Storm的简单介绍与安装
Storm的集群跟hadoop的集群非常像。但是在Hadoop上面你运行的是MapReduce的Job, 而在Storm上面你运行的是Topology。
在Storm的集群里面有两种节点: 控制节点(master node)和工作节点(worker node)。控制节点上面运行一个后台程序: Nimbus, 它的作用类似Hadoop里面的JobTracker。Nimbus负责在集群里面分布代码,分配工作给机器, 并且监控状态。
每一个工作节点上面运行一个叫做Supervisor的节点。Supervisor会监听分配给它那台机器的工作,根据需要 启动/关闭工作进程。每一个工作进程执行一个Topology的一个子集;一个运行的Topology由运行在很多机器上的很多工作进程组成。
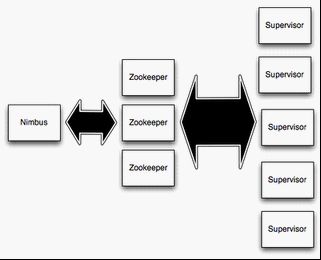
Nimbus和Supervisor之间的所有协调工作都是通过一个Zookeeper集群来完成。
Stream是storm里面的关键抽象。一个stream是一个没有边界的tuple序列。storm提供一些原语来分布式地、可靠地把一个stream传输进一个新的stream。比如: 你可以把一个tweets流传输到热门话题的流。
storm提供的最基本的处理stream的原语是spout和bolt。你可以实现Spout和Bolt对应的接口以处理你的应用的逻辑。
Spout的流的源头。比如一个Spout可能从Kestrel队列里面读取消息并且把这些消息发射成一个流。
Bolt可以接收任意多个输入stream,作一些处理, 有些Bolt可能还会发射一些新的stream。一些复杂的流转换, 比如从一些tweet里面计算出热门话题, 需要多个步骤, 从而也就需要多个Bolt。 Bolt可以做任何事情: 运行函数, 过滤tuple, 做一些聚合, 做一些合并以及访问数据库等等。
Spout和Bolt所组成一个网络会被打包成Topology, Topology是Storm里面最高一级的抽象,相当于Hadoop的MapReduce,你可以把Topology提交给Storm的集群来运行。
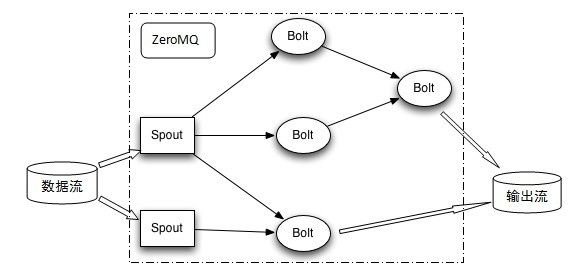
在整个数据流之间有一个ZeroMQ组件,它主要负责消息传递工作的,通过协调可以避免数据传输中的排队阻塞现象。
Topology里面的每一个节点都是并行运行的。 在你的Topology里面, 你可以指定每个节点的并行度,Storm则会在集群里面分配那么多线程来同时计算。
Storm安装
Storm的依赖软件比较多,需要装Python、zookeeper、zeromq以及jzmq,然后才是storm的安装。
Storm的单机版安装过程
第一步,安装Python2.7.2
# wget http://www.python.org/ftp/python/2.7.2/Python-2.7.2.tgz # tar zxvf Python-2.7.2.tgz # cd Python-2.7.2 # ./configure //配置依赖之类的,生成makefile # make //编译makefile # make install //安装 # vi /etc/ld.so.conf
在最后面追加/usr/local/lib/
# sudo ldconfig
至此,Python2.7.2就安装完毕了。
第二步,安装zookeeper
目的:协调整个集群,主要是做Nimbus和Supervisor的联系中介,管理集群中的组件的作用
#wget http://ftp.meisei-u.ac.jp/mirror/apache/dist//zookeeper/zookeeper-3.4.5/zookeeper-3.4.5.tar.gz # tar zxf zookeeper-3.4.5.tar.gz # cp -R zookeeper-3.4.5 /usr/local/ # ln -s /usr/local/zookeeper-3.4.5/ /usr/local/zookeeper # vi ~./bashrc (设置ZOOKEEPER_HOME和ZOOKEEPER_HOME/bin) 追加: export ZOOKEEPER_HOME="/path/to/zookeeper" export PATH=$PATH:$ZOOKEEPER_HOME/bin #cp /usr/local/zookeeper/conf/zoo_sample.cfg /usr/local/zookeeper/conf/zoo.cfg
#cp /usr/local/zookeeper/conf/zoo_sample.cfg /usr/local/zookeeper/conf/zoo.cfg
(用zoo_sample.cfg制作$ZOOKEEPER_HOME/conf/zoo.cfg)
修改zoo.cfg文件内容
#vim zoo.cfg # the directory where the snapshot is stored. # do not use /tmp for storage, /tmp here is just # example sakes. dataDir=/usr/local/zookeeper/zookeeperdir/zookeeper-data dataLogDir=/usr/local/zookeeper/zookeeperdir/logs # sudo mkdir /tmp/zookeeper # sudo mkdir /var/log/zookeeper
至此,zookeeper的单机安装已经完成了。
第三步,安装zeromq以及jzmq
jzmq的安装貌似是依赖zeromq的,所以应该先装zeromq,再装jzmq。
1)安装zeromq:
zeromq是用来做底层通信的
zeromq是网络栈中新的一层,它是个可伸缩层,分散在分布式系统间。因此,它可支持任意大的应用程序。zeromq不是简单的点对点交互,相反,它定义了分布式系统的全局拓扑。zeromq应用程序没有锁,可并行运行。此外,它可在多个线程、内核和主机盒之间弹性伸缩。
# wget http://download.zeromq.org/zeromq-3.2.2.tar.gz # tar zxf zeromq-3.2.2.tar.gz # cd zeromq-3.2.2 # ./configure # make # make install # sudo ldconfig (更新LD_LIBRARY_PATH)
这里要说一下在./configure中可能会遇到的问题:
