透过数据,横看成岭侧成峰
推荐评论
select m1.userid,m2.userid,
(sum(m1.level*m2.level)-sum(m1.level)*sum(m2.level)/10) /sqrt((sum(power(m1.level,2))-power(sum(m1.level),2)/10)*(sum(power(m2.level,2))-power(sum(m2.level),2)/10)) Rxy
From moive_level m1,moive_level m2
where m1.userid<> m2.userid and m1.moiveid=m2.moiveid
group by m1.userid,m2.userid
order by m1.userid

推荐电影
上面帮我找到一篇符合自己口味的评论,下面我们要讨论一下如何推荐商品.我们当然可以有以下简单而武断的处理方式:从和自己相似度最高的用户看过的且评价很高的电影中给出推荐.如果这个相似度很高的有什么特殊的爱好,推荐的结果就不能让人满意了:比如有一群和我一样喜欢香港武侠电影的人,通过我的电影列表给他们推荐电影,大部分情况下的推荐都是准确的,可是我却给《金鸡》满分.或者有一部电影很好这个用户却没有评价,也会被漏掉:比如《导火线》我就是因为讨厌其中的一个女演员没有看,在给其他用户推荐的过程中,这部电影就可能漏掉.
我们明确一下上面算法的问题:1.无法处理"夸大值"2.评价缺失导致无法推荐.下面我们集中解决这两个问题.首先我们完善一下数据:

下面是用户对新增的四部电影的评分:
insert into moive_level values('2','469','9');
insert into moive_level values('2','476','9');
insert into moive_level values('2','495','7');
insert into moive_level values('2','574','5');
insert into moive_level values('3','469','10');
insert into moive_level values('3','476','3');
insert into moive_level values('3','495','4');
insert into moive_level values('3','574','8');
insert into moive_level values('4','469','5');
insert into moive_level values('4','476','2');
insert into moive_level values('4','495','8');
insert into moive_level values('4','574','6');
insert into moive_level values('5','469','10');
insert into moive_level values('5','476','8');
insert into moive_level values('5','495','8');
insert into moive_level values('5','574','10');
于是问题就被具体化成:
"用户Lily,kitty,Tom,Tank分别对新增的四部电影做了评分,根据他们的评分为用户Zen推荐一部电影"
我们的整体思路是:计算出这四部电影的加权评分,然后按照先后排名,最前面的那个就是我们要推荐给Zen的.
加权的权重参数我们采用已经运算出来的皮尔逊系数.问题还是需要进一步的简化:我们如何计算电影尖峰时刻2的加权评分?
我们把Lily,kitty,Tom,Tank对这部电影的评分乘以他们和Zen的相似度然后求和,这样的结果就是越相似的人对这个结果的影响越大.其实这里我们已经可以算出四部电影的甲醛评分并做排序了.检查我们的目标评价:"缺失导致无法推荐"还没有解决,这个问题换一种角度可以表述成:"一部电影被更多人评论过,这一事实应该影响到结果".
修正策略就是我们把加权评分总和除以所有对这部电影评分过的评分者与Zen的相似度总和.
 --计算Rxy相似度之和DECLARE @SRxy float;select @SRxy=Sum(Rxy) From(select m1.userid userA,m2.userid userB, (sum(m1.level*m2.level)-sum(m1.level)*sum(m2.level)/10) /sqrt((sum(power(m1.level,2))-power(sum(m1.level),2)/10)*(sum(power(m2.level,2))-power(sum(m2.level),2)/10)) Rxy From moive_level m1,moive_level m2 where m1.userid<> m2.userid and m1.userid=1 and m1.moiveid=m2.moiveid group by m1.userid,m2.userid) Tempselect @Srxy --计算一部新的电影所有他人评价值的加权平均select sum(t.sim)/@Srxyfrom (--下面计算的是用户Zen(userid=1)与其他用户的相似度系数,我们使用的是皮尔逊相似度算法select moive_level.*,per.Rxy,Rxy*moive_level.Level Sim From (select m1.userid userA,m2.userid userB, (sum(m1.level*m2.level)-sum(m1.level)*sum(m2.level)/10) /sqrt((sum(power(m1.level,2))-power(sum(m1.level),2)/10)*(sum(power(m2.level,2))-power(sum(m2.level),2)/10)) Rxy From moive_level m1,moive_level m2 where m1.userid<> m2.userid and m1.userid=1 and m1.moiveid=m2.moiveid group by m1.userid,m2.userid ) Per,moive_level where per.userB=moive_level.userid and moive_level.moiveid=469 )T
--计算Rxy相似度之和DECLARE @SRxy float;select @SRxy=Sum(Rxy) From(select m1.userid userA,m2.userid userB, (sum(m1.level*m2.level)-sum(m1.level)*sum(m2.level)/10) /sqrt((sum(power(m1.level,2))-power(sum(m1.level),2)/10)*(sum(power(m2.level,2))-power(sum(m2.level),2)/10)) Rxy From moive_level m1,moive_level m2 where m1.userid<> m2.userid and m1.userid=1 and m1.moiveid=m2.moiveid group by m1.userid,m2.userid) Tempselect @Srxy --计算一部新的电影所有他人评价值的加权平均select sum(t.sim)/@Srxyfrom (--下面计算的是用户Zen(userid=1)与其他用户的相似度系数,我们使用的是皮尔逊相似度算法select moive_level.*,per.Rxy,Rxy*moive_level.Level Sim From (select m1.userid userA,m2.userid userB, (sum(m1.level*m2.level)-sum(m1.level)*sum(m2.level)/10) /sqrt((sum(power(m1.level,2))-power(sum(m1.level),2)/10)*(sum(power(m2.level,2))-power(sum(m2.level),2)/10)) Rxy From moive_level m1,moive_level m2 where m1.userid<> m2.userid and m1.userid=1 and m1.moiveid=m2.moiveid group by m1.userid,m2.userid ) Per,moive_level where per.userB=moive_level.userid and moive_level.moiveid=469 )T 将上面的运算抽取成为存储过程:
SET QUOTED_IDENTIFIER OFF GOSET ANSI_NULLS OFF GO ALTER PROCEDURE [dbo].[RecommendMoiveForZen] (@mid int) AS --计算Rxy相似度之和DECLARE @SRxy float;select @SRxy=Sum(Rxy) From(select m1.userid userA,m2.userid userB, (sum(m1.level*m2.level)-sum(m1.level)*sum(m2.level)/10) /sqrt((sum(power(m1.level,2))-power(sum(m1.level),2)/10)*(sum(power(m2.level,2))-power(sum(m2.level),2)/10)) Rxy From moive_level m1,moive_level m2 where m1.userid<> m2.userid and m1.userid=1 and m1.moiveid=m2.moiveid group by m1.userid,m2.userid) Temp--select @Srxy--计算对一部新的电影,所有他人评价值的加权平均select moive.Name,sum(t.sim)/@Srxy [Level]from (--下面计算的是用户Zen(userid=1)与其他用户的相似度系数,我们使用的是皮尔逊相似度算法select moive_level.moiveid,Rxy*moive_level.Level Sim From (select m1.userid userA,m2.userid userB, (sum(m1.level*m2.level)-sum(m1.level)*sum(m2.level)/10) /sqrt((sum(power(m1.level,2))-power(sum(m1.level),2)/10)*(sum(power(m2.level,2))-power(sum(m2.level),2)/10)) Rxy From moive_level m1,moive_level m2 where m1.userid<> m2.userid and m1.userid=1 and m1.moiveid=m2.moiveid group by m1.userid,m2.userid ) Per,moive_level where per.userB=moive_level.userid and moive_level.moiveid=@mid )T,moive where T.moiveid=moive.idgroup by moive.name GOSET QUOTED_IDENTIFIER OFF GOSET ANSI_NULLS ON GO
执行存储过程:
DECLARE @RC intDECLARE @mid int-- Set parameter valuesEXEC @RC = [U-M].[dbo].[RecommendMoiveForZen] 469EXEC @RC = [U-M].[dbo].[RecommendMoiveForZen] 476EXEC @RC = [U-M].[dbo].[RecommendMoiveForZen] 495 EXEC @RC = [U-M].[dbo].[RecommendMoiveForZen] 574

