MongoDB
主要特性
统一的UTF-8编码
跨平台支持:二进制文件可以在Windows,Linux,OS X和Solaris平台上使用
面向集合存储,易存储对象类型的数据
模式自由
支持动态查询
支持完全索引,包含内部对象
支持复制和故障恢复
自动处理碎片,以支持云计算层次的扩展性
基础介绍
数据模型
基础文档(最大16M)
由key-value组成的BSON格式文档
每个文档存储在集合中
集合
像关系数据库中的表
文档不必有均匀的结构
BSON
“二进制JSON”
允许“引用”
嵌入式结构
目标
轻量
可遍历性
高效(解码和编码)
与关系型数据库对比

安装
安装包下载连接,具体安装文档详见:Install Doc
CRUD(增删改查)操作
增加文档
语法
db.<collection>.insert({<field>:<value>})
示例

说明
插入多文档,insert参数中传递数组即可
所有文档都必须小于16MB,使用Object.bsonsize(doc)校验大小
查询文档
语法
db.<collection>.find()
示例

类似于传统关系型查询SQL:

说明
find():返回一个游标,显示开头的20条结果,和find({})返回结果相同,游标在闲置10分钟后,服务器将自动关闭游标,或者客户端已经用尽游标
findOne():查询返回单个文档
Projection:投影,指定想要的键,这样做既会节省传输的数据量,又能节省客户端解码文档的时间和内存消耗,1表示需要得到的列,0表示不需要的列,结果中则不显示
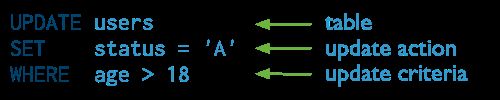
更新文档
语法
db.<collection>.update(
{<field1>:<value1>},
{$set: {<field2>:<value2>}},
{multi:true} )
示例

类似于传统关系型查询SQL:
说明
默认情况下,update只会更新一条文档,加入multi选项可以更新所有符合条件的文档
upsert是一种特殊的更新,要是没有找到符合更新条件的文档,就会以这个条件和更新文档为基础创建一个新的文档
运行getLastError命令(可以理解为“返回最后一次操作的相关信息”)
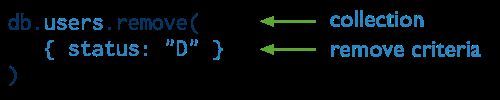
删除文档
语法
db.<collection>.remove({<field>:<value>})
示例
类似于传统关系型查询SQL:

