"), conf
.get("http.agent.description"), conf.get("http.agent.url"), conf.get("http.agent.email"));
this.acceptLanguage = conf.get("http.accept.language", acceptLanguage);
this.accept = conf.get("http.accept", accept);
// backward-compatible default setting
this.useHttp11 = conf.getBoolean("http.useHttp11", false);
this.robots.setConf(conf);
logConf();
}
org.apache.nutch.protocol.RobotRulesParser中关于robot的分析
httpbase对RobotRulesParser中getRobotRulesSet方法的调用
public BaseRobotRules getRobotRules(Text url, CrawlDatum datum) {
return robots.getRobotRulesSet(this, url);
}
RobotRulesParser的getRobotRulesSet
public BaseRobotRules getRobotRulesSet(Protocol protocol, Text url) {
URL u = null;
try {
u = new URL(url.toString());
} catch (Exception e) {
return EMPTY_RULES;
}
return getRobotRulesSet(protocol, u);
}
return getRobotRulesSet(protocol, u);一句,调用了抽象方法getRobotRulesSet
public abstract BaseRobotRules getRobotRulesSet(Protocol protocol, URL url);
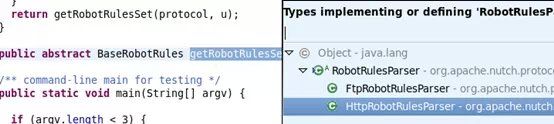
HttpRobotRulesParser中关于robot的实现
package org.apache.nutch.protocol.http.api;
/**
* This class is used for parsing robots for urls belonging to HTTP protocol.
这个类用来解析robots中符合http协议的urls
* It extends the generic {@link RobotRulesParser} class and contains
它继承了robotrulesparser并且包含了获取robots file 的http协议实现
* Http protocol specific implementation for obtaining the robots file.
*/
public class HttpRobotRulesParser extends RobotRulesParser {
public static final Logger LOG = LoggerFactory.getLogger(HttpRobotRulesParser.class);
protected boolean allowForbidden = false;
HttpRobotRulesParser() { }
public HttpRobotRulesParser(Configuration conf) {
super(conf);
allowForbidden = conf.getBoolean("http.robots.403.allow", false);
}
/**
* The hosts for which the caching of robots rules is yet to be done,
* it sends a Http request to the host corresponding to the {@link URL}
* passed, gets robots file, parses the rules and caches the rules object
* to avoid re-work in future.
*
对于没有robots跪着的主机,发送一个与url一致的http request 到这个host
获取robots文件,解析规则,缓存规则对象,已方便后来使用
* @param http The {@link Protocol} object
* @param url URL
*
* @return robotRules A {@link BaseRobotRules} object for the rules
*/
public BaseRobotRules getRobotRulesSet(Protocol http, URL url) {
String protocol = url.getProtocol().toLowerCase(); // normalize to lower case
String host = url.getHost().toLowerCase(); // normalize to lower case
BaseRobotRules robotRules = (SimpleRobotRules)CACHE.get(protocol + ":" + host);
//CACHE继承自父类 RobotRulesParser
//声明如下
//protected static final Hashtable<String, BaseRobotRules> CACHE = new Hashtable<String, //BaseRobotRules> ();
boolean cacheRule = true;
if (robotRules == null) { // cache miss
URL redir = null;
if (LOG.isTraceEnabled()) { LOG.trace("cache miss " + url); }
try {
Response response = ((HttpBase)http).getResponse(new URL(url, "/robots.txt"),
new CrawlDatum(), true);
跟踪代码发现 http是org.apache.nutch.protocol.httpclient.Http
// try one level of redirection ?
if (response.getCode() == 301 || response.getCode() == 302) {
String redirection = response.getHeader("Location");
if (redirection == null) {
// some versions of MS IIS are known to mangle this header
redirection = response.getHeader("location");
}
if (redirection != null) {
if (!redirection.startsWith("http")) {
// RFC says it should be absolute, but apparently it isn't
redir = new URL(url, redirection);
} else {
redir = new URL(redirection);
}
response = ((HttpBase)http).getResponse(redir, new CrawlDatum(), true);
}
}
if (response.getCode() == 200) // found rules: parse them
robotRules = parseRules(url.toString(), response.getContent(),
response.getHeader("Content-Type"),
agentNames);
else if ( (response.getCode() == 403) && (!allowForbidden) )
robotRules = FORBID_ALL_RULES; // use forbid all
else if (response.getCode() >= 500) {
cacheRule = false;
robotRules = EMPTY_RULES;
}else
robotRules = EMPTY_RULES; // use default rules
} catch (Throwable t) {
if (LOG.isInfoEnabled()) {
LOG.info("Couldn't get robots.txt for " + url + ": " + t.toString());
}
cacheRule = false;
robotRules = EMPTY_RULES;
}
if (cacheRule) {
CACHE.put(protocol + ":" + host, robotRules); // cache rules for host
if (redir != null && !redir.getHost().equals(host)) {
// cache also for the redirected host
CACHE.put(protocol + ":" + redir.getHost(), robotRules);
}
}
}
return robotRules;
}
}
public class HttpResponse implements Response
package org.apache.nutch.protocol.httpclient;
// JDK imports
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.net.URL;
// HTTP Client imports
import org.apache.commons.httpclient.Header;
import org.apache.commons.httpclient.HttpVersion;
import org.apache.commons.httpclient.cookie.CookiePolicy;
import org.apache.commons.httpclient.methods.GetMethod;
import org.apache.commons.httpclient.params.HttpMethodParams;
import org.apache.commons.httpclient.HttpException;
// Nutch imports
import org.apache.nutch.crawl.CrawlDatum;
import org.apache.nutch.metadata.Metadata;
import org.apache.nutch.metadata.SpellCheckedMetadata;
import org.apache.nutch.net.protocols.HttpDateFormat;
import org.apache.nutch.net.protocols.Response;
import org.apache.nutch.protocol.http.api.HttpBase;
/**
* An HTTP response.