现在我们得到了一个经过排名的影片列表,后面是Zen的可能评分.理论上我们已经完成了任务,
可以给Zen推荐电影了.事实上,真实环境中的推荐要难的多,我们这里只是像做数学题一样得出了一个结果,忽略掉的种种因素,那些干扰因素有可能成为真正影响推荐的关键.
电影之间的相似度怎么运算呢?思路很简单:那些人喜欢某一电影,这些人还喜欢什么电影?这些电影之间就存在相似度.实现起来更简单,只要把考察的对象"电影"和"用户"交换一下位置就可以了,我们以欧几里德距离为例:
GO
SET ANSI_NULLS OFF
GO
ALTER PROCEDURE [ dbo ] . [ EuclideanDistanceForMoive ]
@moiveidA int ,
@moiveidB int
AS
select * From moive where id = @moiveidA ;
select * From moive where id = @moiveidB ;
select @moiveidA MoiveA, @moiveidB MoiveB, sqrt ( sum (result)) Distance
From
(
select m1. * , power (m1. level - m2. level , 2 ) result From moive_level m1,moive_level m2
where m1.moiveid = @moiveidA and m2.moiveid = @moiveidB and m1.userid = m2.userid
)T
GO
SET QUOTED_IDENTIFIER OFF
GO
SET ANSI_NULLS ON
GO
DECLARE @RC int
-- Set parameter values
EXEC @RC = [ U-M ] . [ dbo ] . [ EuclideanDistanceForMoive ] 268 , 48
EXEC @RC = [ U-M ] . [ dbo ] . [ EuclideanDistanceForMoive ] 7 , 165
EXEC @RC = [ U-M ] . [ dbo ] . [ EuclideanDistanceForMoive ] 42 , 178
EXEC @RC = [ U-M ] . [ dbo ] . [ EuclideanDistanceForMoive ] 48 , 314
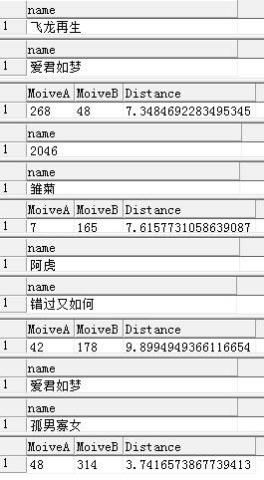
结果还是相当靠谱的,同为香港都市爱情喜剧的《爱君如梦》和《孤男寡女》距离最近.
一组量很小的数据可以演绎出这么多的有意思的东西,真的是"横看成岭侧成峰" :)
P.S
小小的问题,我使用SQL语句完成实践,而SQL语句擅长的是关系表达和集合运算,复杂的数学运算用SQL实现不是什么好主意.上面的文章中你可以发现整个的SQL代码即使加上注释也是缺乏可读性的.而且原作者使用Python简洁明快的实现一个算法太让我手痒了,这次之后,所有的代码将迁移到Python.