说明
默认情况下,remove()会删除集合中的所有文档,但是不会删除集合本身,也不会删除集合的元信息
删除数据是永久性的,不能撤销,也不能恢复
索引
不使用索引的查询称为全表扫描
explain()函数查看MongoDB在执行查询的过程中所做的事情
基本操作
创建
db.users.ensureIndex({score: 1})
显示存在的索引
db.users.getIndexs()
删除索引
db.users.dropIndex({score: 1})
强制使用特定的索引
db.<collection>.find({<querycriteria>}).hint({<index>})
注意事项
所有的索引信息存放在system.indexs集合中
每个集合最多只能有64个索引
隐式索引:复合索引包含了其中的单字段索引
默认情况下,集合都有“_id“索引,在调用createCollection创建集合时指定autoIndexId选项为false,就不自动创建了,实践中,不建议这么做
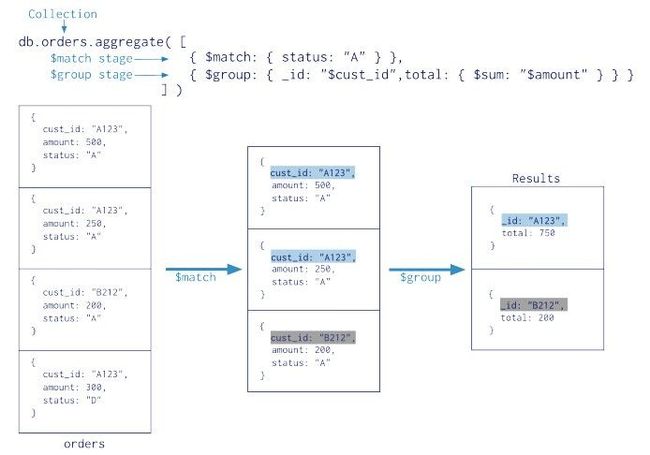
聚合
在mongodb2.2 中引进了新的聚合框架(aggregation framework),聚合框架可以帮助我们完成SQL相同的聚合函数功能
提供了强大的数据处理管道(data processing pipelines),管道提供过最基础的滤查询操作
其他管道操作提供特殊字段的分组文档(grouping document)、排序文档(sorting document),聚合代码采用数组方式操作
管道提供强大的数据聚合并且使用本地接口操作,是mongodb聚合操作的首选方式
示例:
管道操作符
$match: 用于对文档集合进行筛选
$project: 投射操作,可以从子文档中提取字段,可以重命名字段,例如:{“$project”: {“author”: 1, “_id”: 0}}
$group: 可以将文档依据特定字段的不同值进行分组
$unwind: 拆分,可以将数组中的每一个值拆分为单独的文档,例如:{“$unwind”: “$comments”}
$sort:可以根据任何字段(或者多个字段)进行排序,例如:{“$sort”: {“name”: 1, “age”: -1}}
$limit: 接受一个数字n,返回结果集中的前n个文档,例如:{$limit: 11}
$skip: 接受一个数字n,丢弃结果集中的前n个文档,将剩余文档作为结果返回,例如:{$skip: 110}
聚合命令
$count: 返回集合中的文档数量,例如:db.foo.count()
$distinct: 用来找出给定键的所有不同值,使用时必须知道集合和键,例如:db.runCommand({‘distinct’: ‘person’, “key”: ‘age’})
$group:可以执行更复杂的聚合,和sql中的group by差不多
ns: 指定要进行分组的集合
key: 指定文档分组依据的键
initial: 每一组reduce函数调用中的初始”time”值,会作为初始文档传递给后续过程
$reduce: function(doc, prev){..} 这个函数会在集合内的每个文档上执行。系统会传递两个参数:当前文档和累加器文档(本组当前的结果)
$group示例:
db.runCommand({“group”: {
“ns”: “stocks”,
“key”: “day”:
“initial”: {“time”: 0},
“$reduce”: function (doc, prev){
if(doc.time > prev.time){
prev.price = doc.price;
prev.time = doc.time;
}
}
});
副本集和分片
副本集
冗余和故障转移
零停机升级和维护更新
主从复制
强一致性
延迟一致性
地理空间功能
配置
分片
分割数据
缩放写入吞吐量
增加容量
自动均衡
数据管理
用户
数据库中的用户是作为文档被储存在其system.users集合中
Mongod启动时加入—auth选项,或在mongo.conf中将auth设置为true,将权限控制启用
创建
db.createUser({
user: “<name>”,
pwd: “<password>”,
roles: [{role: 'root', db: “<dataname>”}]
})
MongoDB低于2.6的版本创建用户有所不同,具体用法如下:
db.addUser('<name>', '<password>');
验证
mongo –host <host> -u <name> -p <password> --authenticationDatabase < dataname>
修改用户密码
db.changeUserPassword(“<name>”, “<newpwd>”);
角色
所有用户角色信息存放在admin库system.roles集合中
创建
db.createRole({
role: ‘<rolename>',
privileges: [
{resource: {cluster: true},
actions: ['addShard']},
{resource: {db: ‘<dbname>',
collection: “<collname>” },
actions: [ “find” ]},
],
roles: [
{role: 'read', db: 'admin'}
],
writeConcern: {w: 'majority', wtimeout: 5000}
});
## 说明:创建了一个名称为<rolename>的角色,具有增加分片集群的权限,对<dbname>数据库中的<collname>集合有find权限,对admin数据库有read权限,写入关系是大多数,超时时间为5000毫秒
分配角色
db.grantRolesToUser({
‘<user>',
[{role: ‘<rolename>', db: ‘<dbname>'}]
});
验证
db.getUser(‘<user>’)
常用命令
更新
添加字段并赋值
db.collectionName.update({}, {$set: {theField: theValue}}, {multi: 1})
## 说明:由于mongodb没有严格意义的插入字段的说法,只要更新了一个不存在的字段就会插入该字段,所以这里借用了update语句,第一个参数{}表示任意匹配,$set片段表示设置新字段和新值,multi片段表示所有匹配都更新,这里1也可以设置成true。