configure:error:in '/usr/local/download/zeromq-2.1.7':
congifure:error:no acceptable C compiler found in $PATH
See 'config.log' for more details
这是因为没有安装C编译器。
解决方法是:# yum install gcc*
之后遇到的问题是:Error:cannot link with -luuid, install uuid-dev
这是因为没有安装uuid相关的package。
解决方法是:# yum install uuid*
# yum install e2fsprogs*
# yum install libuuid*
本人遇到的问题是出现了C++编译问题
解决办法
#apt-get install g++
#./configure
问题解决了以后就可以make和make install了,如此这般,zeromq就安装好了,接下来即可安装jzmq。
2)安装jzmq
这个找不到清楚的解释,目测是绑定java与zeromq
# yum install git //这一步出现问题,找不到包,换用apt-get命令即可 # git clone git://github.com/nathanmarz/jzmq.git # cd jzmq # ./autogen.sh # ./configure # make # make install
然后,jzmq就装好了,这里有个网站上参考到的问题没有遇见,遇见的话可以参考下。在./autogen.sh这步如果报错:autogen.sh:error:could not find libtool is required to run autogen.sh,这是因为缺少了libtool,可以用#yum(apt-get) install libtool*来解决
除了上面的错误,还有一个错误could not find autoreconf. autoconf and automake are required to run autogen.sh.
解决办法是apt-get install automake
make错误信息:
make[1]: *** No rule to make target `classdist_noinst.stamp',
needed by `org/zeromq/ZMQ.class'. Stop.
解决方法:手动创建classdist_noinst.stamp空文件。
touch src/classdist_noinst.stamp
make错误信息:
error: cannot access org.zeromq.ZMQ
class file for org.zeromq.ZMQ not found
javadoc: error - Class org.zeromq.ZMQ not found.
解决方法:手动编译,然后重新make即可通过。
cd src
javac -d . org/zeromq/*.java
第五步,安装Storm
# wget http://github.com/downloads/nathanmarz/storm-0.7.1.zip # unzip storm-0.7.1.zip # cp -R storm-0.7.1 /usr/local/ #vi ~/.bashrc 追加export STORM_HOME=/usr/local/storm-0.7.1 export PATH=$PATH:$STORM_HOME/bin #vim /etc/hosts
在127.0.0.1 后面加上本机名(JueFan),如果不加上去的话可能导致supervisor启动失败
到此为止单机版的Storm就安装完毕了。
第六步,测试一下本地模式的WordCount
首先启动zookeeper
#bin/zkServer.sh start
然后再分别启动Storm的Nimbus和Supervisor
#bin/storm nimbus #bin/storm supervisor
如果想要监视Storm的Topology的运行状态,要先运行
#bin/storm ui
然后在网页上的8080端口即可看到运行状态
Github里有一个例子叫做storm_starter,我们可以用它来做测试。
安装maven
#wget http://mirror.bjtu.edu.cn/apache/maven/maven-3/3.0.4/binaries/apache-maven-3.0.4-bin.tar.gz #cp apache-maven-3.0.4-bin.tar.gz /usr/local #cd /usr/local #tar -zxvf apache-maven-3.0.4-bin.tar.gz #ln -s apache-maven-3.0.4 maven #vim /etc/profile export M2_HOME=/usr/local/maven PATH=$PATH:$JAVA_HOME/bin:$M2_HOME/bin
#Source /etc/profile #mvn -v 查看是否安装成功
按照http://github.com/nathanmarz/storm-starter,执行这个程序需要用lein,我们用eclipse代替lein。打包后进行上传。
执行命令:# storm jar StormStarter.jar storm.starter.WordCountTopology
如果出现下面的文字,说明运行成功了~
11367 [Thread-25] INFO backtype.storm.daemon.task - Emitting: class storm.starter.ExclamationTopology$ExclamationBolt source: 2:3, stream: 1, id: {}, [golda!!!]
....
本人自己是按以下代码执行的:#storm jar storm-start.jar mytest.LogProcess tmp.txt , out.txt false
集群形式的由于没有机器,没有尝试过安装……