*
* @author Susam Pal
*/
public class HttpResponse implements Response {
private URL url;
private byte[] content;
private int code;
private Metadata headers = new SpellCheckedMetadata();
/**
* Fetches the given <code>url</code> and prepares HTTP response.
*
* @param http An instance of the implementation class
* of this plugin
* @param url URL to be fetched
* @param datum Crawl data
* @param followRedirects Whether to follow redirects; follows
* redirect if and only if this is true
* @return HTTP response
* @throws IOException When an error occurs
*/
HttpResponse(Http http, URL url, CrawlDatum datum,
boolean followRedirects) throws IOException {
// Prepare GET method for HTTP request
this.url = url;
GetMethod get = new GetMethod(url.toString());
get.setFollowRedirects(followRedirects);
get.setDoAuthentication(true);
if (datum.getModifiedTime() > 0) {
get.setRequestHeader("If-Modified-Since",
HttpDateFormat.toString(datum.getModifiedTime()));
}
// Set HTTP parameters
HttpMethodParams params = get.getParams();
if (http.getUseHttp11()) {
params.setVersion(HttpVersion.HTTP_1_1);
} else {
params.setVersion(HttpVersion.HTTP_1_0);
}
params.makeLenient();
params.setContentCharset("UTF-8");
params.setCookiePolicy(CookiePolicy.BROWSER_COMPATIBILITY);
params.setBooleanParameter(HttpMethodParams.SINGLE_COOKIE_HEADER, true);
// XXX (ab) not sure about this... the default is to retry 3 times; if
// XXX the request body was sent the method is not retried, so there is
// XXX little danger in retrying...
不确定 默认是不是重试3次,如果请求体被发送,方法却没有重试,会导致正在重试中的动作发生危险
// params.setParameter(HttpMethodParams.RETRY_HANDLER, null);
try {
code = Http.getClient().executeMethod(get);
Header[] heads = get.getResponseHeaders();
for (int i = 0; i < heads.length; i++) {
headers.set(heads[i].getName(), heads[i].getValue());
}
// Limit download size
int contentLength = Integer.MAX_VALUE;
String contentLengthString = headers.get(Response.CONTENT_LENGTH);
if (contentLengthString != null) {
try {
contentLength = Integer.parseInt(contentLengthString.trim());
} catch (NumberFormatException ex) {
throw new HttpException("bad content length: " +
contentLengthString);
}
}
if (http.getMaxContent() >= 0 &&
contentLength > http.getMaxContent()) {
contentLength = http.getMaxContent();
}
// always read content. Sometimes content is useful to find a cause
// for error.
InputStream in = get.getResponseBodyAsStream();
try {
byte[] buffer = new byte[HttpBase.BUFFER_SIZE];
int bufferFilled = 0;
int totalRead = 0;
ByteArrayOutputStream out = new ByteArrayOutputStream();
while ((bufferFilled = in.read(buffer, 0, buffer.length)) != -1
&& totalRead + bufferFilled <= contentLength) {
totalRead += bufferFilled;
out.write(buffer, 0, bufferFilled);
}
content = out.toByteArray();
} catch (Exception e) {
if (code == 200) throw new IOException(e.toString());
// for codes other than 200 OK, we are fine with empty content
} finally {
if (in != null) {
in.close();
}
get.abort();
}
StringBuilder fetchTrace = null;
if (Http.LOG.isTraceEnabled()) {
// Trace message
fetchTrace = new StringBuilder("url: " + url +
"; status code: " + code +
"; bytes received: " + content.length);
if (getHeader(Response.CONTENT_LENGTH) != null)
fetchTrace.append("; Content-Length: " +
getHeader(Response.CONTENT_LENGTH));
if (getHeader(Response.LOCATION) != null)
fetchTrace.append("; Location: " + getHeader(Response.LOCATION));
}
// Extract gzip, x-gzip and deflate content
if (content != null) {
// check if we have to uncompress it
String contentEncoding = headers.get(Response.CONTENT_ENCODING);
if (contentEncoding != null && Http.LOG.isTraceEnabled())
fetchTrace.append("; Content-Encoding: " + contentEncoding);
if ("gzip".equals(contentEncoding) ||
"x-gzip".equals(contentEncoding)) {
content = http.processGzipEncoded(content, url);
if (Http.LOG.isTraceEnabled())
fetchTrace.append("; extracted to " + content.length + " bytes");
} else if ("deflate".equals(contentEncoding)) {
content = http.processDeflateEncoded(content, url);
if (Http.LOG.isTraceEnabled())
fetchTrace.append("; extracted to " + content.length + " bytes");
}
}
// Logger trace message
if (Http.LOG.isTraceEnabled()) {
Http.LOG.trace(fetchTrace.toString());
}
} finally {
get.releaseConnection();
}
}
/* ------------------------- *
* <implementation:Response> *
* ------------------------- */
public URL getUrl() {
return url;
}
public int getCode() {
return code;
}
public String getHeader(String name) {
return headers.get(name);
}
public Metadata getHeaders() {
return headers;
}
public byte[] getContent() {
return content;
}
/* -------------------------- *
* </implementation:Response> *
* -------------------------- */
}